recsys_pipeline
1.0.0
Inglés | 中文
Utilizando el conocido conjunto de datos de Movielens como ejemplo, presentaremos la tubería del sistema de recomendación de fuera de línea a línea, con todas las operaciones se pueden ejecutar en una sola computadora portátil. A pesar de la utilización de múltiples componentes, es importante tener en cuenta que todo está contenido en Conda y Docker, lo que no garantiza ningún impacto en el entorno local.
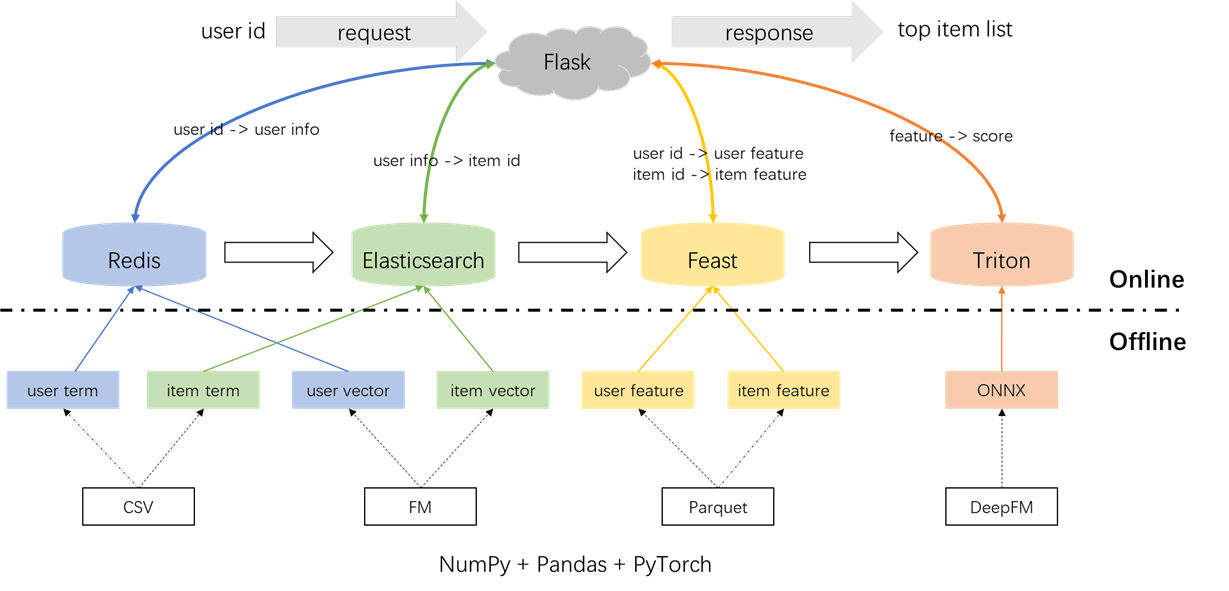
La arquitectura general del sistema de recomendación se ilustra a continuación. Ahora presentaremos los procesos de desarrollo e implementación para los módulos de retiro y clasificación en tres fases: fuera de línea, fuera de línea a línea y en línea.
conda create -n rsppl python=3.8
conda activate rsppl
conda install --file requirements.txt --channel anaconda --channel conda-forge cd offline/preprocess/
python s1_data_split.py
python s2_term_trans.pyPreprocesamiento de etiquetas, muestras y características:
Es importante resaltar el concepto de uniones de punto en el tiempo en el archivo s2_term_trans.py. Específicamente, durante la generación de muestras de entrenamiento fuera de línea (imp_term.pkl), se deben utilizar las características hasta el momento de la acción más cercana al momento presente. El uso de características después de este punto introduciría la fuga de características, mientras que usar características que están significativamente distantes en el tiempo desde el presente darían como resultado inconsistencias entre fuera de línea y en línea. Por el contrario, las características más recientes deben implementarse para servicio en línea (user_term.pkl y item_term.pkl).
cd offline/recall/
python s1_term_recall.py
python s2_vector_recall.pyRecuerdo del término: este componente utiliza las interacciones pasadas del usuario con elementos ('géneros) dentro de una ventana de tiempo especificada para que coincida con las preferencias del usuario con los elementos. Estos términos se cargarán en Redis y Elasticsearch más adelante.
Recuerdo de vectores: en este componente, se emplean FM (máquinas de factorización), utilizando solo la identificación de usuario y el ID de elemento como características. El AUC resultante (área debajo de la curva) = 0.8081. Al finalizar la fase de capacitación, los vectores de usuario y elemento se extraen del punto de control del modelo y se cargarán en Redis y Elasticsearch para la utilización posterior.
cd offline/rank/
python s1_feature_engi.py
python s2_model_train.pyEn total, hay 59 características que incluyen tres tipos: características únicas (como INSEREDID, ItemId, Género, etc.), características múltiples (géneros) y características densas (estadísticas de comportamiento históricas).
El modelo de clasificación empleado es DeepFM, logrando un AUC de 0.8206. Si bien Pytorch-FM es un paquete elegante para algoritmos basados en FM, tiene dos limitaciones: 1. Apoya exclusivamente características escasas y carece de soporte para características densas. 2. Todas las características escasas comparten la misma dimensión, lo que viola la intuición de que "los incrustaciones de identificación deben ser de alta dimensión, mientras que las incrustaciones de información lateral deben ser de baja dimensión". Para abordar estas restricciones, realizamos modificaciones en el código fuente, permitiendo el soporte tanto para las características densas como para las variables dimensiones de incrustación para características escasas. Además, se observó que el módulo de incrustación profunda afectó negativamente el rendimiento del modelo, lo que provocó su eliminación del modelo. Como resultado, la estructura del modelo actual consiste principalmente en un módulo FM escaso integrado con un MLP denso, no es un profundo convencional.
Para evitar cualquier impacto en el entorno local, Redis, Elasticsearch, Feast y Triton se emplean dentro de los contenedores Docker. Para continuar, asegúrese de que Docker se haya instalado en su computadora portátil y luego ejecute los siguientes comandos para descargar las imágenes de Docker respectivas.
docker pull redis:6.0.0
docker pull elasticsearch:8.8.0
docker pull feastdev/feature-server:0.31.0
docker pull nvcr.io/nvidia/tritonserver:20.12-py3Redis se utiliza como una base de datos para almacenar la información del usuario necesaria para el retiro.
Comience el contenedor Redis.
docker run --name redis -p 6379:6379 -d redis:6.0.0El proceso implica cargar el término, el vector y el filtro del usuario en Redis. El término y los datos vectoriales se generan en la Sección 1.2, mientras que el filtro se refiere a elementos con los que el usuario ha interactuado previamente. Estos elementos filtrados se excluyen al generar recomendaciones.
Una vez que se cargan los datos, se llevará a cabo un paso de validación verificando los datos para un usuario de muestra. Una validación exitosa se indicará mediante la salida que se muestra a continuación.
cd offline_to_online/recall/
python s1_user_to_redis.py
Elasticsearch se emplea para crear un índice invertido e índice vectorial para elementos. Diseñado originalmente para aplicaciones de búsqueda, el caso de uso fundamental de Elasticsearch implica el uso de palabras para recuperar documentos. En el contexto de los sistemas de recomendación, tratamos un elemento como documento, y sus términos, como géneros de películas, como palabras. Esto nos permite usar Elasticsearch para recuperar elementos según estos términos. Este concepto se alinea con la noción de índices invertidos, lo que hace de Elasticsearch una herramienta valiosa para el retiro de términos en los sistemas de recomendación. Para el retiro de Vector, una herramienta de uso común es el FAISS de código abierto de Facebook. Sin embargo, en aras de la facilidad de integración, hemos optado por utilizar las capacidades de recuperación de vectores de Elasticsearch. Elasticsearch ha admitido la recuperación de vectores desde la Versión 7, y la recuperación aproximada de K-Nearest Vecin (ANN) desde la versión 8. En este proyecto, instalamos una versión de ElasticSearch que es 8 (o superior). Esta elección se realiza porque la recuperación precisa de KNN a menudo no puede cumplir con los requisitos de baja latencia de un sistema en línea.
Inicie el contenedor Elasticsearch e ingrese su terminal interno ejecutando los siguientes comandos.
docker run --name es8 -p 9200:9200 -it elasticsearch:8.8.0 Copie la contraseña que se muestra en la salida de su terminal (como se indica a continuación) y péguela como el valor para ES_KEY en el archivo data_exchange_center/constants.py. Este paso es necesario porque Elasticsearch ha implementado requisitos de autenticación de contraseña a partir de la versión 8.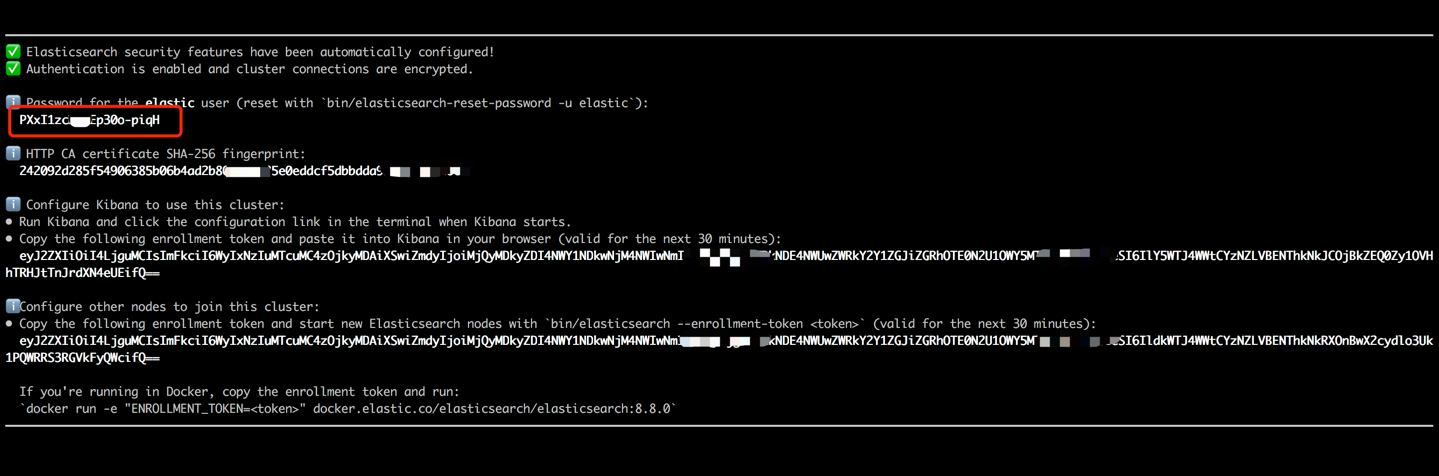
Una vez que se haya pegado la contraseña, salga del terminal interno utilizando el acceso directo del teclado Ctrl+C (o comando+c). Esta acción también detendrá el contenedor, por lo que necesitamos reiniciar el contenedor Elasticsearch y asegurar que se ejecute en segundo plano como parte de los pasos posteriores.
docker start es8Cargue los términos del elemento para crear el índice de término y cargue los vectores de elementos para crear el índice vectorial. En entornos industriales, estos dos índices generalmente se separan para un mejor rendimiento y flexibilidad. Sin embargo, por simplicidad en este proyecto, los estamos combinando en un solo índice.
Después del proceso de carga de datos, se llevará a cabo un paso de validación verificando el término y el vector de un elemento de muestra. Una validación exitosa se indicará mediante la salida que se muestra a continuación.
cd offline_to_online/recall/
python s2_item_to_es.py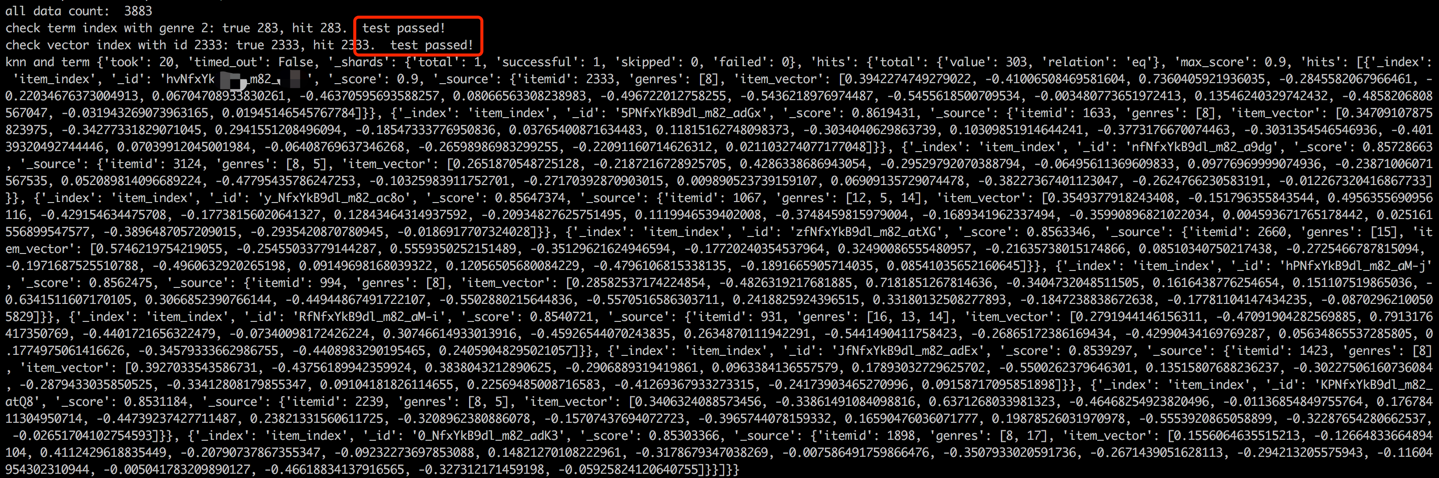
La fiesta se erige como la tienda de funciones de código abierto pionero, que tiene importancia histórica en este dominio. Feast incluye componentes fuera de línea y en línea. El componente fuera de línea facilita principalmente las uniones de punto en el tiempo. Sin embargo, dado que hemos gestionado uniones de punto en tiempo en Pandas nosotros mismos, no es necesario utilizar las capacidades fuera de línea de Feast. En cambio, empleamos la fiesta como una tienda de funciones en línea. La razón detrás de no usar Feast for Point-in-Time se une en el hecho de que Feast ofrece principalmente capacidades de almacenamiento de características y carece de capacidades de ingeniería de características (aunque ha introducido algunas transformaciones básicas en las versiones recientes). La mayoría de las empresas prefieren motores de características personalizados con capacidades más potentes. Por lo tanto, no hay necesidad de invertir mucho esfuerzo en el uso de uso fuera de línea de la fiesta. Es más práctico emplear herramientas más generales como pandas o chispa para el procesamiento de características y el festín de apalancamiento únicamente como un componente para transportar características entre fuera de línea y en línea.
Convierta los archivos de características de CSV a formato Parquet para cumplir con los requisitos de la fiesta.
cd offline_to_online/rank/
python s1_feature_to_feast.pyAbra un nuevo terminal (llamado terminal 2), inicie el contenedor de fiesta con 6566 como el puerto HTTP e ingrese su terminal interno ejecutando los siguientes comandos.
cd data_exchange_center/online/feast
docker run --rm --name feast-server --entrypoint " bash " -v $( pwd ) :/home/hs -p 6566:6566 -it feastdev/feature-server:0.31.0Ejecute los siguientes comandos en el terminal interno del contenedor de fiesta.
# Enter the config directory
cd /home/hs/ml/feature_repo
# Initialize the feature store from config files (read parquet to build database)
feast apply
# Load features from offline to online (defaults to sqlite, with options like Redis available)
feast materialize-incremental " $( date + ' %Y-%m-%d %H:%M:%S ' ) "
# Start the feature server
feast serve -h 0.0.0.0 -p 6566Después de completar todos los pasos, se mostrará la siguiente salida.
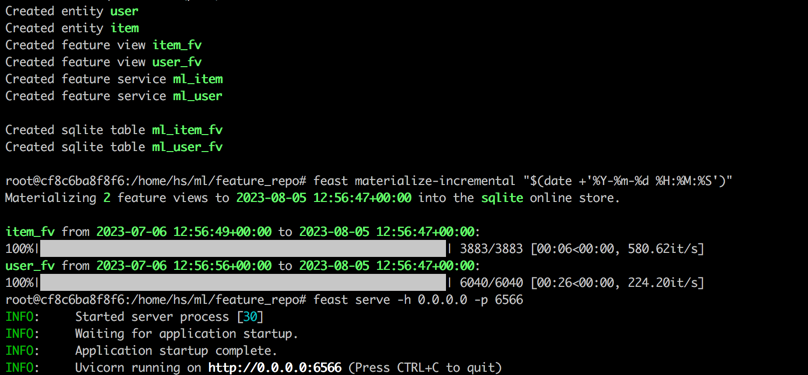
Volver a la Terminal 1, ejecute el siguiente comando para probar si la fiesta está sirviendo correctamente. Se imprimirá una cadena de respuesta JSON si es correctamente.
curl -X POST
" http://localhost:6566/get-online-features "
-d ' {
"feature_service": "ml_item",
"entities": {
"itemid": [1,3,5]
}
} ' Triton (Triton Inference Server) es un motor de servicio de inferencia de código abierto desarrollado por NVIDIA. Triton Inference Server ofrece soporte para una amplia gama de marcos como TensorFlow, Pytorch, ONNX y opciones adicionales, lo que lo convierte en una excelente opción para el servicio de modelo. A pesar de que está desarrollado por Nvidia, Triton es lo suficientemente versátil como para servir con CPU, ofreciendo flexibilidad en su uso. Si bien una solución de la industria más prevalente implica TensorFlow -> SavedModel -> TensorFlow Serving, Triton está ganando popularidad debido a su adaptabilidad en el cambio entre diferentes marcos. Por lo tanto, en este proyecto, adoptamos una tubería que utiliza Pytorch -> Onnx -> Triton Server.
Convierta el modelo Pytorch en formato ONNX.
cd offline_to_online/rank/
python s2_model_to_triton.pyAbra un nuevo terminal (llamado Terminal 3), inicie el contenedor Triton con 8000 como el puerto HTTP y 8001 como el puerto GRPC ejecutando los siguientes comandos.
cd data_exchange_center/online/triton
docker run --rm -p8000:8000 -p8001:8001 -p8002:8002 -v $( pwd ) /:/models/ nvcr.io/nvidia/tritonserver:20.12-py3 tritonserver --model-repository=/models/
De vuelta a la Terminal 1, ejecute el script para probar la consistencia entre los puntajes de predicción fuera de línea y en línea. Este paso ayudará a garantizar la confiabilidad del sistema de recomendación.
cd offline_to_online/rank/
python s3_check_offline_and_online.pyComo se muestra a continuación, los puntajes fuera de línea y en línea son idénticos, lo que indica la consistencia entre fuera de línea y en línea.

En entornos industriales, los ingenieros comúnmente optan por Java + Springboot o Go + Gin como el backend para los sistemas de recomendación. Sin embargo, en este proyecto en aras de la facilidad de integración, se utiliza Python + Flask. Vale la pena señalar que hay varios marcos web para Python, incluidos Django, Flask, Fastapi y Tornado, todos capaces de enrutar las solicitudes de RaTapi a las funciones para el procesamiento. Cualquiera de estos marcos podría cumplir con nuestros requisitos, Flask fue seleccionado al azar para este proyecto.
Abra un nuevo terminal (llamado terminal 4), inicie el servidor web de frasco con 5000 como el puerto HTTP ejecutando los siguientes comandos.
conda activate rsppl
cd online/main
flask --app s1_server.py run --host=0.0.0.0
Volver a la Terminal 1 y realizar una prueba llamando al servicio de recomendación de un cliente (en este contexto, el cliente se refiere al servicio aguas arriba que llama al servicio de recomendación, no a los dispositivos de usuario). Los resultados se devolverán en formato JSON, con los 50 principales ID de elemento recomendado que se muestran. Posteriormente, el servicio posterior puede usar estos ID de elemento para recuperar sus atributos correspondientes y luego proporcionarlos al cliente (en este contexto, dispositivo de usuario). Esto completa un flujo de recomendación completo.
cd online/main
python s2_client.py


