recsys_pipeline
1.0.0
Английский | 中文
Используя хорошо известный набор данных Movieelens в качестве примера, мы представим системный трубопровод ERRECTINDER от автономного до онлайн, причем все операции могут быть выполнены на одном ноутбуке. Несмотря на использование нескольких компонентов, важно отметить, что все содержится в Conda и Docker, что обеспечивает никакого влияния на местную среду.
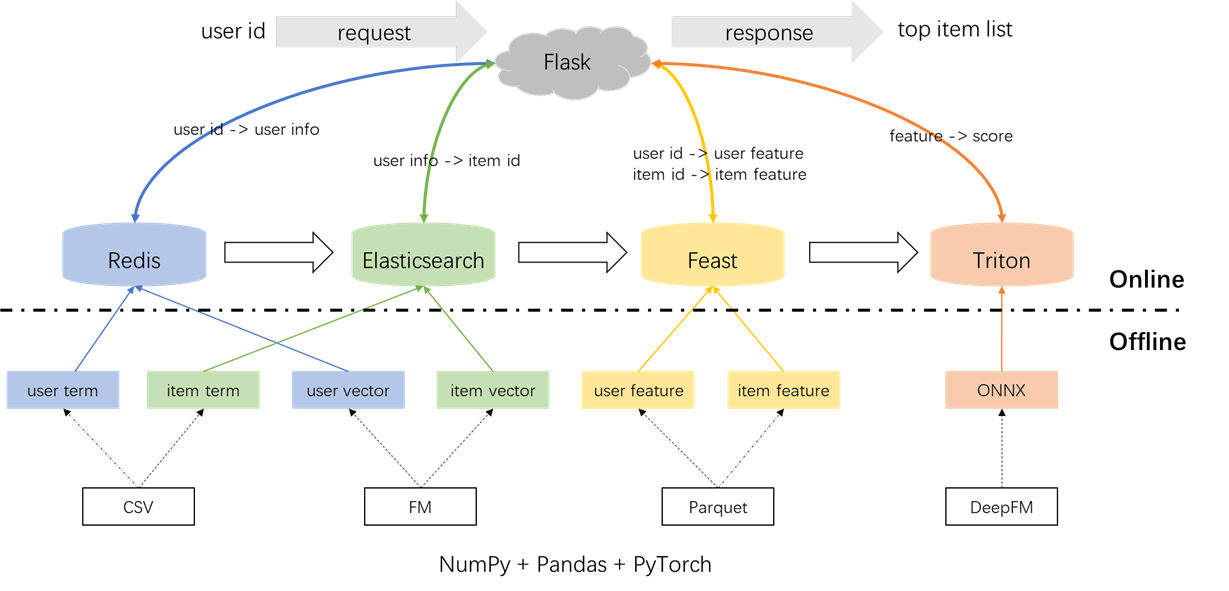
Общая архитектура системы рекомендации показана ниже. Теперь мы представим процессы разработки и развертывания для модулей отзывов и ранжирования на трех этапах: автономный, офлайн к линии и онлайн.
conda create -n rsppl python=3.8
conda activate rsppl
conda install --file requirements.txt --channel anaconda --channel conda-forge cd offline/preprocess/
python s1_data_split.py
python s2_term_trans.pyПредварительная обработка меток, образцов и функций:
Важно подчеркнуть концепцию соединений в времени в времени в файле S2_Term_trans.py. В частности, во время генерации автономных тренировочных образцов (IMP_TERM.PKL) должны использоваться в течение и включения времени, ближайшего к настоящему моменту. Использование функций после этой точки будет ввести утечку функций, тогда как использование функций, которые значительно отдалены во времени от настоящего, приведут к несоответствиям между офлайн и онлайн. Напротив, самые последние функции должны быть развернуты для онлайн -обслуживания (user_term.pkl и item_term.pkl).
cd offline/recall/
python s1_term_recall.py
python s2_vector_recall.pyОтзыв термина: этот компонент использует прошлые взаимодействия пользователя с элементами ('жанрами) в пределах указанного временного окна, чтобы сопоставить пользовательские предпочтения с элементами. Эти термины будут загружены в Redis и Elasticsearch позже.
Вектор отзыв: в этом компоненте используются FM (машины для факторизации), используя только идентификатор пользователя и идентификатор элемента в качестве функций. Полученный AUC (площадь под кривой) = 0,8081. После завершения этапа обучения векторы пользователей и элементов извлекаются с контрольной точки модели и будут загружены в Redis и Elasticsearch для последующего использования.
cd offline/rank/
python s1_feature_engi.py
python s2_model_train.pyВ общей сложности существует 59 функций, в том числе три типа: однокачественные функции (такие как userID, itemID, пол и т. Д.), Многоотдельные функции (жанры) и плотные функции (историческая поведенческая статистика).
Используемая модель рейтинга является DeepFM, достигая AUC 0,8206. В то время как Pytorch-FM является элегантным пакетом для алгоритмов на основе FM, он имеет два ограничения: 1. Он исключительно поддерживает разреженные функции и не имеет поддержки плотных функций. 2. Все разреженные функции имеют одно и то же измерение, которое нарушает интуицию, что «ID встраивания должны быть высокоразмерными, в то время как побочные вставки должны быть низкомерными». Чтобы учесть эти ограничения, мы внесли изменения в исходный код, обеспечивая поддержку как плотных функций, так и различных аспектов встраивания для разреженных функций. Кроме того, было отмечено, что модуль глубокого встраивания негативно повлиял на производительность модели, что вызвало его удаление из модели. В результате текущая структура модели в основном состоит из разреженного FM -модуля, интегрированного с плотным MLP, это не обычная DeepFM.
Чтобы предотвратить любое влияние на местную среду, Redis, Elasticsearch, Feast и Triton используются в контейнерах Docker. Чтобы продолжить, убедитесь, что Docker был установлен на вашем ноутбуке, а затем выполните следующие команды для загрузки соответствующих изображений Docker.
docker pull redis:6.0.0
docker pull elasticsearch:8.8.0
docker pull feastdev/feature-server:0.31.0
docker pull nvcr.io/nvidia/tritonserver:20.12-py3Redis используется в качестве базы данных для хранения пользовательской информации, необходимой для отзыва.
Начните контейнер Redis.
docker run --name redis -p 6379:6379 -d redis:6.0.0Процесс включает в себя загрузку термина, вектор и фильтр в Redis. Термин и данные вектора генерируются в разделе 1.2, в то время как фильтр относится к элементам, с которыми пользователь ранее взаимодействовал. Эти фильтрованные элементы исключаются при генерации рекомендаций.
После загрузки данных, шаг проверки будет выполнен путем проверки данных для образца пользователя. Успешная проверка будет указана выходом, отображаемым ниже.
cd offline_to_online/recall/
python s1_user_to_redis.py
Elasticsearch используется для создания как инвертированного индекса, так и векторного индекса для элементов. Первоначально разработанный для поисковых приложений, фундаментальный вариант использования Elasticsearch включает использование слов для извлечения документов. В контексте рекомендательных систем мы рассматриваем элемент как документ и его термины, такие как жанры фильма, как слова. Это позволяет нам использовать Elasticsearch для извлечения элементов на основе этих терминов. Эта концепция согласуется с понятием инвертированных индексов, что делает Elasticsearch ценным инструментом для отзывов терминов в рекомендательных системах. Для отзыва вектора, обычно используемым инструментом является Facebook Faceists. Тем не менее, ради простоты интеграции, мы решили использовать возможности поиска вектора Elasticsearch. Elasticsearch поддерживает поиск вектора со времен версии 7 и приблизительного поиска K-ближайшего соседа (ANN) с версии 8. В этом проекте мы устанавливаем версию Elasticsearch, которая составляет 8 (или выше). Этот выбор сделан, потому что точный поиск KNN часто не может соответствовать требованиям онлайн-системы с низкой задержкой.
Начните контейнер Elasticsearch и введите его внутренний терминал, выполнив следующие команды.
docker run --name es8 -p 9200:9200 -it elasticsearch:8.8.0 Скопируйте пароль, отображаемый в выводе вашего терминала (как указано ниже) и вставьте его в качестве значения для ES_KEY в файле data_exchange_center/constants.py. Этот шаг необходим, потому что Elasticsearch реализовал требования к аутентификации пароля, начиная с версии 8.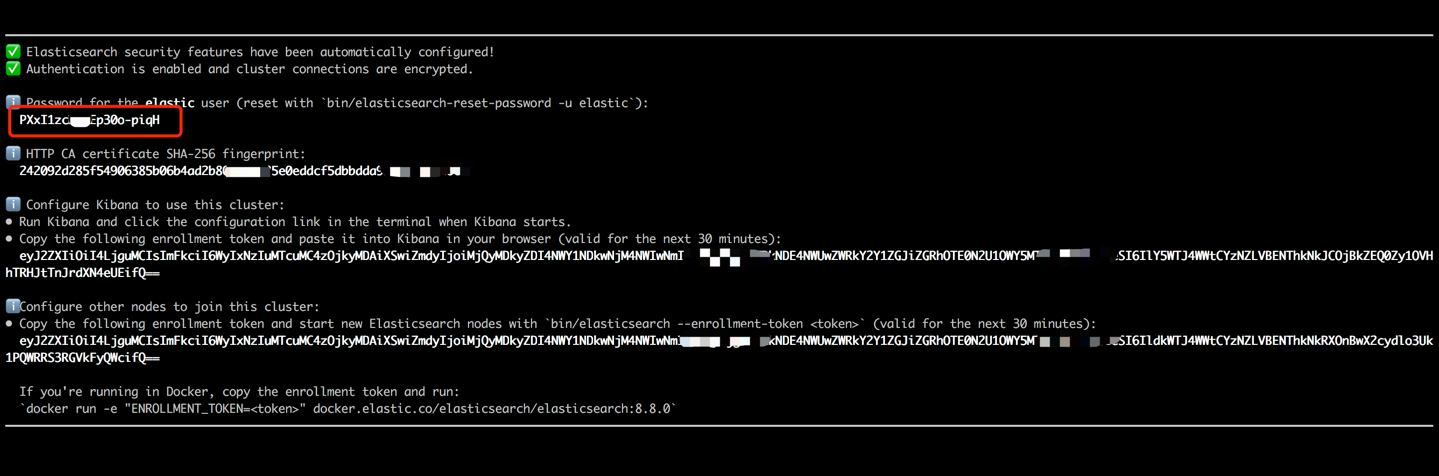
После того, как пароль был вставлен, выйдите из внутреннего терминала, используя сочетание клавиш CTRL+C (или команда+c). Это действие также остановит контейнер, поэтому нам необходимо перезагрузить контейнер Elasticsearch и убедиться, что он работает в фоновом режиме как часть последующих шагов.
docker start es8Загрузите члены элемента, чтобы создать индекс термина и загрузить векторы элемента, чтобы создать векторный индекс. В промышленных настройках эти два индекса обычно разделены для лучшей производительности и гибкости. Однако для простоты в этом проекте мы объединяем их в один индекс.
В соответствии с процессом загрузки данных, будет выполнен шаг проверки путем проверки термина и вектора элемента образца. Успешная проверка будет указана выходом, отображаемым ниже.
cd offline_to_online/recall/
python s2_item_to_es.py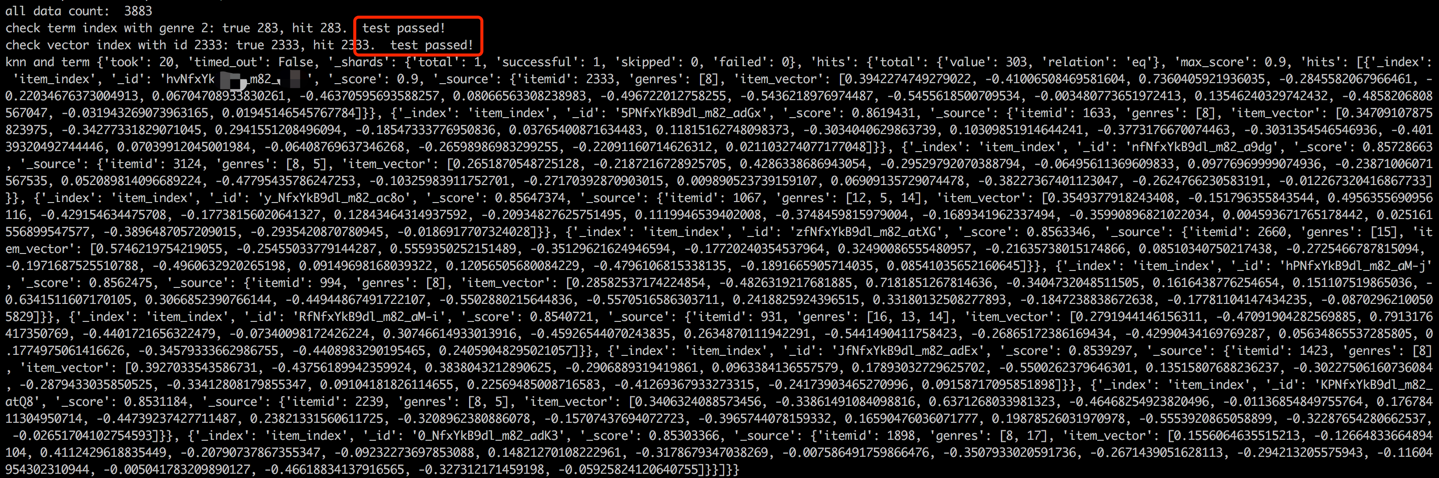
Feast стоит как новаторский магазин с открытым исходным кодом, обладающий историческим значением в этой области. Праздник включает в себя как автономные, так и онлайн -компоненты. Офлайн-компонент в первую очередь облегчает объединения в времени. Однако, поскольку мы сами управляли временем в Pandas, нет необходимости использовать автономные возможности Feast. Вместо этого мы используем праздник в качестве интернет -магазина. Причина, по которой не используют праздник для объединений в времени, заключается в том, что пир в первую очередь предлагает возможности хранения функций и не имеет возможности инженерии функций (хотя он ввел некоторые основные преобразования в последних версиях). Большинство компаний предпочитают индивидуальные функциональные двигатели с более мощными возможностями. Поэтому нет необходимости вкладывать большие усилия в обучение автономному использованию Feast. Более практично использовать более общие инструменты, такие как Pandas или Spark для обработки функций и использование праздника исключительно в качестве компонента для транспортировки функций между офлайн и онлайн.
Конвертируйте файлы функций из CSV в формат Parquet, чтобы удовлетворить требования Feast.
cd offline_to_online/rank/
python s1_feature_to_feast.pyОткройте новый терминал (называемый терминалом 2), запустите контейнер для праздника с 6566 в качестве порта HTTP и введите его внутренний терминал, выполнив следующие команды.
cd data_exchange_center/online/feast
docker run --rm --name feast-server --entrypoint " bash " -v $( pwd ) :/home/hs -p 6566:6566 -it feastdev/feature-server:0.31.0Выполнить следующие команды во внутреннем терминале контейнера.
# Enter the config directory
cd /home/hs/ml/feature_repo
# Initialize the feature store from config files (read parquet to build database)
feast apply
# Load features from offline to online (defaults to sqlite, with options like Redis available)
feast materialize-incremental " $( date + ' %Y-%m-%d %H:%M:%S ' ) "
# Start the feature server
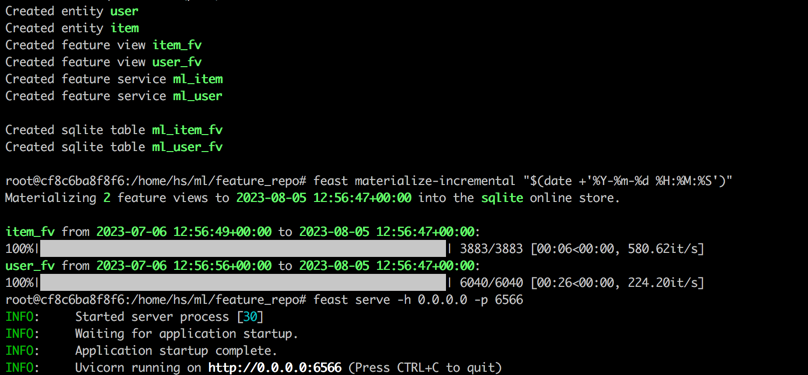
feast serve -h 0.0.0.0 -p 6566После завершения всех шагов будет отображаться следующий выход.
Вернемся к терминалу 1, выполните следующую команду, чтобы проверить, правильно ли подает пир. Строка ответа json будет напечатана, если успешно.
curl -X POST
" http://localhost:6566/get-online-features "
-d ' {
"feature_service": "ml_item",
"entities": {
"itemid": [1,3,5]
}
} ' Triton (Triton Senrefer Server)-это двигатель с открытым исходным кодом, разработанный NVIDIA. Triton Senrefer Server предлагает поддержку разнообразных структур, таких как Tensorflow, Pytorch, ONNX и дополнительные варианты, что делает его отличным выбором для модели. Несмотря на то, что он разработан Nvidia, Triton достаточно универсален, чтобы служить с процессорами, предлагая гибкость в своем использовании. Хотя более распространенное отраслевое решение включает в себя Tensorflow -> SavedModel -> Tensorflow Aerding, Triton набирает популярность благодаря своей адаптации при переключении между различными рамками. Следовательно, в этом проекте мы принимаем конвейер, который использует Pytorch -> Onnx -> Triton Server.
Преобразовать модель Pytorch в формат ONNX.
cd offline_to_online/rank/
python s2_model_to_triton.pyОткройте новый терминал (называемый терминалом 3), запустите контейнер Triton с 8000 в качестве порта HTTP и 8001 в качестве порта GRPC, выполнив следующие команды.
cd data_exchange_center/online/triton
docker run --rm -p8000:8000 -p8001:8001 -p8002:8002 -v $( pwd ) /:/models/ nvcr.io/nvidia/tritonserver:20.12-py3 tritonserver --model-repository=/models/
Вернемся к терминалу 1, запустите сценарий, чтобы проверить согласованность между офлайн и онлайн -оценками прогнозирования. Этот шаг поможет обеспечить надежность системы рекомендаций.
cd offline_to_online/rank/
python s3_check_offline_and_online.pyКак показано ниже, офлайн и онлайн -оценки идентичны, что указывает на согласованность между автономным и онлайн.

В промышленных настройках инженеры обычно выбирают Java + Springboot или Go + Gin в качестве бэкэнда для систем рекомендаций. Тем не менее, в этом проекте ради легкого интеграции используется колба Python +. Стоит отметить, что есть несколько веб -структур для Python, включая Django, Flask, Fastapi и Tornado, которые способны маршрутизировать запросы Restapi для функций для обработки. Любая из этих структур может соответствовать нашим требованиям, Флэста была выбрана случайным образом для этого проекта.
Откройте новый терминал (называемый терминалом 4), запустите веб -сервер Flask с 5000 в качестве порта HTTP, выполнив следующие команды.
conda activate rsppl
cd online/main
flask --app s1_server.py run --host=0.0.0.0
Вернемся к Терминалу 1 и проведите тест, позвонив в службу рекомендаций от клиента (в этом контексте клиент ссылается на сервис UPSTREAM, которая называет службу рекомендаций, а не пользовательские устройства). Результаты будут возвращены в формате JSON с отображением 50 лучших рекомендуемых идентификаторов элементов. Впоследствии, нисходящая служба может использовать эти идентификаторы элементов для извлечения соответствующих атрибутов, а затем предоставить их клиенту (в этом контексте пользовательское устройство). Это завершает полный поток рекомендаций.
cd online/main
python s2_client.py


