recsys_pipeline
1.0.0
الإنجليزية | 中文
باستخدام مجموعة بيانات Movielens المعروفة كمثال ، سنقدم خط أنابيب نظام التوصية من دون اتصال بالإنترنت إلى الإنترنت ، مع جميع العمليات على كمبيوتر محمول واحد. على الرغم من استخدام مكونات متعددة ، من المهم أن نلاحظ أن كل شيء موجود في كوندا و Docker ، مما يضمن عدم التأثير على البيئة المحلية.
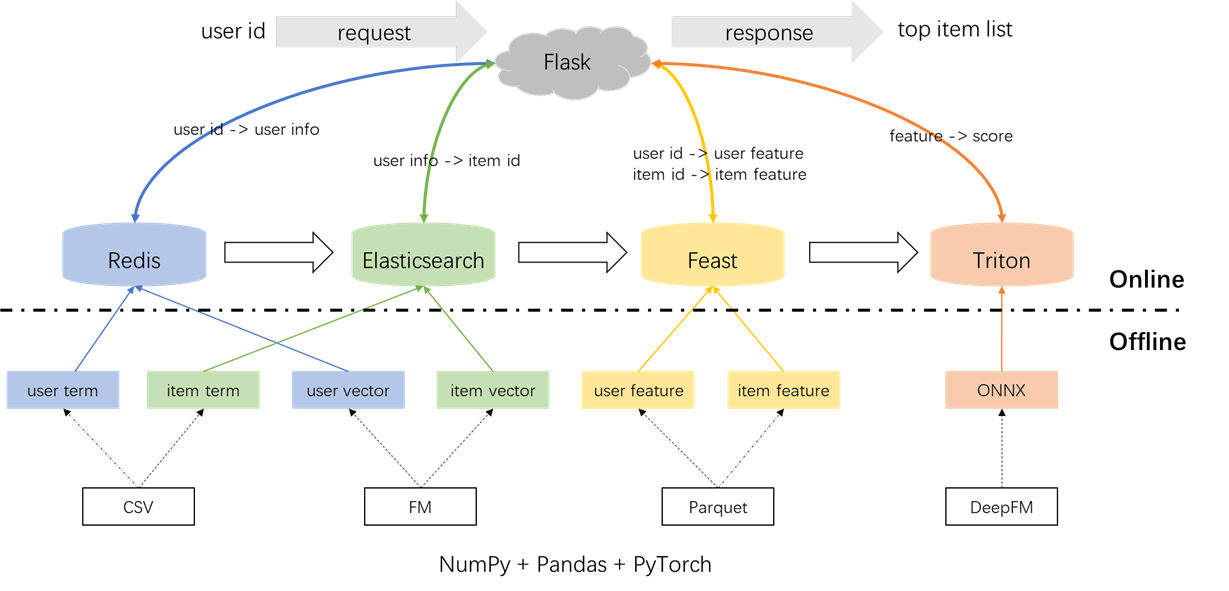
تم توضيح العمارة العامة لنظام التوصية أدناه. الآن سنقدم عمليات التطوير والنشر للوحدات النمطية للاستدعاء والتصنيف عبر ثلاث مراحل: دون اتصال بالإنترنت ، غير متصل بالإنترنت ، وعبر الإنترنت.
conda create -n rsppl python=3.8
conda activate rsppl
conda install --file requirements.txt --channel anaconda --channel conda-forge cd offline/preprocess/
python s1_data_split.py
python s2_term_trans.pyالمعالجة المسبقة للعلامات والعينات والميزات:
من المهم تسليط الضوء على مفهوم الوصلات في الوقت في ملف S2_Term_Trans.py. على وجه التحديد ، أثناء توليد عينات التدريب غير المتصلة بالإنترنت (Imp_term.pkl) ، يجب استخدام ما يصل إلى وقت الإجراء الأقرب إلى اللحظة الحالية. إن استخدام الميزات بعد هذه النقطة من شأنه أن يقدم تسرب الميزات ، في حين أن استخدام الميزات البعيدة بشكل كبير في الوقت الحاضر سيؤدي إلى عدم تناسق بين غير متصل عبر الإنترنت وعبر الإنترنت. في المقابل ، يجب نشر أحدث الميزات للخدمة عبر الإنترنت (user_term.pkl و item_term.pkl).
cd offline/recall/
python s1_term_recall.py
python s2_vector_recall.pyاستدعاء المصطلح: يستخدم هذا المكون التفاعلات السابقة للمستخدم مع العناصر ('الأنواع) ضمن نافذة زمنية محددة لمطابقة تفضيلات المستخدم مع العناصر. سيتم تحميل هذه المصطلحات في redis و elasticsearch في وقت لاحق.
استدعاء المتجه: في هذا المكون ، يتم استخدام FM (آلات العوامل) ، باستخدام معرف المستخدم ومعرف العنصر فقط كميزات. AUC الناتجة (المساحة تحت المنحنى) = 0.8081. عند الانتهاء من مرحلة التدريب ، يتم استخراج متجهات المستخدم والعناصر من نقطة تفتيش النموذج وسيتم تحميلها في redis و elasticsearch للاستخدام اللاحق.
cd offline/rank/
python s1_feature_engi.py
python s2_model_train.pyفي المجموع ، هناك 59 ميزات تشمل ثلاثة أنواع: ميزات واحدة (مثل userid ، itemid ، الجنس ، إلخ) ، الميزات متعددة الحمل (الأنواع) ، والميزات الكثيفة (الإحصاءات السلوكية التاريخية).
نموذج الترتيب المستخدم هو DeepFM ، حيث حقق AUC 0.8206. على الرغم من أن Pytorch-FM عبارة عن حزمة أنيقة للخوارزميات المستندة إلى FM ، إلا أنها تحتوي على قيودان: 1. إنها تدعم بشكل حصري الميزات المتفرقة وتفتقر إلى الدعم للميزات الكثيفة. 2. جميع الميزات المتفرقة تشترك في نفس البعد ، الذي ينتهك الحدس الذي "يجب أن تكون تضمينات المعرف عالية الأبعاد ، في حين يجب أن تكون تضمينات المعلومات الجانبية منخفضة الأبعاد.". لمعالجة هذه القيود ، قمنا بإجراء تعديلات على الكود المصدري ، مما يتيح الدعم لكل من الميزات الكثيفة وأبعاد التضمين المتنوعة للميزات المتفرقة. بالإضافة إلى ذلك ، لوحظ أن وحدة التضمين العميقة تؤثر سلبًا على أداء النموذج ، مما دفع إزالته من النموذج. نتيجة لذلك ، يتكون بنية النموذج الحالية في المقام الأول من وحدة FM متناثرة مدمجة مع MLP كثيف ، فهي ليست DEERFM التقليدية.
لمنع أي تأثير على البيئة المحلية ، يتم استخدام Redis و Elasticsearch و Feast و Triton في حاويات Docker. للمتابعة ، يرجى التأكد من تثبيت Docker على الكمبيوتر المحمول الخاص بك ، ثم تنفيذ الأوامر التالية لتنزيل صور Docker المعنية.
docker pull redis:6.0.0
docker pull elasticsearch:8.8.0
docker pull feastdev/feature-server:0.31.0
docker pull nvcr.io/nvidia/tritonserver:20.12-py3يتم استخدام Redis كقاعدة بيانات لتخزين معلومات المستخدم اللازمة للتذكير.
ابدأ حاوية redis.
docker run --name redis -p 6379:6379 -d redis:6.0.0تتضمن العملية تحميل مصطلح المستخدم والمتجه والتصفية في redis. يتم إنشاء مصطلح وبيانات المتجه في القسم 1.2 ، بينما يتعلق المرشح بالعناصر التي يتفاعل بها المستخدم مسبقًا. يتم استبعاد هذه العناصر التي تمت تصفيتها عند إنشاء توصيات.
بمجرد تحميل البيانات ، سيتم تنفيذ خطوة التحقق من خلال التحقق من البيانات لمستخدم عينة. سيتم الإشارة إلى التحقق الناجح من خلال الإخراج المعروض أدناه.
cd offline_to_online/recall/
python s1_user_to_redis.py
يتم استخدام Elasticsearch لإنشاء كل من الفهرس المقلوب وفهرس المتجه للعناصر. المصمم في الأصل لتطبيقات البحث ، تتضمن حالة الاستخدام الأساسي لـ Elasticsearch استخدام الكلمات لاسترداد المستندات. في سياق أنظمة التوصية ، نتعامل مع عنصر كمستند ، وشروطه ، مثل أنواع الأفلام ، مثل الكلمات. يتيح لنا ذلك استخدام Elasticsearch لاسترداد العناصر بناءً على هذه المصطلحات. يتماشى هذا المفهوم مع فكرة الفهارس المقلوبة ، مما يجعل Elasticsearch أداة قيمة للاستدعاء في أنظمة التوصية. لاستدعاء المتجهات ، فإن الأداة الشائعة الاستخدام هي Faiss المفتوحة من Facebook. ومع ذلك ، من أجل سهولة التكامل ، اخترنا استخدام إمكانيات استرجاع المتجهات Elasticsearch. دعمت Elasticsearch استرجاع المتجهات منذ الإصدار 7 ، وتقريب K-nearest Retrieval منذ الإصدار 8. في هذا المشروع ، نقوم بتثبيت إصدار من Elasticsearch الذي يبلغ 8 (أو أعلى). يتم إجراء هذا الاختيار لأن استرجاع KNN الدقيق غالبًا ما لا يمكن أن يفي بمتطلبات التشغيل المنخفضة للنظام عبر الإنترنت.
ابدأ حاوية Elasticsearch وأدخل محطةها الداخلية عن طريق تنفيذ الأوامر التالية.
docker run --name es8 -p 9200:9200 -it elasticsearch:8.8.0 انسخ كلمة المرور المعروضة في الإخراج الطرفي الخاص بك (كما هو موضح أدناه) وقم بصقها كقيمة لـ es_key في ملف data_exchange_center/constants.py. هذه الخطوة ضرورية لأن Elasticsearch قام بتطبيق متطلبات مصادقة كلمة المرور بدءًا من الإصدار 8.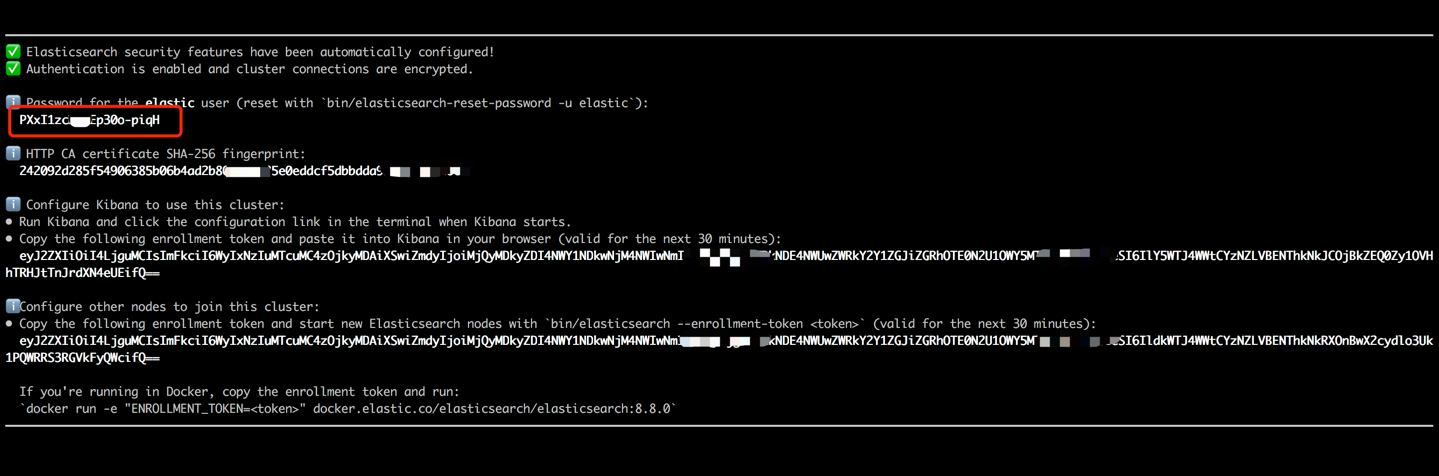
بمجرد أن يتم لصق كلمة المرور ، قم بالخروج من المحطة الداخلية باستخدام اختصار لوحة المفاتيح CTRL+C (أو Command+C). سيوقف هذا الإجراء أيضًا الحاوية ، لذلك نحتاج إلى إعادة تشغيل حاوية Elasticsearch والتأكد من تشغيله في الخلفية كجزء من الخطوات اللاحقة.
docker start es8قم بتحميل مصطلحات العنصر لإنشاء مصطلح فهرس وتحميل ناقلات العنصر لإنشاء فهرس المتجه. في الإعدادات الصناعية ، يتم فصل هذين الفهسين عادة لتحسين الأداء والمرونة. ومع ذلك ، من أجل البساطة في هذا المشروع ، نحن نجمعها في فهرس واحد.
باتباع عملية تحميل البيانات ، سيتم تنفيذ خطوة التحقق من صحة عن طريق التحقق من مصطلح وناقل عنصر العينة. سيتم الإشارة إلى التحقق الناجح من خلال الإخراج المعروض أدناه.
cd offline_to_online/recall/
python s2_item_to_es.py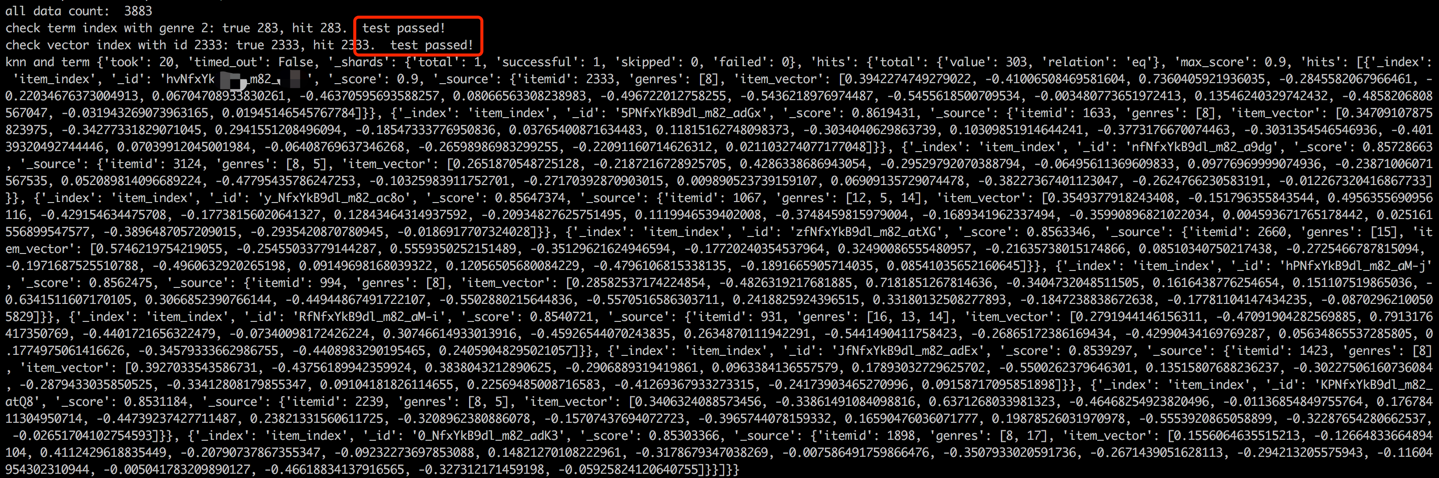
يقف العيد كمتجر ميزات مفتوح المصدر الرائد ، ويحمل أهمية تاريخية في هذا المجال. يشمل العيد كل من المكونات غير المتصلة بالإنترنت وعبر الإنترنت. المكون غير المتصل يسهل في المقام الأول انضمام النقطة في الوقت المناسب. ومع ذلك ، نظرًا لأننا تمكننا من إمكانية تواصل في الوقت المناسب في Pandas بأنفسنا ، فليس هناك ضرورة لاستخدام إمكانيات Feast دون اتصال. بدلاً من ذلك ، نستخدم Feast كمتجر للميزات عبر الإنترنت. يكمن السبب وراء عدم استخدام Feast for Point-Lime في حقيقة أن Feast يوفر في المقام الأول إمكانات تخزين الميزات ويفتقر إلى إمكانيات هندسة الميزات (على الرغم من أنها أدخلت بعض التحولات الأساسية في الإصدارات الحديثة). تفضل معظم الشركات محركات الميزات المخصصة ذات القدرات الأكثر قوة. لذلك ، ليست هناك حاجة لاستثمار الكثير من الجهد في تعلم الاستخدام غير المتصلة بالإنترنت. من العملي أكثر استخدام أدوات عامة مثل Pandas أو Spark لمعالجة الميزات والاستفادة من العيد فقط كمكون لنقل الميزات بين الاتصال بالإنترنت وعبر الإنترنت.
قم بتحويل ملفات الميزات من CSV إلى تنسيق Parquet لتلبية متطلبات Feast.
cd offline_to_online/rank/
python s1_feature_to_feast.pyافتح محطة جديدة (تسمى Terminal 2) ، وابدأ حاوية العيد مع 6566 كمنفذ HTTP وأدخل المحطة الداخلية من خلال تنفيذ الأوامر التالية.
cd data_exchange_center/online/feast
docker run --rm --name feast-server --entrypoint " bash " -v $( pwd ) :/home/hs -p 6566:6566 -it feastdev/feature-server:0.31.0تنفيذ الأوامر التالية في المحطة الداخلية لحاوية العيد.
# Enter the config directory
cd /home/hs/ml/feature_repo
# Initialize the feature store from config files (read parquet to build database)
feast apply
# Load features from offline to online (defaults to sqlite, with options like Redis available)
feast materialize-incremental " $( date + ' %Y-%m-%d %H:%M:%S ' ) "
# Start the feature server
feast serve -h 0.0.0.0 -p 6566بعد الانتهاء من جميع الخطوات ، سيتم عرض الإخراج التالي.
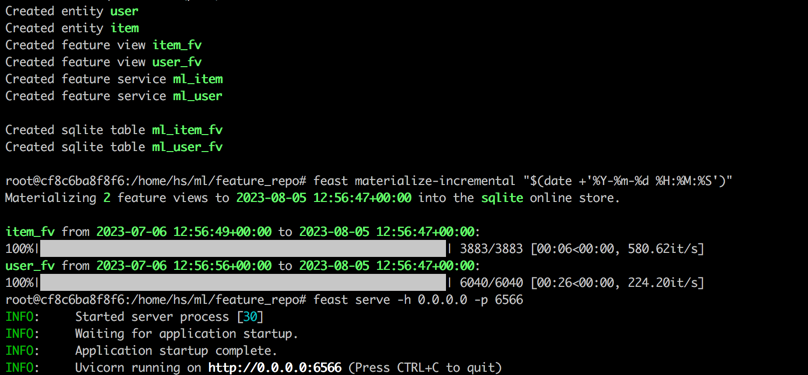
العودة إلى المحطة 1 ، قم بتنفيذ الأمر التالي لاختبار ما إذا كان العيد يعمل بشكل صحيح. سيتم طباعة سلسلة استجابة JSON إذا نجحت.
curl -X POST
" http://localhost:6566/get-online-features "
-d ' {
"feature_service": "ml_item",
"entities": {
"itemid": [1,3,5]
}
} ' Triton (Triton Interference Server) هو محرك خدمة الاستدلال مفتوح المصدر تم تطويره بواسطة NVIDIA. يقدم Triton Interference Server دعمًا لمجموعة متنوعة من الأطر مثل TensorFlow و Pytorch و ONNX وخيارات إضافية ، مما يجعلها خيارًا ممتازًا لتقديم النموذج. على الرغم من تطويره بواسطة NVIDIA ، فإن Triton متعدد الاستخدامات بما يكفي للخدمة مع وحدات المعالجة المركزية ، مما يوفر المرونة في استخدامها. في حين أن حل الصناعة الأكثر انتشارًا يتضمن TensorFlow -> SaveModel -> خدمة TensorFlow ، فإن Triton تكتسب شعبية بسبب قابليتها للتكيف في التبديل بين الأطر المختلفة. وبالتالي ، في هذا المشروع ، نعتمد خط أنابيب يستخدم Pytorch -> Onnx -> Triton Server.
تحويل نموذج Pytorch إلى تنسيق OnNx.
cd offline_to_online/rank/
python s2_model_to_triton.pyافتح محطة جديدة (تسمى المحطة 3) ، ابدأ حاوية Triton مع 8000 كمنفذ HTTP و 8001 كمنفذ GRPC من خلال تنفيذ الأوامر التالية.
cd data_exchange_center/online/triton
docker run --rm -p8000:8000 -p8001:8001 -p8002:8002 -v $( pwd ) /:/models/ nvcr.io/nvidia/tritonserver:20.12-py3 tritonserver --model-repository=/models/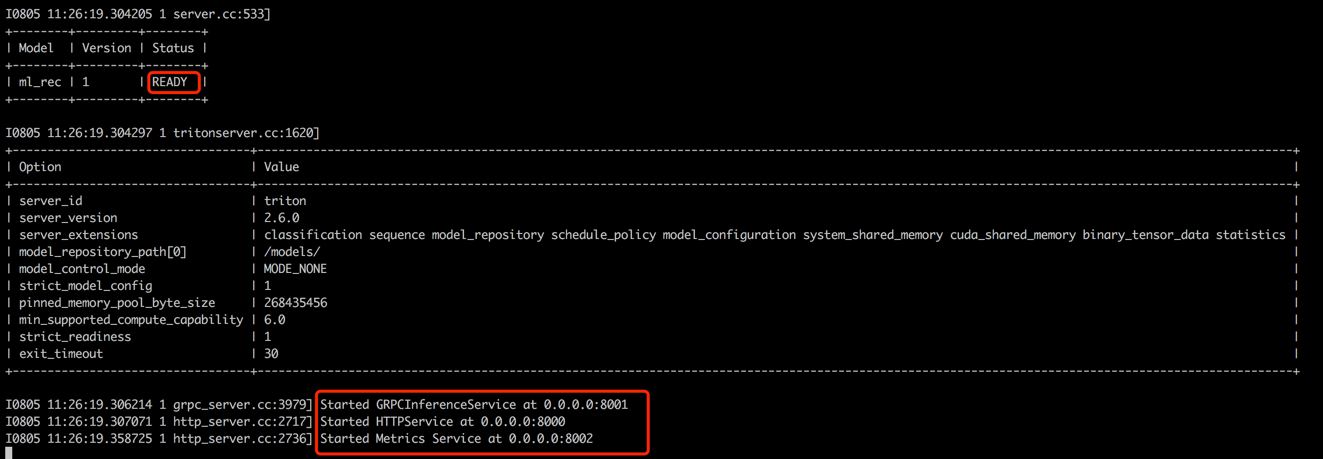
العودة إلى المحطة 1 ، قم بتشغيل البرنامج النصي لاختبار الاتساق بين درجات التنبؤ غير المتصل عبر الإنترنت. ستساعد هذه الخطوة في ضمان موثوقية نظام التوصية.
cd offline_to_online/rank/
python s3_check_offline_and_online.pyكما هو موضح أدناه ، فإن الدرجات غير المتصلة بالإنترنت وعبر الإنترنت متطابقة ، مما يشير إلى الاتساق بين الاتصال بالإنترنت وعبر الإنترنت.

في الإعدادات الصناعية ، يختار المهندسون عادة Java + Springboot أو Go + Gin كوجود خلفي لأنظمة التوصية. ومع ذلك ، في هذا المشروع من أجل سهولة التكامل ، يتم استخدام Python + Flask. تجدر الإشارة إلى أن هناك العديد من أطر عمل الويب لـ Python ، بما في ذلك Django و Flask و Fastapi و Tornado ، وكلها قادرة على توجيه طلبات Restapi إلى وظائف المعالجة. أي من هذه الأطر يمكن أن تلبي متطلباتنا ، تم اختيار Flask بشكل عشوائي لهذا المشروع.
افتح محطة جديدة (تسمى Terminal 4) ، ابدأ خادم Flask Web مع 5000 كمنفذ HTTP من خلال تنفيذ الأوامر التالية.
conda activate rsppl
cd online/main
flask --app s1_server.py run --host=0.0.0.0
العودة إلى المحطة 1 وإجراء اختبار عن طريق الاتصال بخدمة التوصية من عميل (في هذا السياق ، يشير العميل إلى خدمة المنبع التي تستدعي خدمة التوصية ، وليس أجهزة المستخدم). سيتم إرجاع النتائج بتنسيق JSON ، مع عرض معرفات العنصر الموصى بها أفضل 50. بعد ذلك ، يمكن لخدمة المصب استخدام معرفات العناصر هذه لاسترداد سماتها المقابلة ثم تزويدها بالعميل (في هذا السياق ، جهاز المستخدم). هذا يكمل تدفق التوصية الكامل.
cd online/main
python s2_client.py


