recsys_pipeline
1.0.0
英语| 中文
以著名的Movielens数据集为例,我们将介绍从离线到在线的推荐系统管道,所有操作都可以在单个笔记本电脑上执行。尽管使用了多个组件,但必须注意,所有内容都包含在康达(Conda)和码头(Docker)内,从而确保对当地环境没有影响。
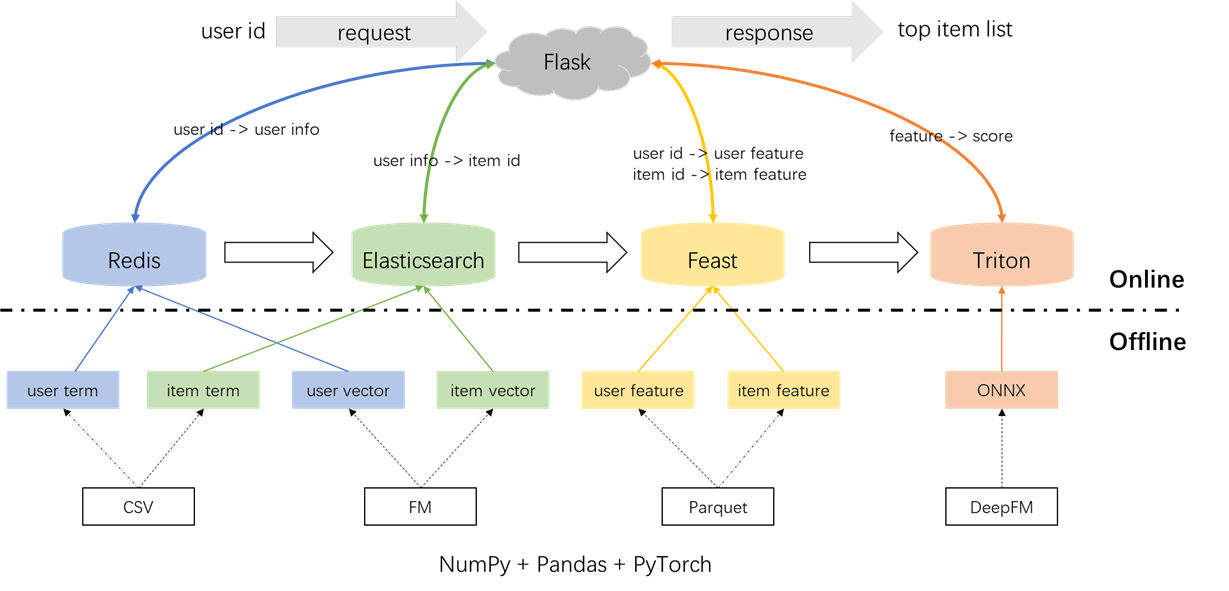
建议系统的整体体系结构如下所示。现在,我们将介绍三个阶段的召回和排名模块的开发和部署流程:离线,离线到线和在线。
conda create -n rsppl python=3.8
conda activate rsppl
conda install --file requirements.txt --channel anaconda --channel conda-forge cd offline/preprocess/
python s1_data_split.py
python s2_term_trans.py标签,样本和功能的预处理:
重要的是要突出显示在s2_term_trans.py文件中加入时间点的概念。具体来说,在生成离线培训样本(IMP_TERM.PKL)期间,应使用最接近当前时刻的动作时间。此后使用功能会引入功能泄漏,而使用与当前时间相距明显遥远的功能会导致离线和在线之间的不一致。相比之下,最新功能应用于在线服务(user_term.pkl和item_term.pkl)。
cd offline/recall/
python s1_term_recall.py
python s2_vector_recall.py术语召回:此组件利用用户在指定的时间窗口中与项目('类型)的过去交互,以将用户首选项与项目匹配。这些术语将在稍后将其加载到Redis和Elasticsearch中。
向量回忆:在此组件中,使用FM(分分计算机),仅利用用户ID和项目ID作为功能。所得的AUC(曲线下的区域)= 0.8081。训练阶段完成后,从模型检查点提取了用户和项目向量,并将加载到Redis和Elasticsearch中以进行后续利用。
cd offline/rank/
python s1_feature_engi.py
python s2_model_train.py总共有59个功能,其中包括三种类型:一hot功能(例如UserID,itemID,性别等),多热功能(类型)和密集的功能(历史行为统计)。
采用的排名模型是DEEPFM,AUC为0.8206。尽管Pytorch-FM是用于基于FM的算法的优雅软件包,但它具有两个限制:1。它仅支持稀疏功能,缺乏对密集功能的支持。 2。所有稀疏特征都具有相同的维度,这违反了直觉,即“ ID嵌入应具有高维度,而侧面信息嵌入应具有低维度。”。为了解决这些约束,我们对源代码进行了修改,为稀疏功能提供了支持,并为稀疏特征的嵌入尺寸变化。此外,注意到,深层嵌入模块对模型性能产生负面影响,这促使其从模型中删除。结果,当前的模型结构主要由与密度MLP集成的稀疏FM模块组成,它不是常规的DEEPFM。
为了防止对当地环境的任何影响,Redis,Elasticsearch,Feast和Triton都在Docker容器中使用。要继续进行,请确保将Docker安装在笔记本电脑上,然后执行以下命令以下载相应的Docker映像。
docker pull redis:6.0.0
docker pull elasticsearch:8.8.0
docker pull feastdev/feature-server:0.31.0
docker pull nvcr.io/nvidia/tritonserver:20.12-py3Redis被用作数据库,用于存储召回所需的用户信息。
启动Redis容器。
docker run --name redis -p 6379:6379 -d redis:6.0.0该过程涉及加载用户的术语,向量和过滤到redis。术语和矢量数据是在第1.2节中生成的,而过滤器与用户以前与之交互的项目有关。在生成建议时,这些过滤项目被排除在外。
加载数据后,将通过检查示例用户的数据来执行验证步骤。成功的验证将由下面显示的输出表示。
cd offline_to_online/recall/
python s1_user_to_redis.py
Elasticsearch被用来为项目创建倒索引和向量索引。 Elasticsearch的基本用例最初是为搜索应用程序而设计的,涉及使用单词检索文档。在推荐系统的背景下,我们将项目视为文档及其术语,例如电影类型,作为单词。这使我们可以使用Elasticsearch根据这些术语来检索项目。这个概念与倒置索引的概念保持一致,这使Elasticsearch成为推荐系统中术语召回的有价值的工具。对于矢量召回,一种常用的工具是Facebook的开源faiss。但是,为了易于集成,我们选择利用Elasticsearch的向量检索功能。 Elasticsearch自第7版以来一直支持向量检索,并且自版本8版以来近似K-Nearest邻居(ANN)检索。在此项目中,我们安装了8(或更高)的Elasticsearch版本。之所以做出选择,是因为精确的KNN检索通常无法满足在线系统的低延迟要求。
启动Elasticsearch容器,并通过执行以下命令输入其内部终端。
docker run --name es8 -p 9200:9200 -it elasticsearch:8.8.0复制终端输出中显示的密码(如下所示),并将其粘贴为data_exchange_center/startants.py文件中的es_key的值。此步骤是必要的,因为Elasticsearch已从版本8开始实现密码身份验证要求。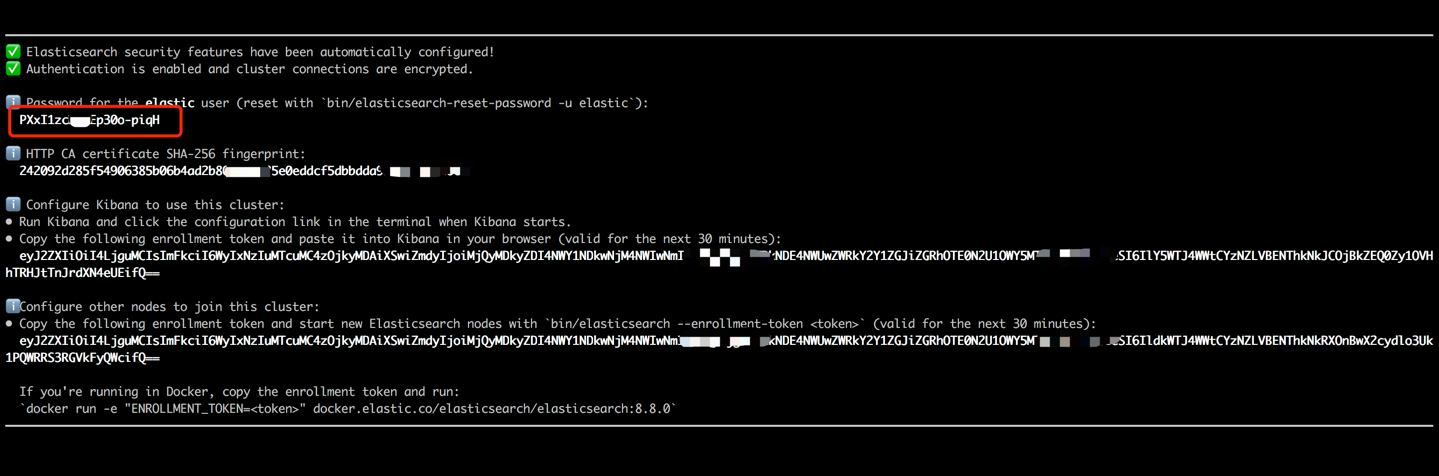
粘贴密码后,使用CTRL+C(或命令+C)键盘快捷键退出内部终端。此操作还将停止容器,因此我们需要重新启动Elasticsearch容器,并确保其作为后续步骤的一部分在后台运行。
docker start es8加载项目项以创建术语索引并加载项目向量以创建向量索引。在工业环境中,这两个索引通常分开以提高性能和灵活性。但是,为了简单,我们将它们组合成一个索引。
在数据加载过程之后,将通过检查示例项目的项和向量来执行验证步骤。成功的验证将由下面显示的输出表示。
cd offline_to_online/recall/
python s2_item_to_es.py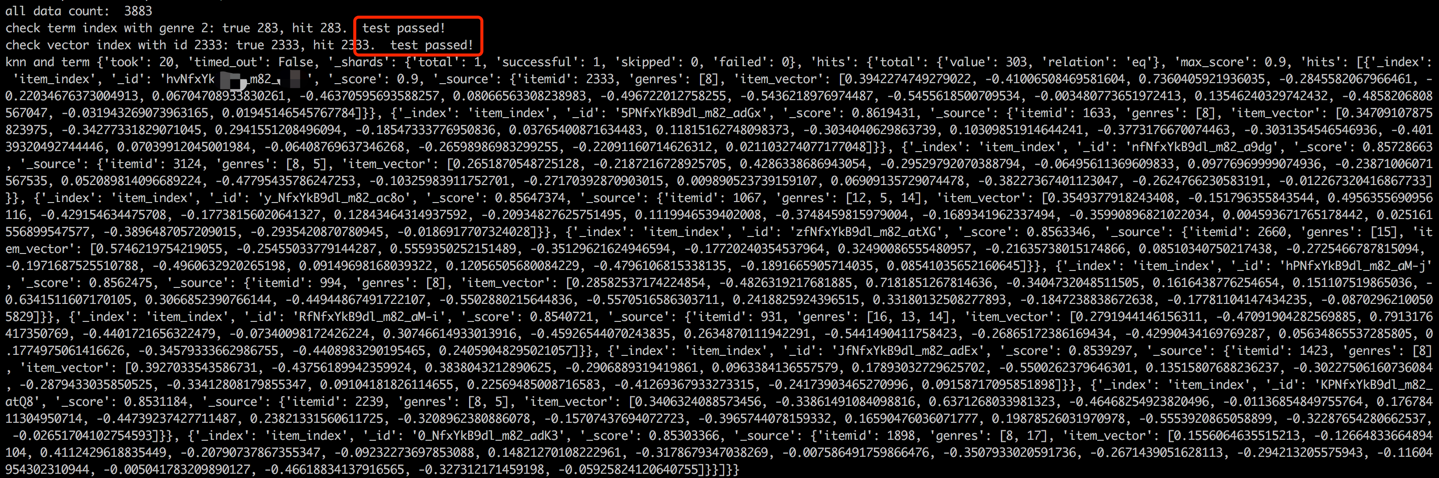
盛宴是开拓开源商店的开创性,在该领域具有历史意义。盛宴包括离线和在线组件。离线组件主要促进了时间点加入。但是,由于我们自己管理了熊猫的时间点,因此无需使用盛宴的离线功能。相反,我们将盛宴用作在线功能商店。不使用盛宴进行点数的原因背后的原因在于,盛宴主要提供功能功能,并且缺乏功能工程功能(尽管它在最近的版本中引入了一些基本转换)。大多数公司都喜欢具有更强大功能的定制功能引擎。因此,无需在学习盛宴的离线使用方面投入太多努力。使用更多的通用工具(例如Pandas或Spark)进行功能处理和利用盛宴更为实用,仅作为离线和在线之间运输功能的组成部分。
将功能文件从CSV转换为Parquet格式,以满足盛宴的要求。
cd offline_to_online/rank/
python s1_feature_to_feast.py打开一个新的终端(称为终端2),以6566作为HTTP端口启动盛宴容器,并通过执行以下命令进入其内部终端。
cd data_exchange_center/online/feast
docker run --rm --name feast-server --entrypoint " bash " -v $( pwd ) :/home/hs -p 6566:6566 -it feastdev/feature-server:0.31.0在盛宴容器的内部终端中执行以下命令。
# Enter the config directory
cd /home/hs/ml/feature_repo
# Initialize the feature store from config files (read parquet to build database)
feast apply
# Load features from offline to online (defaults to sqlite, with options like Redis available)
feast materialize-incremental " $( date + ' %Y-%m-%d %H:%M:%S ' ) "
# Start the feature server
feast serve -h 0.0.0.0 -p 6566完成所有步骤后,将显示以下输出。
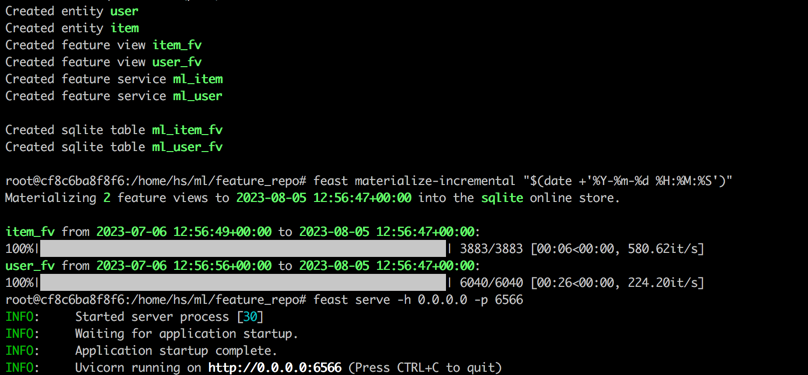
返回终端1,执行以下命令,以测试盛宴是否正确使用。如果成功的话,将打印响应JSON字符串。
curl -X POST
" http://localhost:6566/get-online-features "
-d ' {
"feature_service": "ml_item",
"entities": {
"itemid": [1,3,5]
}
} ' Triton(Triton推理服务器)是由Nvidia开发的开源推理服务引擎。 Triton推理服务器为各种框架提供了支持,例如Tensorflow,Pytorch,OnNX和其他选项,使其成为模型服务的绝佳选择。尽管Triton是由NVIDIA开发的,但它的用途足够多,可以与CPU一起使用,并提供了灵活性。虽然更普遍的行业解决方案涉及张量 - > SavedModel-> TensorFlow服务,但由于其在不同框架之间切换方面的适应性,Triton却越来越受欢迎。因此,在这个项目中,我们采用了使用Pytorch-> onnx-> Triton Server的管道。
将Pytorch模型转换为ONNX格式。
cd offline_to_online/rank/
python s2_model_to_triton.py打开一个新的终端(称为终端3),通过执行以下命令,以8000作为HTTP端口的Triton容器作为HTTP端口和8001作为GRPC端口。
cd data_exchange_center/online/triton
docker run --rm -p8000:8000 -p8001:8001 -p8002:8002 -v $( pwd ) /:/models/ nvcr.io/nvidia/tritonserver:20.12-py3 tritonserver --model-repository=/models/
返回终端1,运行脚本以测试离线和在线预测分数之间的一致性。此步骤将有助于确保推荐系统的可靠性。
cd offline_to_online/rank/
python s3_check_offline_and_online.py如下所示,离线和在线分数相同,表明离线和在线之间的一致性。

在工业环境中,工程师通常选择Java + Springboot或Go + Gin作为推荐系统的后端。但是,为了使集成容易,在此项目中,使用Python +烧瓶。值得注意的是,Python有几个Web框架,包括Django,Flask,Fastapi和Tornado,所有这些都能够将RESTAPI请求路由到处理功能。这些框架中的任何一个都可以满足我们的要求,该项目随机选择了烧瓶。
打开一个新的终端(称为终端4),通过执行以下命令,以5000作为HTTP端口启动烧瓶Web服务器。
conda activate rsppl
cd online/main
flask --app s1_server.py run --host=0.0.0.0
返回终端1,并通过从客户端调用推荐服务进行测试(在此上下文中,客户介绍了调用建议服务而不是用户设备的上游服务)。结果将以JSON格式返回,并显示前50个项目ID。随后,下游服务可以使用这些项目ID检索其相应的属性,然后将其提供给客户端(在此上下文中,用户设备)。这完成了完整的建议流。
cd online/main
python s2_client.py


