recsys_pipeline
1.0.0
Englisch | 中文
Mit dem bekannten Movielens-Datensatz als Beispiel werden wir die Empfehlungssystempipeline von Offline bis online einführen, wobei alle Vorgänge auf einem einzigen Laptop ausgeführt werden können. Trotz der Verwendung mehrerer Komponenten ist es wichtig zu beachten, dass alles in Conda und Docker enthalten ist, um keine Auswirkungen auf die lokale Umgebung zu gewährleisten.
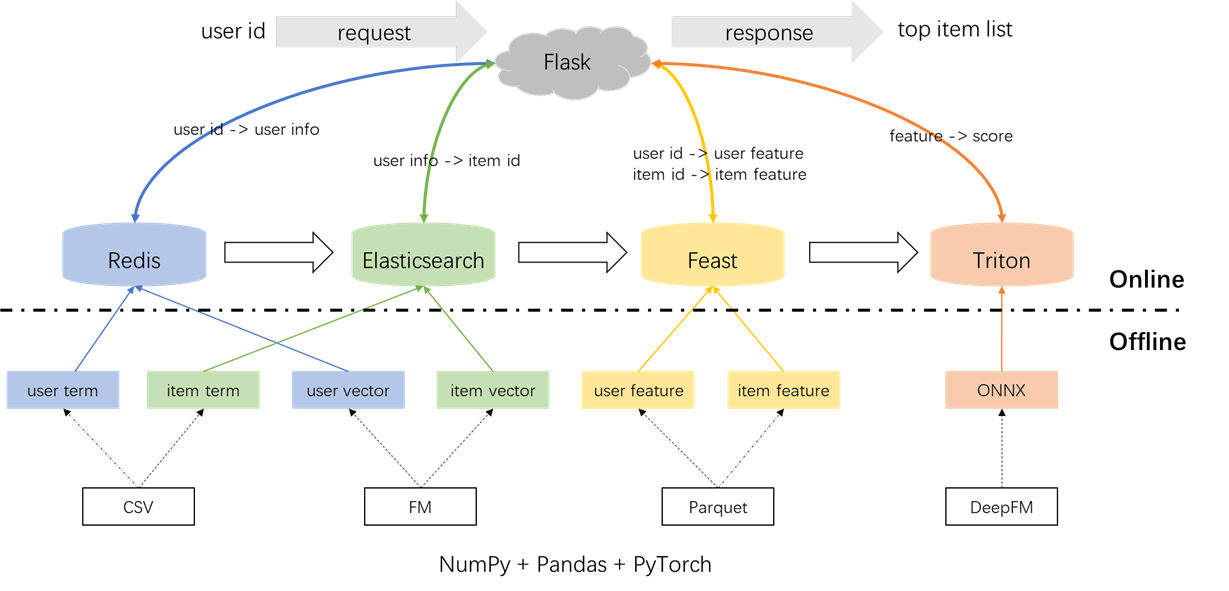
Die Gesamtarchitektur des Empfehlungssystems ist nachstehend dargestellt. Jetzt werden wir die Entwicklungs- und Bereitstellungsprozesse für die Rückruf- und Ranking-Module in drei Phasen vorstellen: Offline, Offline-To-Online und Online.
conda create -n rsppl python=3.8
conda activate rsppl
conda install --file requirements.txt --channel anaconda --channel conda-forge cd offline/preprocess/
python s1_data_split.py
python s2_term_trans.pyVorverarbeitung von Etiketten, Proben und Merkmalen:
Es ist wichtig, das Konzept von Point-in-Time-Verbindungen in der Datei s2_term_trans.py hervorzuheben. Insbesondere während der Erzeugung von Offline -Trainingsproben (Imp_term.pkl) sollte die Funktionen bis hin zur Zeit der am vorliegenden Zeit am nächsten gelegenen Aktion verwendet werden. Die Verwendung von Funktionen nach diesem Punkt würde das Leckage der Funktionen einführen, während die Verwendung von Funktionen, die zeitlich von der Gegenwart erheblich entfernt sind, zu Inkonsistenzen zwischen Offline und Online führen würden. Im Gegensatz dazu sollten die neuesten Funktionen für Online -Servieren bereitgestellt werden (user_term.pkl und item_term.pkl).
cd offline/recall/
python s1_term_recall.py
python s2_vector_recall.pyBegriff Rückruf: Diese Komponente verwendet die früheren Interaktionen des Benutzers mit Elementen ('Genres) innerhalb eines bestimmten Zeitfensters, um die Benutzereinstellungen mit Elementen abzustimmen. Diese Begriffe werden später in Redis und Elasticsearch geladen.
Vektor -Rückruf: In dieser Komponente werden FM (Faktorisierungsmaschinen) verwendet, wobei nur die Benutzer -ID und die Element -ID als Funktionen verwendet werden. Die resultierende AUC (Fläche unter der Kurve) = 0,8081. Nach Abschluss der Trainingsphase werden Benutzer- und Elementvektoren aus dem Modellkontrollpunkt extrahiert und werden zur späteren Nutzung in Redis und Elasticsearch geladen.
cd offline/rank/
python s1_feature_engi.py
python s2_model_train.pyInsgesamt gibt es 59 Funktionen, darunter drei Typen: One-Hot-Funktionen (wie BenutzerID, Element, Geschlecht usw.), Multi-Hot-Merkmale (Genres) und dichte Merkmale (historische Verhaltensstatistiken).
Das verwendete Ranking -Modell ist DeepFM und erreicht einen AUC von 0,8206. Während Pytorch-FM ein elegantes Paket für FM-basierte Algorithmen ist, hat es zwei Einschränkungen: 1. Es unterstützt ausschließlich spärliche Funktionen und fehlt die Unterstützung für dichte Funktionen. 2. Alle spärlichen Merkmale haben die gleiche Dimension, was gegen die Intuition verstößt, dass "ID-Einbettungen hochdimensional sein sollten, während Seiteninformationen ein niedrigdimensionales sein sollten". Um diese Einschränkungen anzugehen, haben wir Änderungen am Quellcode vorgenommen, um sowohl dichte Merkmale als auch unterschiedliche Einbettungsabmessungen für spärliche Merkmale zu unterstützen. Darüber hinaus wurde festgestellt, dass das tiefe Einbettungsmodul die Modellleistung negativ beeinflusst, was zu seiner Entfernung aus dem Modell führte. Infolgedessen besteht die aktuelle Modellstruktur hauptsächlich aus einem spärlichen FM -Modul, das mit einem dichten MLP integriert ist. Es handelt sich nicht um ein herkömmliches DeepFM.
Um Auswirkungen auf die lokale Umgebung zu verhindern, werden Redis, Elasticsearch, Fest und Triton in Docker -Containern beschäftigt. Um fortzufahren, stellen Sie bitte sicher, dass Docker auf Ihrem Laptop installiert wurde, und führen Sie dann die folgenden Befehle aus, um die jeweiligen Docker -Bilder herunterzuladen.
docker pull redis:6.0.0
docker pull elasticsearch:8.8.0
docker pull feastdev/feature-server:0.31.0
docker pull nvcr.io/nvidia/tritonserver:20.12-py3Redis wird als Datenbank zum Speichern von Benutzerinformationen verwendet, die für den Rückruf benötigt werden.
Starten Sie den Redis -Behälter.
docker run --name redis -p 6379:6379 -d redis:6.0.0Der Prozess beinhaltet das Laden der Begriff, Vektor und Filter des Benutzers in Redis. Die Begriffs- und Vektordaten werden in Abschnitt 1.2 generiert, während der Filter Elemente bezieht, mit denen der Benutzer zuvor interagiert hat. Diese gefilterten Elemente sind bei der Erstellung von Empfehlungen ausgeschlossen.
Sobald die Daten geladen sind, wird ein Validierungsschritt durchgeführt, indem die Daten für einen Beispielbenutzer überprüft werden. Eine erfolgreiche Validierung wird durch die unten angezeigte Ausgabe angezeigt.
cd offline_to_online/recall/
python s1_user_to_redis.py
Elasticsearch wird verwendet, um sowohl invertierten Index- als auch Vektorindex für Elemente zu erstellen. Der grundlegende Anwendungsfall von Elasticsearch wurde ursprünglich für Suchanwendungen entwickelt und umfasst die Verwendung von Wörtern zum Abrufen von Dokumenten. Im Kontext von Empfehlungssystemen behandeln wir einen Element als Dokument und seine Begriffe wie Filmgenres als Wörter. Auf diese Weise können wir Elasticsearch verwenden, um Elemente basierend auf diesen Begriffen abzurufen. Dieses Konzept entspricht dem Begriff der invertierten Indizes und macht Elasticsearch zu einem wertvollen Instrument für den Begriff in Empfehlungssystemen. Für Vector Recall ist ein häufig verwendetes Tool von Facebooks Open-Sourcing-Faiss. Aus Gründen der einfachen Integration haben wir uns jedoch dafür entschieden, Elasticsearchs Vektor -Abruffunktionen zu nutzen. ElasticSearch hat seit Version 8 die Vektorabnahme seit Version 8 und ungefähr seit Version 8 annähernd K-Nearest Neighbor (Ann) unterstützt. In diesem Projekt installieren wir eine Version von Elasticsearch mit 8 (oder höher). Diese Auswahl wird getroffen, da präzise KNN-Abrufs häufig nicht die Anforderungen an die Niedriglatenz eines Online-Systems erfüllen können.
Starten Sie den Elasticsearch -Container und geben Sie seinen internen Terminal ein, indem Sie folgende Befehle ausführen.
docker run --name es8 -p 9200:9200 -it elasticsearch:8.8.0 Kopieren Sie das in Ihrer Terminalausgabe angezeigte Kennwort (wie unten angegeben) und fügen Sie es als Wert für ES_KEY in der Datei data_exchange_center/constants.py ein. Dieser Schritt ist erforderlich, da Elasticsearch ab Version 8 die Kennwortauthentifizierungsanforderungen implementiert hat.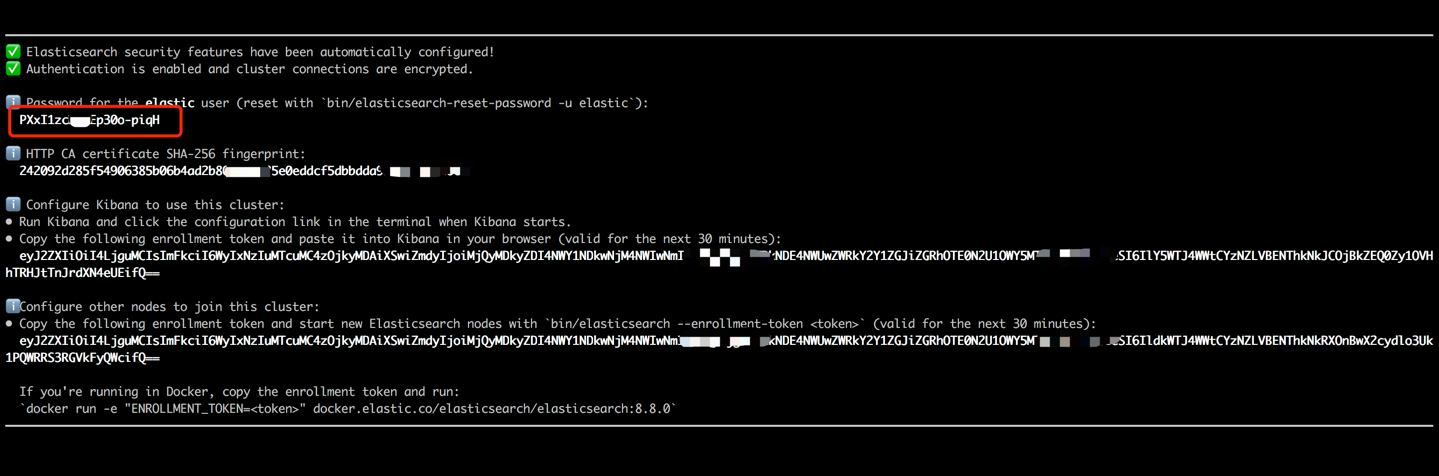
Sobald das Passwort eingefügt wurde, beenden Sie das interne Terminal mit der Tastaturverknüpfung von Strg+C (oder Befehl+C). Diese Aktion stoppt auch den Container, sodass wir den Elasticsearch -Container neu starten und sicherstellen müssen, dass er im Hintergrund als Teil der nachfolgenden Schritte ausgeführt wird.
docker start es8Laden Sie die Elementbegriffe, um den Termindex zu erstellen, und laden Sie die Elementvektoren, um den Vektorindex zu erstellen. In industriellen Umgebungen sind diese beiden Indizes in der Regel für eine bessere Leistung und Flexibilität getrennt. Der Einfachheit halber in diesem Projekt kombinieren wir sie jedoch zu einem einzigen Index.
Nach dem Datenbelastungsprozess wird ein Validierungsschritt durchgeführt, indem der Lauf und den Vektor eines Beispielelements überprüft wird. Eine erfolgreiche Validierung wird durch die unten angezeigte Ausgabe angezeigt.
cd offline_to_online/recall/
python s2_item_to_es.py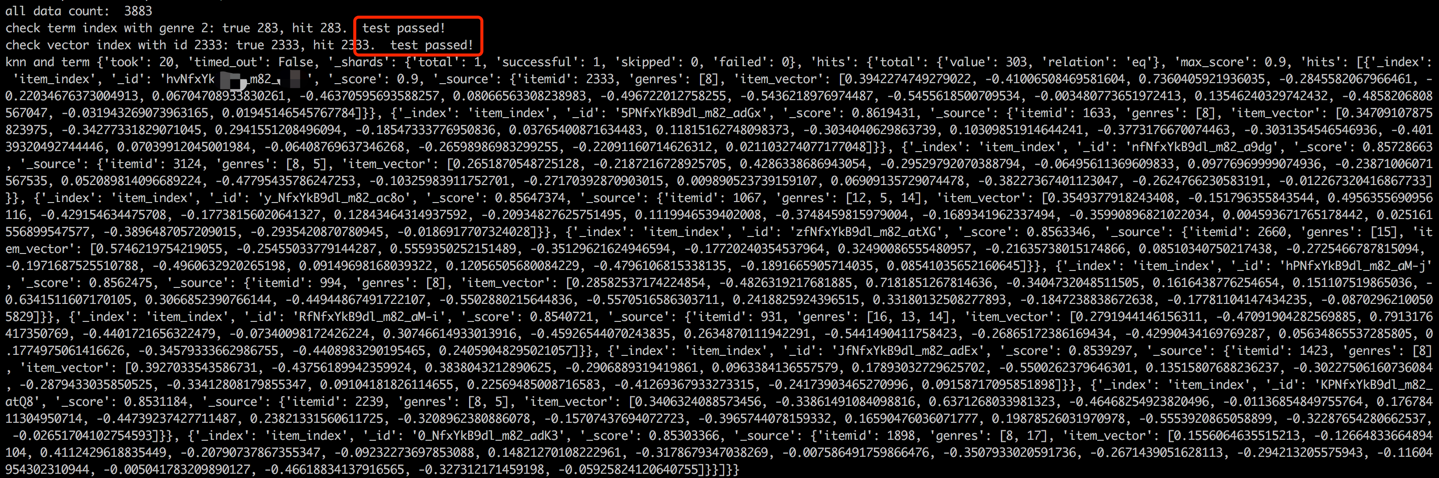
Feast steht als Pionier-Open-Source-Feature Store, das in diesem Bereich historische Bedeutung hat. Feast enthält sowohl Offline- als auch Online -Komponenten. Die Offline-Komponente erleichtert in erster Linie die Punkte in der Zeit. Da wir jedoch selbst mit Pandas mit Pandas verbunden sind, besteht keine Notwendigkeit, die Offline-Funktionen von Feast zu nutzen. Stattdessen beschäftigen wir Feast als Online -Feature -Shop. Der Grund für die Nichtverwaltung von Feast für Point-in-Time-Anschlüsse liegt in der Tatsache, dass Feast in erster Linie Funktionen für Funktionen für Funktionen für Funktionen und Funktionen für Feature-Engineering anbietet (obwohl es in jüngsten Versionen einige grundlegende Transformationen eingeführt hat). Die meisten Unternehmen bevorzugen maßgeschneiderte Feature -Engines mit leistungsfähigeren Fähigkeiten. Daher besteht keine Notwendigkeit, große Anstrengungen in das Lernen von Feasts Offline -Nutzung zu investieren. Es ist praktischer, allgemeinere Tools wie Pandas oder Spark für Feature -Verarbeitung und Nutzen zu verwenden, nur als Komponente für den Transport von Funktionen zwischen Offline und Online.
Konvertieren Sie die Feature -Dateien von CSV in das Parquetformat, um die Anforderungen von Feast zu erfüllen.
cd offline_to_online/rank/
python s1_feature_to_feast.pyÖffnen Sie ein neues Terminal (terminal 2 genannt), starten Sie den Festcontainer mit 6566 als HTTP -Port und geben Sie sein internes Terminal ein, indem Sie die folgenden Befehle ausführen.
cd data_exchange_center/online/feast
docker run --rm --name feast-server --entrypoint " bash " -v $( pwd ) :/home/hs -p 6566:6566 -it feastdev/feature-server:0.31.0Führen Sie die folgenden Befehle im internen Terminal des Festcontainers aus.
# Enter the config directory
cd /home/hs/ml/feature_repo
# Initialize the feature store from config files (read parquet to build database)
feast apply
# Load features from offline to online (defaults to sqlite, with options like Redis available)
feast materialize-incremental " $( date + ' %Y-%m-%d %H:%M:%S ' ) "
# Start the feature server
feast serve -h 0.0.0.0 -p 6566Nach Abschluss aller Schritte wird die folgende Ausgabe angezeigt.
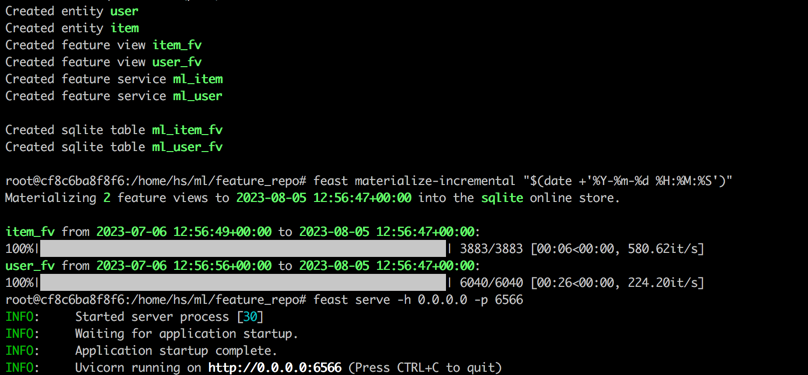
Führen Sie den folgenden Befehl zurück, um zu testen, ob das Fest ordnungsgemäß dient. Eine Antwort -JSON -Zeichenfolge wird bei erfolgreich gedruckt.
curl -X POST
" http://localhost:6566/get-online-features "
-d ' {
"feature_service": "ml_item",
"entities": {
"itemid": [1,3,5]
}
} ' Triton (Triton Inference Server) ist eine von NVIDIA entwickelte Open-Source-Inferenzmotor. Triton Inference Server bietet Unterstützung für eine Vielzahl von Frameworks wie TensorFlow, Pytorch, ONNX und zusätzliche Optionen, was es zu einer ausgezeichneten Wahl für das Modellieren von Modelldiensten macht. Obwohl es von Nvidia entwickelt wurde, ist Triton vielseitig genug, um mit CPUs zu dienen, und bietet Flexibilität in seiner Verwendung. Während eine häufigere Branchenlösung Tensorflow -> SavedModel -> TensorFlow Serving beinhaltet, gewinnt Triton aufgrund ihrer Anpassungsfähigkeit beim Umschalten zwischen verschiedenen Frameworks an Popularität. In diesem Projekt verwenden wir daher eine Pipeline, die Pytorch -> Onnx -> Triton Server verwendet.
Konvertieren Sie das Pytorch -Modell in das ONNX -Format.
cd offline_to_online/rank/
python s2_model_to_triton.pyÖffnen Sie ein neues Terminal (terminal 3 genannt) und starten Sie den Triton -Container mit 8000 als HTTP -Port und 8001 als GRPC -Port, indem Sie die folgenden Befehle ausführen.
cd data_exchange_center/online/triton
docker run --rm -p8000:8000 -p8001:8001 -p8002:8002 -v $( pwd ) /:/models/ nvcr.io/nvidia/tritonserver:20.12-py3 tritonserver --model-repository=/models/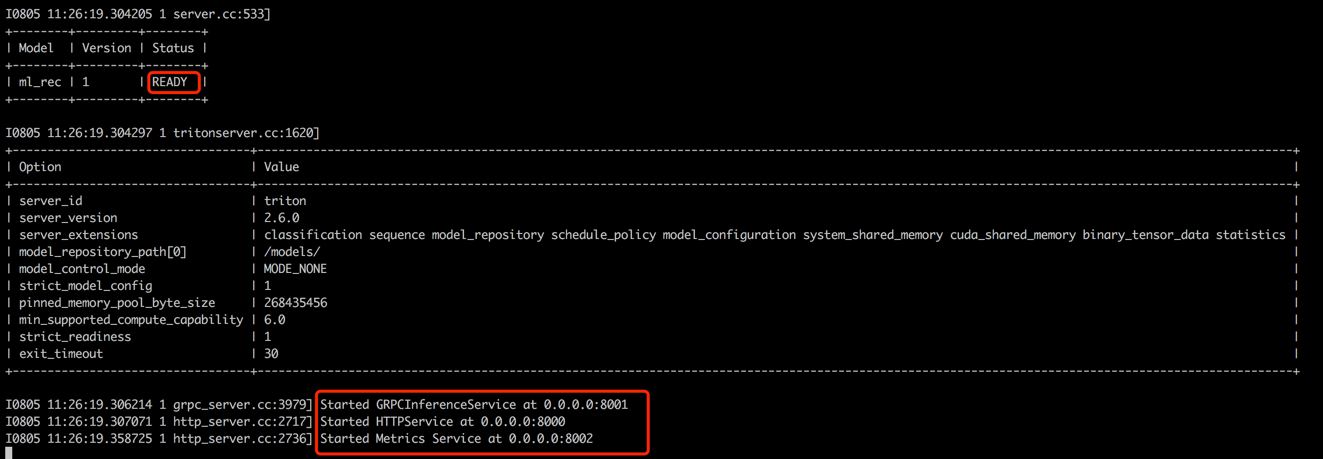
Führen Sie das Skript zurück, um die Konsistenz zwischen Offline- und Online -Vorhersagewerten zu testen. Dieser Schritt wird dazu beitragen, die Zuverlässigkeit des Empfehlungssystems zu gewährleisten.
cd offline_to_online/rank/
python s3_check_offline_and_online.pyWie unten gezeigt, sind die Offline- und Online -Ergebnisse identisch, was auf die Konsistenz zwischen Offline und Online hinweist.

In industriellen Umgebungen entscheiden sich Ingenieure häufig für Java + Springboot oder Go + Gin als Backend für Empfehlungssysteme. In diesem Projekt wird jedoch für die Integration einfacher Python + Flask verwendet. Es ist erwähnenswert, dass es mehrere Web -Frameworks für Python gibt, darunter Django, Flask, Fastapi und Tornado. Jedes dieser Frameworks konnte unsere Anforderungen erfüllen, Flask wurde für dieses Projekt zufällig ausgewählt.
Öffnen Sie ein neues Terminal (als Terminal 4 bezeichnet) den Flask -Webserver mit 5000 als HTTP -Port, indem Sie die folgenden Befehle ausführen.
conda activate rsppl
cd online/main
flask --app s1_server.py run --host=0.0.0.0
Zurück zu Terminal 1 und durchführen Sie einen Test, indem Sie den Empfehlungsdienst von einem Kunden aufrufen (in diesem Zusammenhang bezieht sich der Kunde auf den Upstream -Dienst, der den Empfehlungsdienst aufgerufen hat, nicht auf Benutzergeräte). Die Ergebnisse werden im JSON -Format zurückgegeben, wobei die 50 empfohlenen Element -IDs angezeigt werden. Anschließend kann der nachgeschaltete Dienst diese Element -IDs verwenden, um ihre entsprechenden Attribute abzurufen und sie dann dem Client (in diesem Zusammenhang, Benutzergerät) zur Verfügung zu stellen. Dadurch wird ein vollständiger Empfehlungsfluss abgeschlossen.
cd online/main
python s2_client.py


