recsys_pipeline
1.0.0
영어 | 中文
잘 알려진 Movielens 데이터 세트를 예로 사용하면 오프라인에서 온라인으로 추천 시스템 파이프 라인을 소개하며 모든 작업은 단일 랩톱에서 실행할 수 있습니다. 여러 구성 요소의 활용에도 불구하고 모든 것이 Conda와 Docker 내에 포함되어있어 지역 환경에 영향을 미치지 않는다는 점에 유의해야합니다.
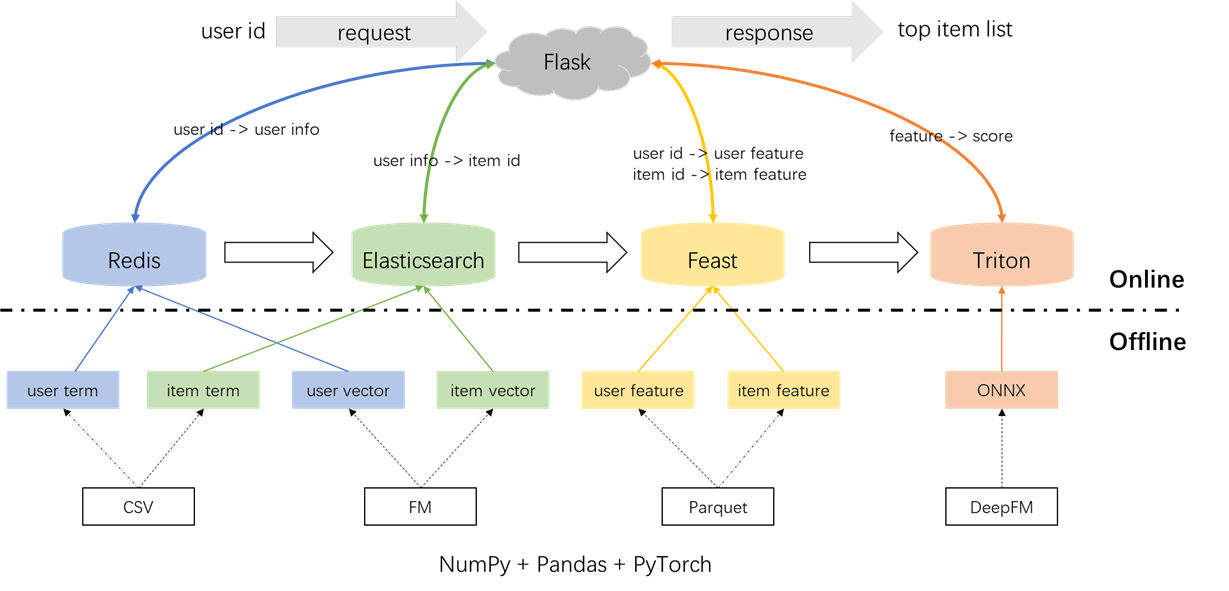
추천 시스템의 전체 아키텍처는 다음과 같습니다. 이제 우리는 오프라인, 오프라인에서 온라인 및 온라인의 세 단계에서 리콜 및 순위 모듈에 대한 개발 및 배포 프로세스를 소개합니다.
conda create -n rsppl python=3.8
conda activate rsppl
conda install --file requirements.txt --channel anaconda --channel conda-forge cd offline/preprocess/
python s1_data_split.py
python s2_term_trans.py레이블, 샘플 및 기능의 전처리 :
s2_term_trans.py 파일에서 Point-in-Time 조인 개념을 강조하는 것이 중요합니다. 구체적으로, 오프라인 훈련 샘플 (IMP_TERM.PKL)의 생성 동안 현재 순간에 가장 가까운 행동 시간을 포함하여 기능을 사용해야합니다. 이 시점 이후 기능을 사용하면 기능 누출이 발생하는 반면, 현재와 시간이 크게 먼 기능을 사용하면 오프라인과 온라인 사이의 불일치가 발생합니다. 대조적으로, 최신 기능은 온라인 서빙 (user_term.pkl 및 item_term.pkl)에 배포되어야합니다.
cd offline/recall/
python s1_term_recall.py
python s2_vector_recall.py용어 리콜 :이 구성 요소는 지정된 시간 창 내에서 항목 (장르)과의 과거의 상호 작용을 사용하여 항목과의 사용자 기본 설정과 일치합니다. 이 용어는 나중에 Redis 및 Elasticsearch에로드됩니다.
벡터 리콜 :이 구성 요소에서 FM (Factorization Machines)이 사용되며 사용자 ID와 항목 ID 만 기능으로 사용됩니다. 결과 AUC (곡선 아래 영역) = 0.8081. 훈련 단계가 완료되면, 사용자 및 항목 벡터는 모델 체크 포인트에서 추출되며 후속 활용을 위해 Redis 및 Elasticsearch에로드됩니다.
cd offline/rank/
python s1_feature_engi.py
python s2_model_train.py전체적으로 1 가지 유형의 기능 (예 : UserID, itemId, 성별 등), 멀티 핫 기능 (장르) 및 조밀 한 기능 (역사적 행동 통계)을 포함한 59 가지 기능이 있습니다.
사용 된 순위 모델은 DEEPFM이며 0.8206의 AUC를 달성합니다. Pytorch-FM은 FM 기반 알고리즘을위한 우아한 패키지이지만 두 가지 제한 사항이 있습니다. 1. 스파 스 기능을 독점적으로 지원하고 밀집된 기능에 대한 지원이 부족합니다. 2. 모든 스파 스 피처는 동일한 차원을 공유하며, 이는 "ID 임베드는 고차원이어야하며 측면 정보 임베드는 저 차원이어야한다"는 직관을 위반합니다. 이러한 제약 조건을 해결하기 위해 소스 코드를 수정하여 밀도가 높은 기능과 스파 스 기능에 대한 다양한 임베딩 크기를 지원할 수 있습니다. 또한, 깊은 임베딩 모듈은 모델 성능에 부정적인 영향을 미쳤으며, 이는 모델에서 제거를 촉발시켰다. 결과적으로, 현재 모델 구조는 주로 밀도가 높은 MLP와 통합 된 드문 드문 FM 모듈로 구성되며, 기존의 DEEPFM이 아닙니다.
지역 환경에 미치는 영향을 방지하기 위해 Redis, Elasticsearch, Feast 및 Triton은 모두 Docker 컨테이너에 사용됩니다. 진행하려면 Docker가 랩톱에 설치되었는지 확인한 다음 다음 명령을 실행하여 해당 Docker 이미지를 다운로드하십시오.
docker pull redis:6.0.0
docker pull elasticsearch:8.8.0
docker pull feastdev/feature-server:0.31.0
docker pull nvcr.io/nvidia/tritonserver:20.12-py3Redis는 리콜에 필요한 사용자 정보를 저장하기위한 데이터베이스로 사용됩니다.
Redis 컨테이너를 시작하십시오.
docker run --name redis -p 6379:6379 -d redis:6.0.0프로세스에는 사용자의 용어, 벡터 및 필터를 Redis에로드하는 것이 포함됩니다. 용어 및 벡터 데이터는 섹션 1.2에서 생성되며 필터는 사용자가 이전에 상호 작용 한 항목과 관련이 있습니다. 이 필터링 된 항목은 권장 사항을 생성 할 때 제외됩니다.
데이터가로드되면 샘플 사용자의 데이터를 확인하여 유효성 검사 단계가 수행됩니다. 성공적인 검증은 아래에 표시된 출력으로 표시됩니다.
cd offline_to_online/recall/
python s1_user_to_redis.py
Elasticsearch는 항목의 역 지수와 벡터 인덱스를 모두 생성하기 위해 사용됩니다. 원래 검색 응용 프로그램을 위해 설계된 Elasticsearch의 기본 사용 사례에는 단어를 사용하여 문서를 검색하는 것이 포함됩니다. 추천 시스템의 맥락에서, 우리는 항목을 문서로, 영화 장르와 같은 용어를 단어로 취급합니다. 이를 통해 ElasticSearch를 사용 하여이 용어에 따라 항목을 검색 할 수 있습니다. 이 개념은 거꾸로 된 색인의 개념과 일치하며, Elasticsearch는 추천 시스템에서 용어 리콜을위한 귀중한 도구로 만듭니다. 벡터 리콜의 경우 일반적으로 사용되는 도구는 Facebook의 오픈 소스 Faiss입니다. 그러나 통합의 용이성을 위해 Elasticsearch의 벡터 검색 기능을 활용하기로 결정했습니다. Elasticsearch는 버전 7 이후 벡터 검색을 지원했으며 버전 8 이후 k-nearest 이웃 (ANN) 검색을 지원했습니다.이 프로젝트에서는 Elasticsearch 버전을 8 (또는 더 높은)을 설치합니다. 이 선택은 정확한 KNN 검색이 종종 온라인 시스템의 저렴한 요구 사항을 충족시킬 수 없기 때문에 이루어집니다.
Elasticsearch 컨테이너를 시작하고 다음 명령을 실행하여 내부 터미널을 입력하십시오.
docker run --name es8 -p 9200:9200 -it elasticsearch:8.8.0 터미널 출력에 표시된 비밀번호를 복사하여 (아래에 표시된대로) Data_ExChange_Center/Constants.py 파일에서 ES_KEY 값으로 붙여 넣습니다. Elasticsearch가 버전 8에서 시작하는 비밀번호 인증 요구 사항을 구현 했으므로이 단계가 필요합니다.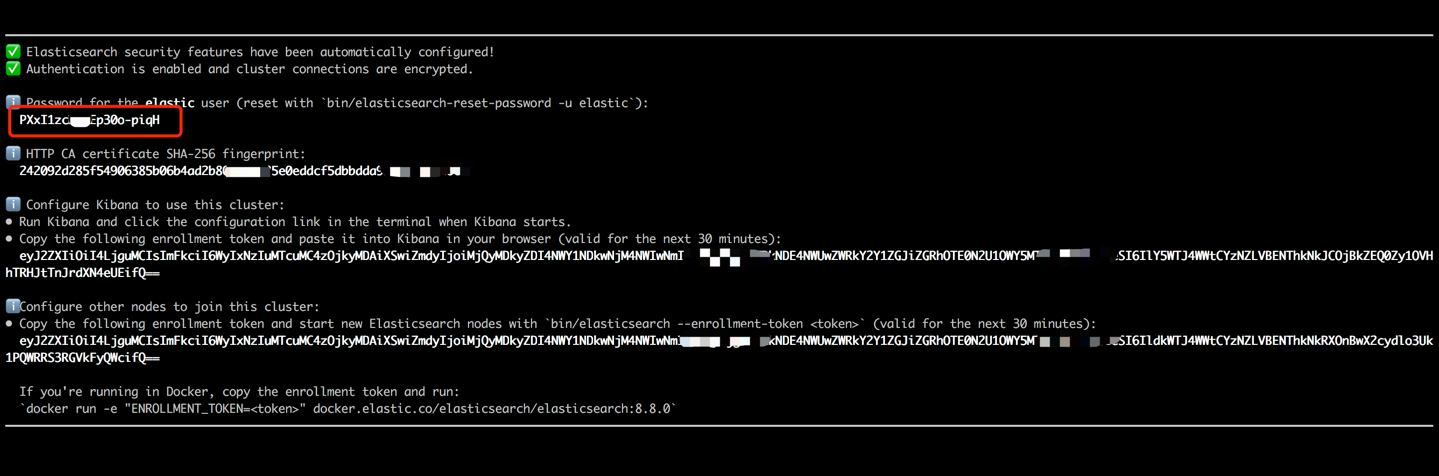
암호가 붙여 넣으면 Ctrl+C (또는 Command+C) 키보드 단축키를 사용하여 내부 터미널을 종료하십시오. 이 동작은 또한 컨테이너를 중지하므로 Elasticsearch 컨테이너를 다시 시작하고 후속 단계의 일부로 백그라운드에서 실행되는지 확인해야합니다.
docker start es8항목 용어를로드하여 용어 색인을 생성하고 항목 벡터를로드하여 벡터 인덱스를 만듭니다. 산업 환경에서,이 두 인덱스는 일반적으로 성능과 유연성을 향상시키기 위해 분리되어 있습니다. 그러나이 프로젝트의 단순성을 위해 단일 인덱스로 결합하고 있습니다.
데이터 로딩 프로세스에 이어 샘플 항목의 용어 및 벡터를 확인하여 유효성 검사 단계가 수행됩니다. 성공적인 검증은 아래에 표시된 출력으로 표시됩니다.
cd offline_to_online/recall/
python s2_item_to_es.py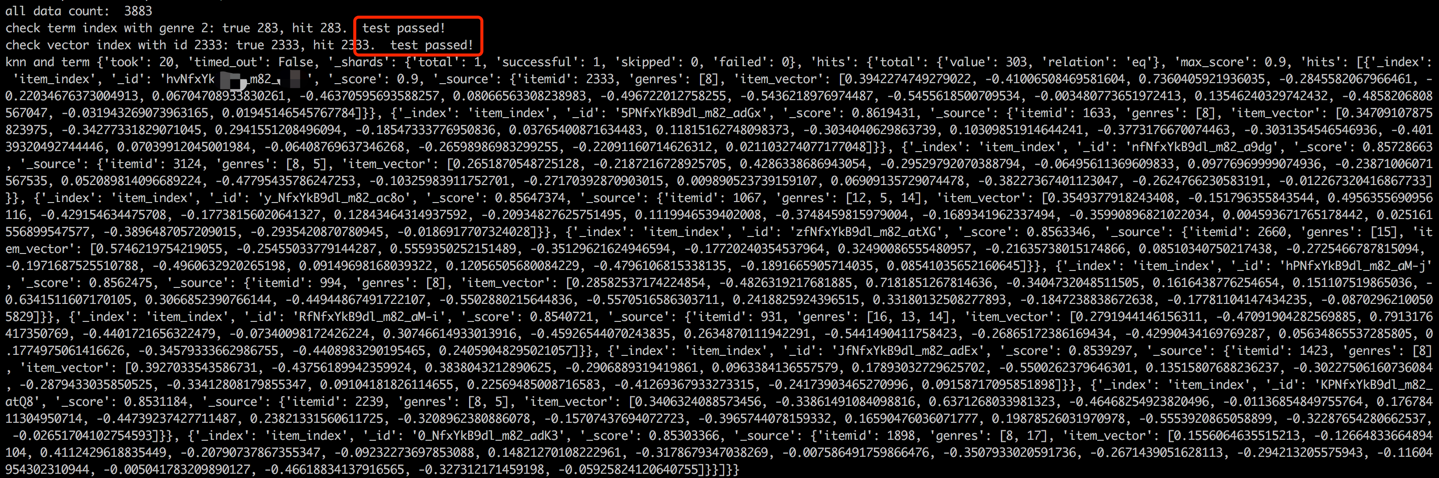
축제는 선구적인 오픈 소스 기능 상점으로 서 있으며,이 영역에서 역사적 중요성을 유지합니다. 축제에는 오프라인 및 온라인 구성 요소가 모두 포함됩니다. 오프라인 구성 요소는 주로 시점 조인을 용이하게합니다. 그러나 우리는 팬더에서 시점 조인을 관리 했으므로 Feast의 오프라인 기능을 활용할 필요는 없습니다. 대신, 우리는 Feast를 온라인 기능 상점으로 고용합니다. Feast가 주로 기능 저장 기능을 제공하고 기능 엔지니어링 기능이 부족하다는 사실에 있습니다 (최근 버전에서 일부 기본 변환을 도입했지만). 대부분의 회사는보다 강력한 기능을 갖춘 맞춤형 기능 엔진을 선호합니다. 따라서 잔치의 오프라인 사용을 배우는 데 많은 노력을 기울일 필요가 없습니다. 피처 처리를 위해 팬더 또는 스파크와 같은보다 일반적인 도구를 사용하는 것이 더 실용적이며 오프라인과 온라인 사이의 기능을 전송하기위한 구성 요소 로서만 축제를 활용하는 것이 더 실용적입니다.
Feast의 요구 사항을 충족하기 위해 기능 파일을 CSV에서 Parquet 형식으로 변환하십시오.
cd offline_to_online/rank/
python s1_feature_to_feast.py새 터미널 (터미널 2)을 열고 6566의 축제 컨테이너를 HTTP 포트로 시작하고 다음 명령을 실행하여 내부 터미널을 입력하십시오.
cd data_exchange_center/online/feast
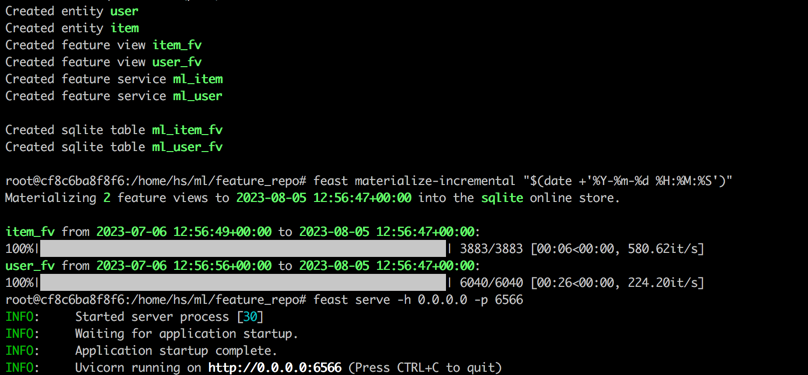
docker run --rm --name feast-server --entrypoint " bash " -v $( pwd ) :/home/hs -p 6566:6566 -it feastdev/feature-server:0.31.0잔치 컨테이너의 내부 터미널에서 다음 명령을 실행하십시오.
# Enter the config directory
cd /home/hs/ml/feature_repo
# Initialize the feature store from config files (read parquet to build database)
feast apply
# Load features from offline to online (defaults to sqlite, with options like Redis available)
feast materialize-incremental " $( date + ' %Y-%m-%d %H:%M:%S ' ) "
# Start the feature server
feast serve -h 0.0.0.0 -p 6566모든 단계를 완료하면 다음 출력이 표시됩니다.
터미널 1으로 돌아가서 Feast가 제대로 제공되는지 테스트하기 위해 다음 명령을 실행하십시오. 응답 JSON 문자열이 성공하면 인쇄됩니다.
curl -X POST
" http://localhost:6566/get-online-features "
-d ' {
"feature_service": "ml_item",
"entities": {
"itemid": [1,3,5]
}
} ' Triton (Triton Onference Server)은 NVIDIA가 개발 한 오픈 소스 추론 서빙 엔진입니다. Triton Instresiser Server는 Tensorflow, Pytorch, Onx 및 추가 옵션과 같은 다양한 프레임 워크를 지원하므로 모델 서빙에 탁월한 선택이됩니다. NVIDIA에 의해 개발되었지만 Triton은 CPU와 함께 제공하기에 충분히 다양하여 사용에 유연성을 제공합니다. 보다 일반적인 산업 솔루션에는 Tensorflow-> SavedModel-> Tensorflow 서빙이 포함되지만 Triton은 다른 프레임 워크 간 전환의 적응성으로 인해 인기를 얻고 있습니다. 따라서이 프로젝트에서는 pytorch-> onnx-> Triton 서버를 사용하는 파이프 라인을 채택합니다.
Pytorch 모델을 ONNX 형식으로 변환하십시오.
cd offline_to_online/rank/
python s2_model_to_triton.py새 터미널 (터미널 3)을 열고 8000을 HTTP 포트로 8000으로, 다음 명령을 실행하여 GRPC 포트로 8001을 시작하십시오.
cd data_exchange_center/online/triton
docker run --rm -p8000:8000 -p8001:8001 -p8002:8002 -v $( pwd ) /:/models/ nvcr.io/nvidia/tritonserver:20.12-py3 tritonserver --model-repository=/models/
터미널 1으로 돌아가서 스크립트를 실행하여 오프라인과 온라인 예측 점수 사이의 일관성을 테스트하십시오. 이 단계는 추천 시스템의 신뢰성을 보장하는 데 도움이됩니다.
cd offline_to_online/rank/
python s3_check_offline_and_online.py아래와 같이 오프라인 및 온라인 점수는 동일하므로 오프라인과 온라인 사이의 일관성을 나타냅니다.

산업 환경에서 엔지니어는 일반적으로 권장 시스템의 백엔드로 Java + Springboot 또는 Go + Gin을 선택합니다. 그러나이 프로젝트에서는 통합 용이성을 위해 Python + Flask가 사용됩니다. Django, Flask, Fastapi 및 Tornado를 포함하여 Python에 대한 몇 가지 웹 프레임 워크가 있으며,이 모든 것이 Restapi 요청을 처리 기능으로 라우팅 할 수 있습니다. 이러한 프레임 워크 중 하나는 우리의 요구 사항을 충족 할 수 있으며,이 프로젝트에 대해 Flask는 무작위로 선택되었습니다.
새 터미널 (터미널 4라고 함)을 열고 다음 명령을 실행하여 HTTP 포트로 5000으로 플라스크 웹 서버를 시작하십시오.
conda activate rsppl
cd online/main
flask --app s1_server.py run --host=0.0.0.0
터미널 1으로 돌아 가서 클라이언트에서 권장 서비스를 호출하여 테스트를 수행합니다 (이 맥락에서 클라이언트는 사용자 장치가 아닌 추천 서비스를 호출하는 업스트림 서비스를 말합니다). 결과는 JSON 형식으로 반환되며 상위 50 개 권장 항목 ID가 표시됩니다. 그 후, 다운 스트림 서비스는 이러한 항목 ID를 사용하여 해당 속성을 검색 한 다음 클라이언트 (이 맥락에서 사용자 장치)에 제공 할 수 있습니다. 이것은 전체 권장 흐름을 완료합니다.
cd online/main
python s2_client.py


