recsys_pipeline
1.0.0
英語| 中文
以著名的Movielens數據集為例,我們將介紹從離線到在線的推薦系統管道,所有操作都可以在單個筆記本電腦上執行。儘管使用了多個組件,但必須注意,所有內容都包含在康達(Conda)和碼頭(Docker)內,從而確保對當地環境沒有影響。
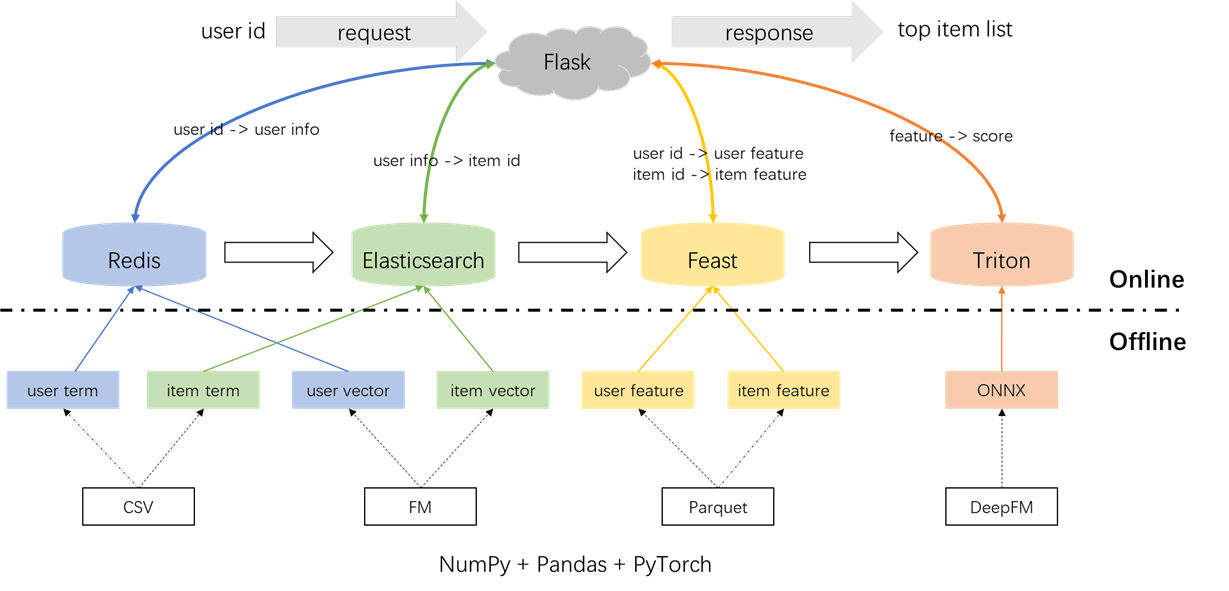
建議系統的整體體系結構如下所示。現在,我們將介紹三個階段的召回和排名模塊的開發和部署流程:離線,離線到線和在線。
conda create -n rsppl python=3.8
conda activate rsppl
conda install --file requirements.txt --channel anaconda --channel conda-forge cd offline/preprocess/
python s1_data_split.py
python s2_term_trans.py標籤,樣本和功能的預處理:
重要的是要突出顯示在s2_term_trans.py文件中加入時間點的概念。具體來說,在生成離線培訓樣本(IMP_TERM.PKL)期間,應使用最接近當前時刻的動作時間。此後使用功能會引入功能洩漏,而使用與當前時間相距明顯遙遠的功能會導致離線和在線之間的不一致。相比之下,最新功能應用於在線服務(user_term.pkl和item_term.pkl)。
cd offline/recall/
python s1_term_recall.py
python s2_vector_recall.py術語召回:此組件利用用戶在指定的時間窗口中與項目('類型)的過去交互,以將用戶首選項與項目匹配。這些術語將在稍後將其加載到Redis和Elasticsearch中。
向量回憶:在此組件中,使用FM(分分計算機),僅利用用戶ID和項目ID作為功能。所得的AUC(曲線下的區域)= 0.8081。訓練階段完成後,從模型檢查點提取了用戶和項目向量,並將加載到Redis和Elasticsearch中以進行後續利用。
cd offline/rank/
python s1_feature_engi.py
python s2_model_train.py總共有59個功能,其中包括三種類型:一hot功能(例如UserID,itemID,性別等),多熱功能(類型)和密集的功能(歷史行為統計)。
採用的排名模型是DEEPFM,AUC為0.8206。儘管Pytorch-FM是用於基於FM的算法的優雅軟件包,但它具有兩個限制:1。它僅支持稀疏功能,缺乏對密集功能的支持。 2。所有稀疏特徵都具有相同的維度,這違反了直覺,即“ ID嵌入應具有高維度,而側面信息嵌入應具有低維度。”。為了解決這些約束,我們對源代碼進行了修改,為稀疏功能提供了支持,並為稀疏特徵的嵌入尺寸變化。此外,注意到,深層嵌入模塊對模型性能產生負面影響,這促使其從模型中刪除。結果,當前的模型結構主要由與密度MLP集成的稀疏FM模塊組成,它不是常規的DEEPFM。
為了防止對當地環境的任何影響,Redis,Elasticsearch,Feast和Triton都在Docker容器中使用。要繼續進行,請確保將Docker安裝在筆記本電腦上,然後執行以下命令以下載相應的Docker映像。
docker pull redis:6.0.0
docker pull elasticsearch:8.8.0
docker pull feastdev/feature-server:0.31.0
docker pull nvcr.io/nvidia/tritonserver:20.12-py3Redis被用作數據庫,用於存儲召回所需的用戶信息。
啟動Redis容器。
docker run --name redis -p 6379:6379 -d redis:6.0.0該過程涉及加載用戶的術語,向量和過濾到redis。術語和矢量數據是在第1.2節中生成的,而過濾器與用戶以前與之交互的項目有關。在生成建議時,這些過濾項目被排除在外。
加載數據後,將通過檢查示例用戶的數據來執行驗證步驟。成功的驗證將由下面顯示的輸出表示。
cd offline_to_online/recall/
python s1_user_to_redis.py
Elasticsearch被用來為項目創建倒索引和向量索引。 Elasticsearch的基本用例最初是為搜索應用程序而設計的,涉及使用單詞檢索文檔。在推薦系統的背景下,我們將項目視為文檔及其術語,例如電影類型,作為單詞。這使我們可以使用Elasticsearch根據這些術語來檢索項目。這個概念與倒置索引的概念保持一致,這使Elasticsearch成為推薦系統中術語召回的有價值的工具。對於矢量召回,一種常用的工具是Facebook的開源faiss。但是,為了易於集成,我們選擇利用Elasticsearch的向量檢索功能。 Elasticsearch自第7版以來一直支持向量檢索,並且自版本8版以來近似K-Nearest鄰居(ANN)檢索。在此項目中,我們安裝了8(或更高)的Elasticsearch版本。之所以做出選擇,是因為精確的KNN檢索通常無法滿足在線系統的低延遲要求。
啟動Elasticsearch容器,並通過執行以下命令輸入其內部終端。
docker run --name es8 -p 9200:9200 -it elasticsearch:8.8.0複製終端輸出中顯示的密碼(如下所示),並將其粘貼為data_exchange_center/startants.py文件中的es_key的值。此步驟是必要的,因為Elasticsearch已從版本8開始實現密碼身份驗證要求。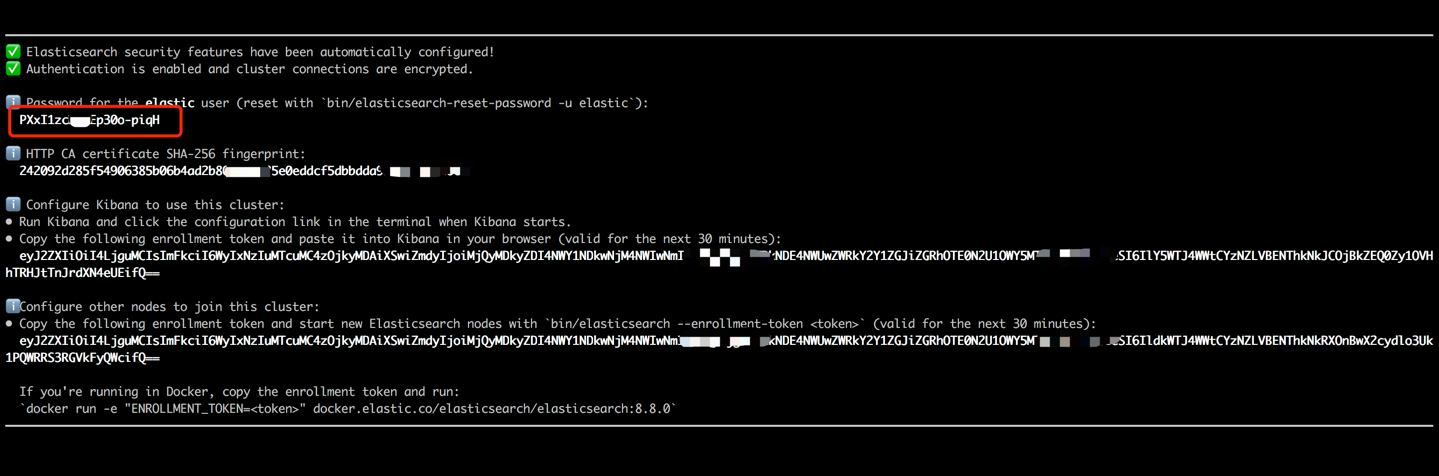
粘貼密碼後,使用CTRL+C(或命令+C)鍵盤快捷鍵退出內部終端。此操作還將停止容器,因此我們需要重新啟動Elasticsearch容器,並確保其作為後續步驟的一部分在後台運行。
docker start es8加載項目項以創建術語索引並加載項目向量以創建向量索引。在工業環境中,這兩個索引通常分開以提高性能和靈活性。但是,為了簡單,我們將它們組合成一個索引。
在數據加載過程之後,將通過檢查示例項目的項和向量來執行驗證步驟。成功的驗證將由下面顯示的輸出表示。
cd offline_to_online/recall/
python s2_item_to_es.py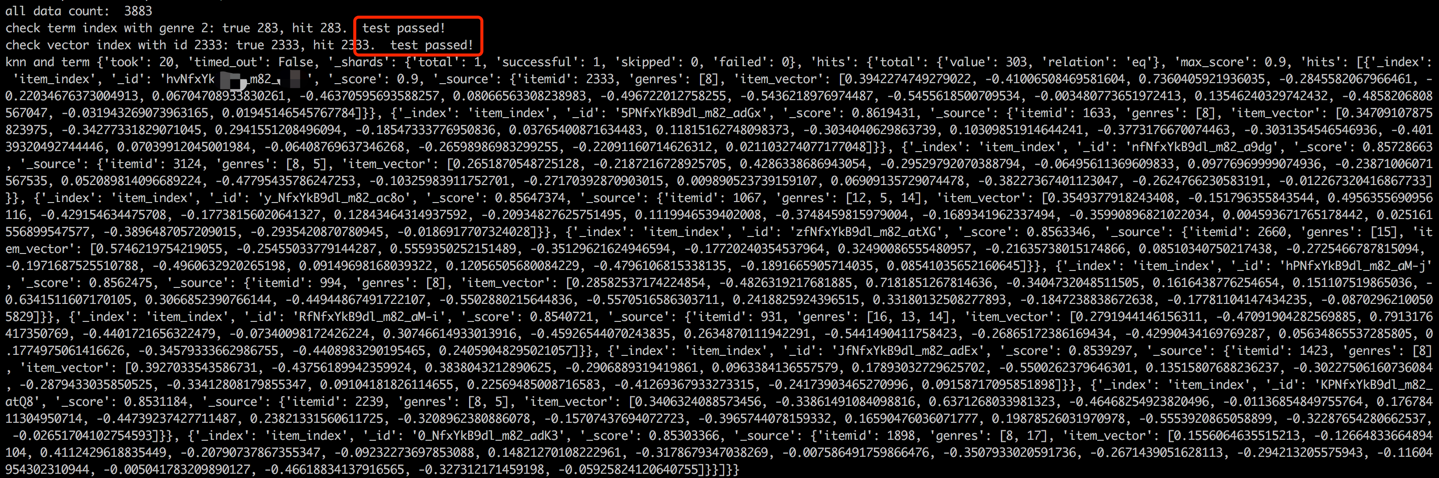
盛宴是開拓開源商店的開創性,在該領域具有歷史意義。盛宴包括離線和在線組件。離線組件主要促進了時間點加入。但是,由於我們自己管理了熊貓的時間點,因此無需使用盛宴的離線功能。相反,我們將盛宴用作在線功能商店。不使用盛宴進行點數的原因背後的原因在於,盛宴主要提供功能功能,並且缺乏功能工程功能(儘管它在最近的版本中引入了一些基本轉換)。大多數公司都喜歡具有更強大功能的定制功能引擎。因此,無需在學習盛宴的離線使用方面投入太多努力。使用更多的通用工具(例如Pandas或Spark)進行功能處理和利用盛宴更為實用,僅作為離線和在線之間運輸功能的組成部分。
將功能文件從CSV轉換為Parquet格式,以滿足盛宴的要求。
cd offline_to_online/rank/
python s1_feature_to_feast.py打開一個新的終端(稱為終端2),以6566作為HTTP端口啟動盛宴容器,並通過執行以下命令進入其內部終端。
cd data_exchange_center/online/feast
docker run --rm --name feast-server --entrypoint " bash " -v $( pwd ) :/home/hs -p 6566:6566 -it feastdev/feature-server:0.31.0在盛宴容器的內部終端中執行以下命令。
# Enter the config directory
cd /home/hs/ml/feature_repo
# Initialize the feature store from config files (read parquet to build database)
feast apply
# Load features from offline to online (defaults to sqlite, with options like Redis available)
feast materialize-incremental " $( date + ' %Y-%m-%d %H:%M:%S ' ) "
# Start the feature server
feast serve -h 0.0.0.0 -p 6566完成所有步驟後,將顯示以下輸出。
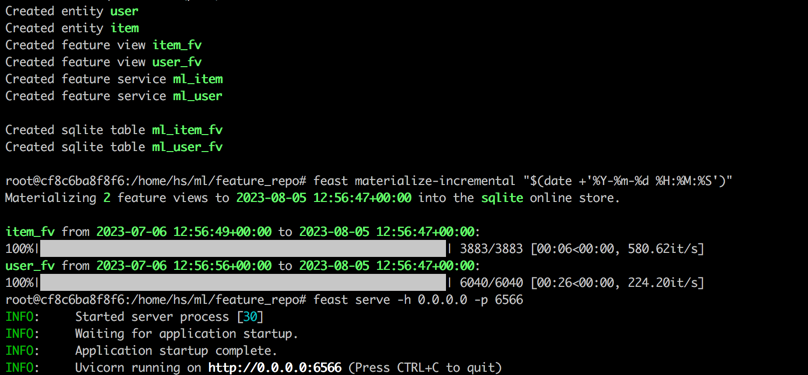
返回終端1,執行以下命令,以測試盛宴是否正確使用。如果成功的話,將打印響應JSON字符串。
curl -X POST
" http://localhost:6566/get-online-features "
-d ' {
"feature_service": "ml_item",
"entities": {
"itemid": [1,3,5]
}
} ' Triton(Triton推理服務器)是由Nvidia開發的開源推理服務引擎。 Triton推理服務器為各種框架提供了支持,例如Tensorflow,Pytorch,OnNX和其他選項,使其成為模型服務的絕佳選擇。儘管Triton是由NVIDIA開發的,但它的用途足夠多,可以與CPU一起使用,並提供了靈活性。雖然更普遍的行業解決方案涉及張量 - > SavedModel-> TensorFlow服務,但由於其在不同框架之間切換方面的適應性,Triton卻越來越受歡迎。因此,在這個項目中,我們採用了使用Pytorch-> onnx-> Triton Server的管道。
將Pytorch模型轉換為ONNX格式。
cd offline_to_online/rank/
python s2_model_to_triton.py打開一個新的終端(稱為終端3),通過執行以下命令,以8000作為HTTP端口的Triton容器作為HTTP端口和8001作為GRPC端口。
cd data_exchange_center/online/triton
docker run --rm -p8000:8000 -p8001:8001 -p8002:8002 -v $( pwd ) /:/models/ nvcr.io/nvidia/tritonserver:20.12-py3 tritonserver --model-repository=/models/
返回終端1,運行腳本以測試離線和在線預測分數之間的一致性。此步驟將有助於確保推薦系統的可靠性。
cd offline_to_online/rank/
python s3_check_offline_and_online.py如下所示,離線和在線分數相同,表明離線和在線之間的一致性。

在工業環境中,工程師通常選擇Java + Springboot或Go + Gin作為推薦系統的後端。但是,為了使集成容易,在此項目中,使用Python +燒瓶。值得注意的是,Python有幾個Web框架,包括Django,Flask,Fastapi和Tornado,所有這些都能夠將RESTAPI請求路由到處理功能。這些框架中的任何一個都可以滿足我們的要求,該項目隨機選擇了燒瓶。
打開一個新的終端(稱為終端4),通過執行以下命令,以5000作為HTTP端口啟動燒瓶Web服務器。
conda activate rsppl
cd online/main
flask --app s1_server.py run --host=0.0.0.0
返回終端1,並通過從客戶端調用推薦服務進行測試(在此上下文中,客戶介紹了調用建議服務而不是用戶設備的上游服務)。結果將以JSON格式返回,並顯示前50個項目ID。隨後,下游服務可以使用這些項目ID檢索其相應的屬性,然後將其提供給客戶端(在此上下文中,用戶設備)。這完成了完整的建議流。
cd online/main
python s2_client.py


