recsys_pipeline
1.0.0
Anglais | 中文
En utilisant l'ensemble de données Moviens bien connu comme exemple, nous présenterons le pipeline du système Recomderder de hors ligne en ligne, toutes les opérations peuvent être exécutées sur un seul ordinateur portable. Malgré l'utilisation de plusieurs composants, il est important de noter que tout est contenu dans Conda et Docker, n'assurant aucun impact sur l'environnement local.
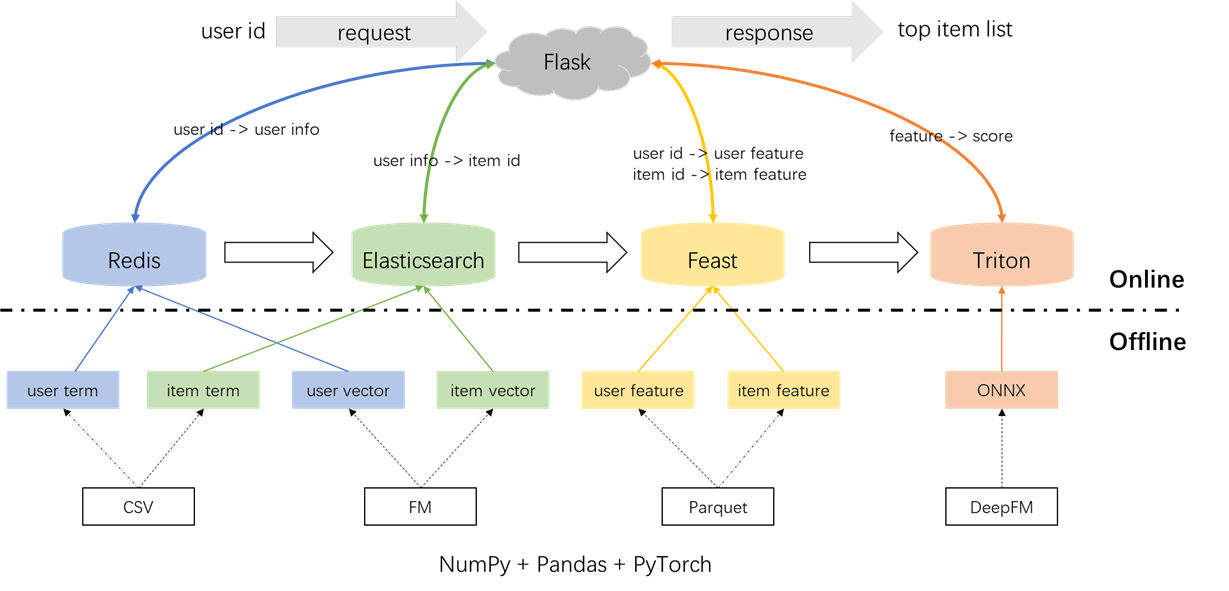
L'architecture globale du système de recommandation est illustrée ci-dessous. Maintenant, nous présenterons les processus de développement et de déploiement pour les modules de rappel et de classement sur trois phases: hors ligne, hors ligne et en ligne.
conda create -n rsppl python=3.8
conda activate rsppl
conda install --file requirements.txt --channel anaconda --channel conda-forge cd offline/preprocess/
python s1_data_split.py
python s2_term_trans.pyPrétraitement des étiquettes, des échantillons et des caractéristiques:
Il est important de mettre en évidence le concept de jointures ponctuelles dans le fichier s2_term_trans.py. Plus précisément, lors de la génération d'échantillons d'entraînement hors ligne (IMP_TERM.PKL), les fonctionnalités jusqu'à et y compris le temps de l'action le plus proche du moment présent doivent être utilisées. L'utilisation de fonctionnalités après ce point introduirait une fuite de fonctionnalités, tandis que l'utilisation de fonctionnalités qui sont considérablement éloignées dans le temps du présent entraîneraient des incohérences entre hors ligne et en ligne. En revanche, les fonctionnalités les plus récentes devraient être déployées pour la service en ligne (user_term.pkl et item_term.pkl).
cd offline/recall/
python s1_term_recall.py
python s2_vector_recall.pyRappel des termes: ce composant utilise les interactions passées de l'utilisateur avec les éléments ('genres) dans une fenêtre de temps spécifiée pour faire correspondre les préférences de l'utilisateur avec les éléments. Ces termes seront chargés dans Redis et Elasticsearch plus tard.
Rappel vecteur: Dans ce composant, FM (machines de factorisation) est utilisée, en utilisant uniquement l'ID utilisateur et l'ID d'élément comme fonctionnalités. L'AUC résultant (zone sous la courbe) = 0,8081. À la fin de la phase de formation, les vecteurs d'utilisateurs et d'élément sont extraits du point de contrôle du modèle et seront chargés dans Redis et Elasticsearch pour une utilisation ultérieure.
cd offline/rank/
python s1_feature_engi.py
python s2_model_train.pyAu total, il existe 59 fonctionnalités dont trois types: fonctionnalités à un hot (telles que l'utilisateur, itemID, sexe, etc.), les fonctionnalités multi-hot (genres) et les caractéristiques denses (statistiques comportementales historiques).
Le modèle de classement utilisé est DeepFM, atteignant un ASC de 0,8206. Bien que Pytorch-FM soit un package élégant pour les algorithmes basés sur FM, il a deux limites: 1. Il prend en charge exclusivement des fonctionnalités clairsemées et manque de prise en charge des fonctionnalités denses. 2. Toutes les caractéristiques clairsemées partagent la même dimension, ce qui viole l'intuition selon laquelle "les incorporations d'ID doivent être de grande dimension, tandis que les incorporations d'informations latérales doivent être de faible dimension". Pour répondre à ces contraintes, nous avons apporté des modifications au code source, permettant la prise en charge des fonctionnalités denses et des dimensions d'intégration variables pour les fonctionnalités clairsemées. De plus, il a été noté que le module d'incorporation profonde a eu un impact négatif sur les performances du modèle, ce qui a provoqué son retrait du modèle. En conséquence, la structure du modèle actuel se compose principalement d'un module FM clairsemé intégré à un MLP dense, il n'est pas un deepfm conventionnel.
Pour éviter tout impact sur l'environnement local, Redis, Elasticsearch, Feast et Triton sont tous employés dans des conteneurs Docker. Pour continuer, veuillez vous assurer que Docker a été installé sur votre ordinateur portable, puis exécuter les commandes suivantes pour télécharger les images Docker respectives.
docker pull redis:6.0.0
docker pull elasticsearch:8.8.0
docker pull feastdev/feature-server:0.31.0
docker pull nvcr.io/nvidia/tritonserver:20.12-py3Redis est utilisé comme une base de données pour stocker les informations des utilisateurs nécessaires pour le rappel.
Démarrez le conteneur Redis.
docker run --name redis -p 6379:6379 -d redis:6.0.0Le processus consiste à charger le terme, le vecteur et le filtre de l'utilisateur dans Redis. Les données du terme et du vecteur sont générées dans la section 1.2, tandis que le filtre concerne les éléments avec lesquels l'utilisateur a déjà interagi. Ces articles filtrés sont exclus lors de la génération de recommandations.
Une fois les données chargées, une étape de validation sera effectuée en vérifiant les données d'un échantillon d'utilisateur. Une validation réussie sera indiquée par la sortie affichée ci-dessous.
cd offline_to_online/recall/
python s1_user_to_redis.py
Elasticsearch est utilisé pour créer à la fois l'index inversé et l'index vectoriel pour les éléments. Conçu à l'origine pour les applications de recherche, le cas d'utilisation fondamental d'Elasticsearch implique d'utiliser des mots pour récupérer des documents. Dans le contexte des systèmes de recommandation, nous traitons un élément comme un document, et ses termes, tels que les genres de films, comme des mots. Cela nous permet d'utiliser Elasticsearch pour récupérer des éléments en fonction de ces termes. Ce concept s'aligne sur la notion d'index inversés, faisant d'Elasticsearch un outil précieux pour le rappel des termes dans les systèmes de recommandation. Pour le rappel vectoriel, un outil couramment utilisé est FAISS open source de Facebook. Cependant, par souci de facilité d'intégration, nous avons choisi d'utiliser les capacités de récupération vectorielle d'Elasticsearch. Elasticsearch a pris en charge la récupération de vecteur depuis la version 7 et approximativement la récupération du voisin K-Dearest (ANN) depuis la version 8. Dans ce projet, nous installons une version d'Elasticsearch qui est 8 (ou supérieure). Ce choix est fait car une récupération précise de KNN ne peut souvent pas répondre aux exigences à faible latence d'un système en ligne.
Démarrez le conteneur ElasticSearch et entrez son terminal interne en exécutant les commandes suivantes.
docker run --name es8 -p 9200:9200 -it elasticsearch:8.8.0 Copiez le mot de passe affiché dans votre sortie de terminal (comme indiqué ci-dessous) et collez-le comme valeur pour ES_KEY dans le fichier data_exchange_center / constants.py. Cette étape est nécessaire car Elasticsearch a implémenté les exigences d'authentification de mot de passe à partir de la version 8.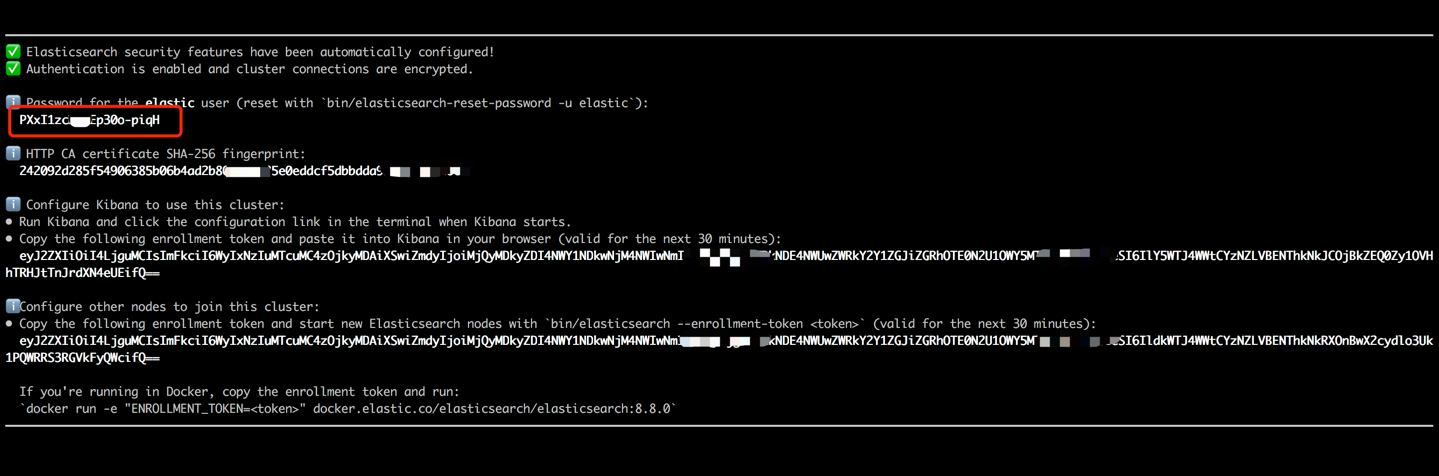
Une fois le mot de passe collé, quittez le terminal interne en utilisant le raccourci Ctrl + C (ou Command + C). Cette action arrêtera également le conteneur, nous devons donc redémarrer le conteneur Elasticsearch et nous assurer qu'il s'exécute en arrière-plan dans le cadre des étapes suivantes.
docker start es8Chargez les termes de l'élément pour créer l'index de terme et chargez les vecteurs d'élément pour créer l'index vectoriel. Dans les environnements industriels, ces deux indices sont généralement séparés pour de meilleures performances et flexibilité. Cependant, pour simplifier ce projet, nous les combinons en un seul indice.
Après le processus de chargement des données, une étape de validation sera effectuée en vérifiant le terme et le vecteur d'un échantillon. Une validation réussie sera indiquée par la sortie affichée ci-dessous.
cd offline_to_online/recall/
python s2_item_to_es.py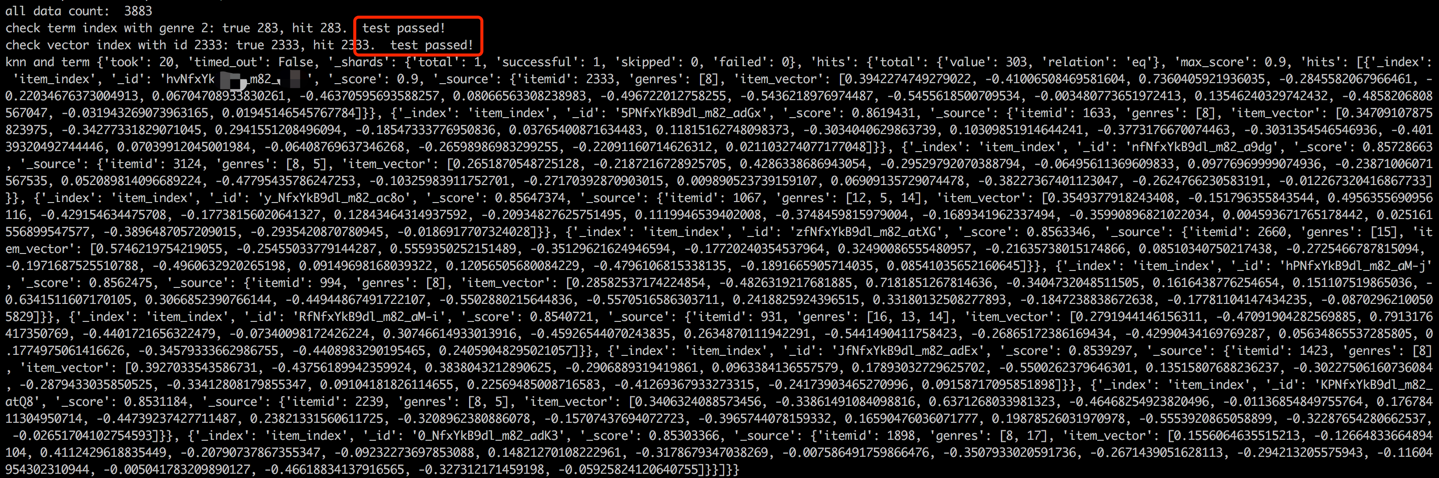
Feast est le magasin pionnier des fonctionnalités open-source, détenant une signification historique dans ce domaine. La fête comprend à la fois des composants hors ligne et en ligne. Le composant hors ligne facilite principalement les jointures ponctuelles. Cependant, puisque nous avons géré nous-mêmes des jointures de points dans Pandas, il n'est pas nécessaire d'utiliser les capacités hors ligne de Feast. Au lieu de cela, nous employons Feast comme boutique de fonctionnalités en ligne. La raison de ne pas utiliser de fête pour les jointures ponctuelles réside dans le fait que Feast propose principalement des capacités de stockage de fonctionnalités et manque de capacités d'ingénierie de caractéristiques (bien qu'il ait introduit certaines transformations de base dans les versions récentes). La plupart des entreprises préfèrent les moteurs de fonctionnalité personnalisés avec des capacités plus puissantes. Par conséquent, il n'est pas nécessaire d'investir beaucoup d'efforts dans l'apprentissage de l'utilisation hors ligne de la fête. Il est plus pratique d'employer des outils plus généraux tels que des pandas ou des étincelles pour le traitement des fonctionnalités et tirer parti de la fête uniquement en tant que composant pour transporter les fonctionnalités entre hors ligne et en ligne.
Convertissez les fichiers de fonctions de CSV en format Parquet pour répondre aux exigences de FEAST.
cd offline_to_online/rank/
python s1_feature_to_feast.pyOuvrez un nouveau terminal (appelé terminal 2), démarrez le conteneur de fête avec 6566 comme port HTTP et entrez son terminal interne en exécutant les commandes suivantes.
cd data_exchange_center/online/feast
docker run --rm --name feast-server --entrypoint " bash " -v $( pwd ) :/home/hs -p 6566:6566 -it feastdev/feature-server:0.31.0Exécutez les commandes suivantes dans le terminal interne du conteneur de fête.
# Enter the config directory
cd /home/hs/ml/feature_repo
# Initialize the feature store from config files (read parquet to build database)
feast apply
# Load features from offline to online (defaults to sqlite, with options like Redis available)
feast materialize-incremental " $( date + ' %Y-%m-%d %H:%M:%S ' ) "
# Start the feature server
feast serve -h 0.0.0.0 -p 6566Après avoir terminé toutes les étapes, la sortie suivante sera affichée.
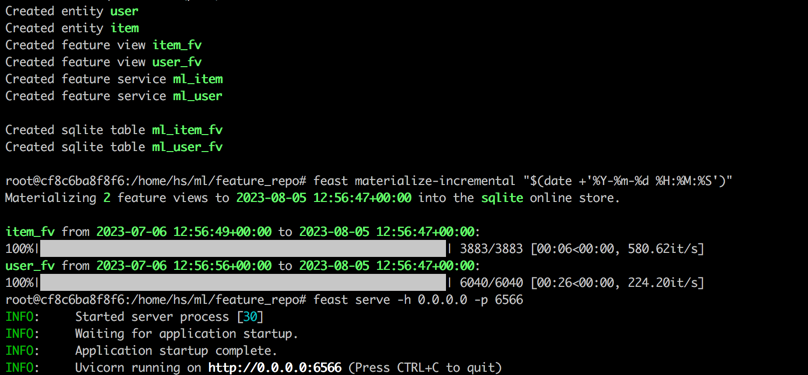
Retour au terminal 1, exécutez la commande suivante pour tester si FEAST sert correctement. Une chaîne JSON de réponse sera imprimée si elle réussit.
curl -X POST
" http://localhost:6566/get-online-features "
-d ' {
"feature_service": "ml_item",
"entities": {
"itemid": [1,3,5]
}
} ' Triton (Triton Inference Server) est un moteur de service d'inférence open source développé par NVIDIA. Triton Inference Server offre une prise en charge d'une gamme diversifiée de cadres tels que TensorFlow, Pytorch, ONNX et des options supplémentaires, ce qui en fait un excellent choix pour le service de modèle. Bien qu'il soit développé par Nvidia, Triton est suffisamment polyvalent pour servir avec des CPU, offrant une flexibilité dans son utilisation. Alors qu'une solution de l'industrie plus répandue implique TensorFlow -> SavedModel -> TensorFlow Serving, Triton gagne en popularité en raison de son adaptabilité dans la commutation entre différents cadres. Par conséquent, dans ce projet, nous adoptons un pipeline qui utilise Pytorch -> onnx -> Triton Server.
Convertissez le modèle Pytorch au format ONNX.
cd offline_to_online/rank/
python s2_model_to_triton.pyOuvrez un nouveau terminal (appelé terminal 3), démarrez le conteneur Triton avec 8000 comme port HTTP et 8001 comme port GRPC en exécutant les commandes suivantes.
cd data_exchange_center/online/triton
docker run --rm -p8000:8000 -p8001:8001 -p8002:8002 -v $( pwd ) /:/models/ nvcr.io/nvidia/tritonserver:20.12-py3 tritonserver --model-repository=/models/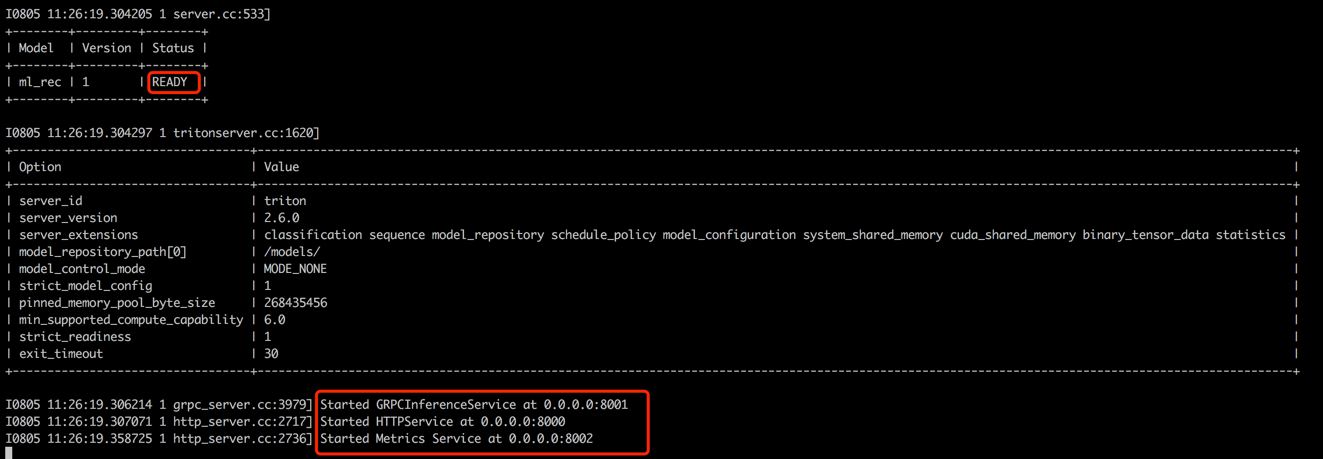
Retour au terminal 1, exécutez le script pour tester la cohérence entre les scores de prédiction hors ligne et en ligne. Cette étape aidera à garantir la fiabilité du système de recommandation.
cd offline_to_online/rank/
python s3_check_offline_and_online.pyComme indiqué ci-dessous, les scores hors ligne et en ligne sont identiques, indiquant la cohérence entre hors ligne et en ligne.

Dans les milieux industriels, les ingénieurs optent généralement pour Java + Springboot ou GO + Gin comme backend pour les systèmes de recommandation. Cependant, dans ce projet pour la facilité d'intégration, Python + Flask est utilisé. Il convient de noter qu'il existe plusieurs frameworks Web pour Python, notamment Django, Flask, Fastapi et Tornado, qui sont tous capables d'achever les demandes Restapi aux fonctions de traitement. Tous ces cadres pouvaient répondre à nos exigences, Flask a été sélectionné au hasard pour ce projet.
Ouvrez un nouveau terminal (appelé terminal 4), démarrez le serveur Web Flask avec 5000 comme port HTTP en exécutant les commandes suivantes.
conda activate rsppl
cd online/main
flask --app s1_server.py run --host=0.0.0.0
Retour au terminal 1 et effectuez un test en appelant le service de recommandation à partir d'un client (dans ce contexte, le client se réfère au service en amont qui appelle le service de recommandation, pas les appareils utilisateur). Les résultats seront renvoyés au format JSON, les 50 premiers ID d'élément recommandés affichés. Par la suite, le service en aval peut utiliser ces ID d'élément pour récupérer leurs attributs correspondants, puis les fournir au client (dans ce contexte, le périphérique utilisateur). Cela complète un flux de recommandation complet.
cd online/main
python s2_client.py


