StableDiffusion2 Image to Text
1.0.0
ที่เก็บนี้มีรหัส Python เพื่อปรับแต่งแบบจำลองที่สามารถทำนายการแจ้งเตือนและ/หรือฝังตัวจากภาพที่สร้างขึ้น กระบวนการที่รู้กันทั่วไปคือการสร้างภาพจากข้อความที่กำหนดเป็นกระบวนการที่ได้รับความนิยมสำหรับงานที่ได้รับความนิยมอย่างมาก อย่างไรก็ตาม repo นี้ มุ่งเน้นไปที่กระบวนการย้อนกลับซึ่งทำนายข้อความที่ให้ข้อความเพื่อสร้างภาพ เมื่อได้รับชุดข้อมูลเป็นคู่ภาพแจ้งรุ่นต่อไปนี้ได้รับการปรับแต่งเพื่อทำนายข้อความหรือข้อความฝังตัว:
ด้านล่างนี้เป็นตัวอย่างคู่ที่มีภาพแจ้งสำหรับ SD2 วัตถุประสงค์ของงานนี้คือการทำนายข้อความแจ้งที่ใช้ในการสร้างภาพ กำหนดชุดข้อมูลเช่นด้านล่างรหัสภายใน repo นี้ สามารถใช้ในการปรับแต่งโมเดลต่าง ๆ เพื่อทำนายข้อความพร้อมข้อความเมื่อได้รับภาพที่สร้างขึ้น
fat rabbits with oranges, photograph iphone, trendinga hyper realistic oil painting of Yoda eating cheese, 4Ka pencil drawing portrait of an anthropomorphic mouse adventurer holding a sword. by pen tacular 


งานในที่เก็บนี้เป็นส่วนหนึ่งของการแพร่กระจายที่มั่นคงของ Kaggle - ภาพเพื่อแจ้งการแข่งขัน นี่คือรหัสที่ฉันสร้างขึ้นในระหว่างการแข่งขันและสามารถได้รับ 5% สูงสุดในการแข่งขัน
การฝึกอบรมแบบจำลองเหล่านี้และการสร้างภาพด้วยการแพร่กระจายที่มีเสถียรภาพ 2 เป็นทรัพยากรที่เข้มข้นและสั่งการ GPU สามารถใช้มาตรการเพื่อช่วยเร่งการสร้างภาพเช่น:
การใช้ขั้นตอนเหล่านี้ด้วย RTX 3090 จะสร้างภาพที่ประมาณ 2S/IMAGE
ชุดข้อมูล Prompt-Image Pair ถูกดาวน์โหลดผ่าน URL โดยใช้แพ็คเกจ IMG2Dataset ตัวอย่างบางส่วนของชุดข้อมูล URL ออนไลน์คือ:
ชุดข้อมูล Prompt-Image คู่ที่กำหนดเองถูกสร้างขึ้นโดยใช้การแพร่กระจายที่เสถียร 2 ฉันขอแนะนำให้ผู้ใช้ที่สนใจในการสร้างชุดข้อมูลของตัวเองด้วยการแพร่กระจายที่เสถียร 2 ทำตามคำแนะนำที่ได้รับการปรับปรุงโดยทั่วไปที่ความเสถียรการแพร่กระจายเวอร์ชัน 2
คู่ภาพแจ้งที่จำเป็นต้องจัดรูปแบบตามแบบจำลองที่พวกเขาจะปรับแต่งได้ดี อ้างถึง ./notebooks/data-format-train-val.ipynb ซึ่งแสดงวิธีการจัดรูปแบบชุดข้อมูลต่างๆ
ชุดข้อมูลคู่อิมเมจภาพบุคคลออนไลน์จำนวนมากมีพรอมต์ที่มีความคล้ายคลึงกันสูงและสิ่งนี้สามารถทำให้โมเดลเรียนรู้การแจ้งเตือนที่เกิดขึ้นโดยทั่วไปและไม่ได้ทำงานเช่นเดียวกับข้อความที่มีข้อความที่หลากหลาย ดังนั้นการแจ้งเตือนที่คล้ายกันพวกเขาถูกลบออกโดยใช้การจัดทำดัชนีความคล้ายคลึงกันของโคไซน์ GPU หรือการค้นหาความคล้ายคลึงกัน อ้างถึง ./utils/filt_embeds.py ซึ่งมีรหัสในการจัดทำดัชนีและตัวกรองการฝังตัวกรองอย่างรวดเร็ว
กระบวนการนี้ดำเนินการบน GPU ซึ่งใช้ประโยชน์จากห้องสมุด FAISS FAISS เป็นห้องสมุดสำหรับการค้นหาความคล้ายคลึงกันอย่างมีประสิทธิภาพและการจัดกลุ่มของเวกเตอร์หนาแน่น มันมีอัลกอริทึมที่ค้นหาในชุดของเวกเตอร์ทุกขนาดถึงสิ่งที่อาจไม่พอดีกับ RAM
# Create an IndexFlatIP index using the Faiss library
# The term 'IP' represents the Inner Product,
# which is equivalent to cosine similarity as it involves taking the dot product of normalized vectors.
resources = faiss . StandardGpuResources ()
index = faiss . IndexIVFFlat ( faiss . IndexFlatIP ( 384 ), 384 , 5 , faiss . METRIC_INNER_PRODUCT )
gpu_index = faiss . index_cpu_to_gpu ( resources , 0 , index )
# Normalize the input vector and add it to the IndexFlatIP
gpu_index . train ( F . normalize ( vector ). cpu (). numpy ())
gpu_index . add ( F . normalize ( vector ). cpu (). numpy ()) Coca Architecture เป็นวิธีการเข้ารหัสใหม่ที่สร้างภาพและการฝังตัวข้อความและการแสดงข้อความหลายรูปแบบและการเป็นตัวแทนหลายรูปแบบทำให้มีความยืดหยุ่นเพียงพอที่จะใช้งานได้โดยตรงสำหรับงานดาวน์สตรีมทุกประเภท โดยเฉพาะ Coca บรรลุผลที่ล้ำสมัยในชุดของการมองเห็นและงานภาษาวิสัยทัศน์ซึ่งประกอบไปด้วยการจดจำวิสัยทัศน์การจัดตำแหน่งข้ามรูปแบบและความเข้าใจหลายรูปแบบ นอกจากนี้ยังเรียนรู้การเป็นตัวแทนทั่วไปสูงเพื่อให้สามารถทำงานได้ดีหรือดีกว่าโมเดลที่ปรับแต่งอย่างสมบูรณ์ด้วยการเรียนรู้แบบไม่มีการยิงหรือเข้ารหัสแช่แข็ง การปรับแต่งได้ดำเนินการตามคำแนะนำจากที่นี่ สถาปัตยกรรม Coca แสดงอยู่ด้านล่างและนำมาจากแหล่งที่มา 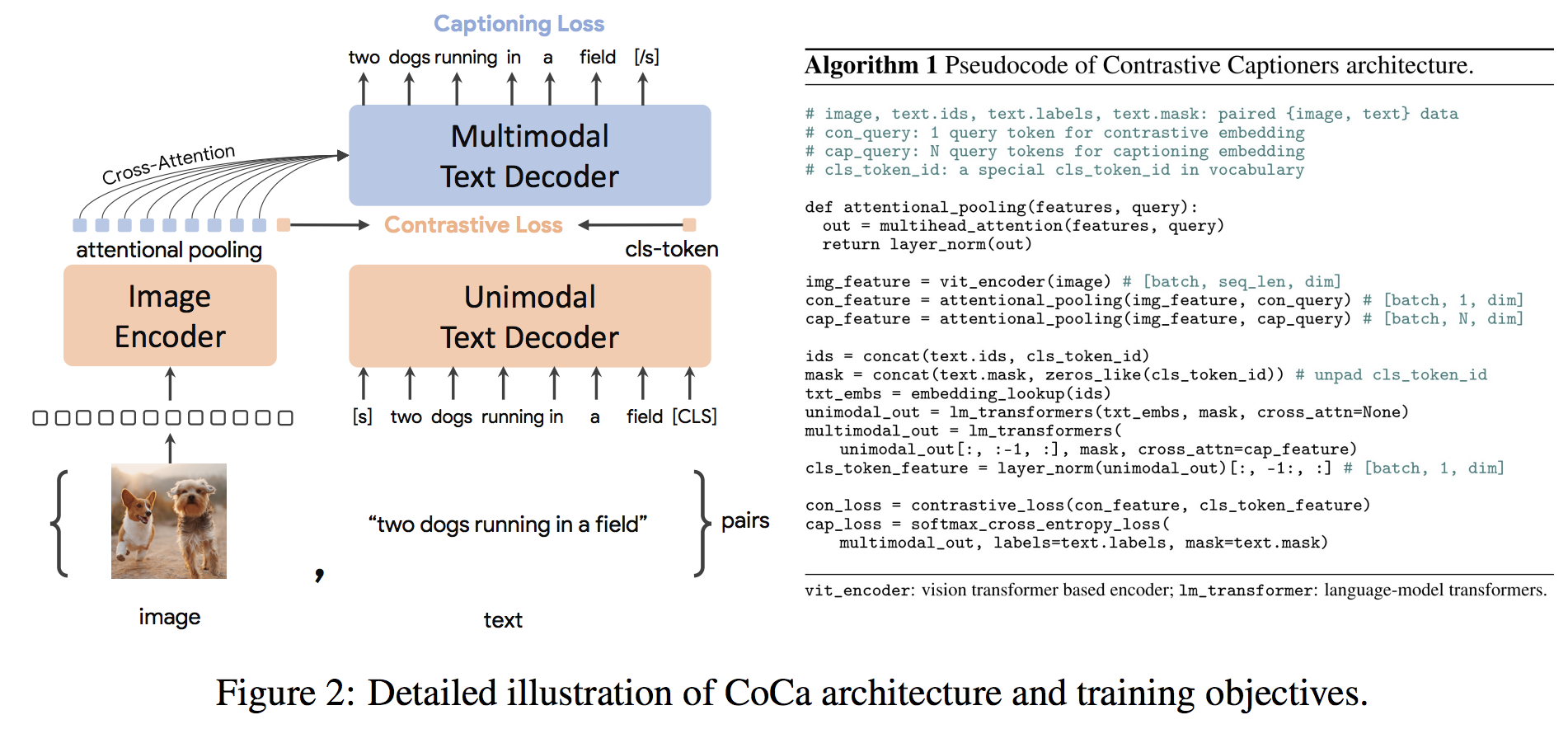
รหัส Python เพื่อปรับแต่ง Coca อยู่ใน ./scripts/train_COCA.py และคำสั่ง bash ได้รับด้านล่าง:
python3 -m training.main
--dataset-type " csv "
--train-data " ./kaggle/diffusiondb_ds2_ds3-2000_Train_TRUNNone_filts_COCA.csv "
--warmup 10000
--batch-size 16
--lr 1e-05
--wd 0.1
--epochs 1
--workers 8
--model coca_ViT-L-14
--pretrained " ./kaggle/input/open-clip-models/mscoco_finetuned_CoCa-ViT-L-14-laion2B-s13B-b90k.bin "
--report-to " wandb "
--wandb-project-name " StableDiffusion "
--coca-contrastive-loss-weight 0
--coca-caption-loss-weight 1
--log-every-n-steps 1000
--seed 42 คลิป (การฝึกอบรมภาษาแบบภาษาที่ตัดกัน) เป็นเครือข่ายประสาทที่ได้รับการฝึกฝนเกี่ยวกับคู่ (ภาพข้อความ) ที่หลากหลาย มันสามารถได้รับคำแนะนำในภาษาธรรมชาติเพื่อทำนายตัวอย่างข้อความที่เกี่ยวข้องมากที่สุดโดยไม่ได้รับภาพโดยไม่ต้องปรับให้เหมาะสมสำหรับงานเช่นเดียวกับความสามารถที่เป็นศูนย์-ช็อตของ GPT-2 และ 3 สถาปัตยกรรมคลิปจะแสดงในภาพด้านล่างและนำมาจากแหล่งที่มา 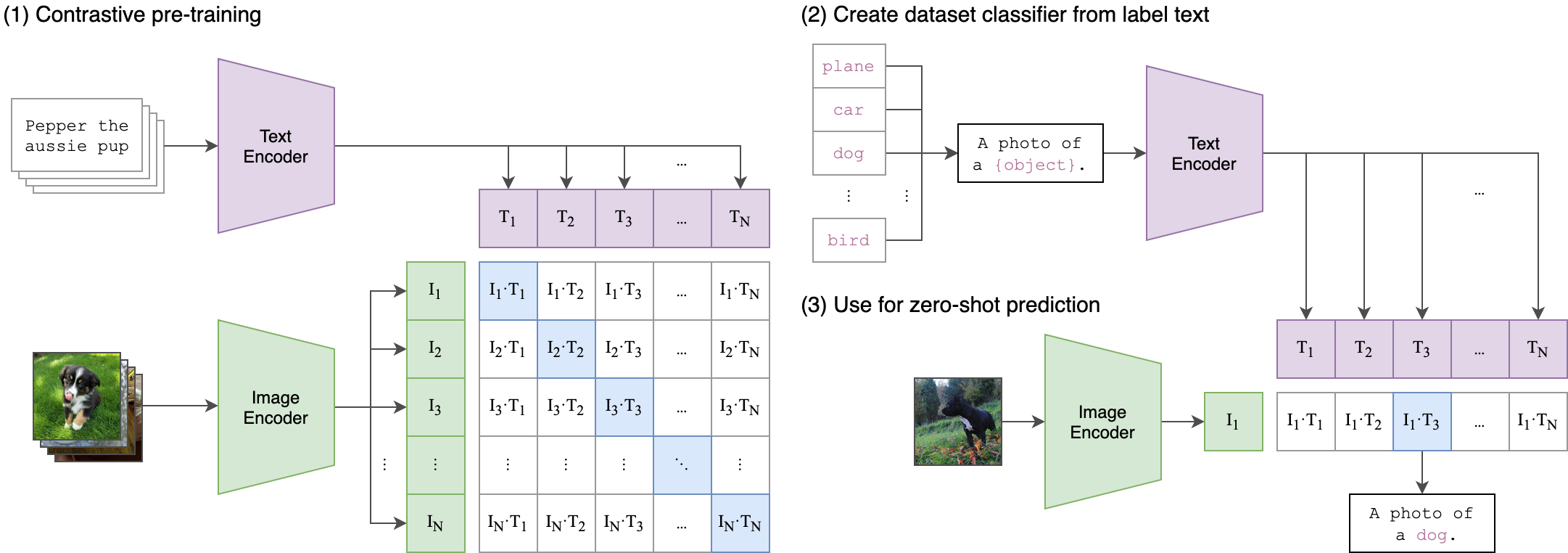
ตัวเข้ารหัสภาพวิสัยทัศน์ (VIT) จากคลิปถูกปรับในที่เก็บนี้ สคริปต์ Python ต่อไปนี้แสดงให้เห็นถึงวิธีการปรับแต่ง Vit:
class Net ( nn . Module ):
def __init__ ( self , model_name ):
super ( Net , self ). __init__ ()
clip = AutoModel . from_pretrained ( model_name )
self . vision = clip . vision_model
self . fc = nn . Linear ( 1024 , 384 )
self . dropout = nn . Dropout ( 0.25 )
def forward ( self , x ):
out = self . vision ( x )[ 'pooler_output' ]
return self . fc ( out )

