recsys_pipeline
1.0.0
ภาษาอังกฤษ | 中文
การใช้ชุดข้อมูล Movielens ที่รู้จักกันดีเป็นตัวอย่างเราจะแนะนำไปป์ไลน์ระบบแนะนำจากออฟไลน์ไปยังออนไลน์โดยสามารถดำเนินการทั้งหมดในแล็ปท็อปเดียว แม้จะมีการใช้ประโยชน์จากส่วนประกอบหลายอย่าง แต่ก็เป็นสิ่งสำคัญที่จะต้องทราบว่าทุกอย่างมีอยู่ใน Conda และ Docker ทำให้มั่นใจได้ว่าไม่มีผลกระทบต่อสภาพแวดล้อมในท้องถิ่น
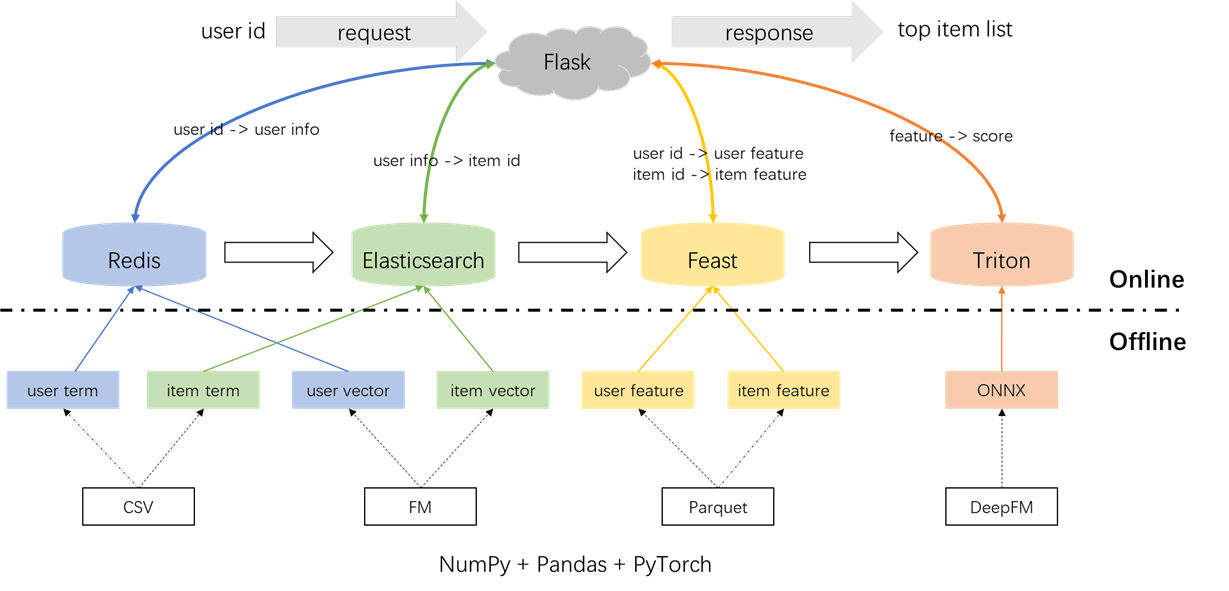
สถาปัตยกรรมโดยรวมของระบบผู้แนะนำแสดงไว้ด้านล่าง ตอนนี้เราจะแนะนำกระบวนการพัฒนาและการปรับใช้สำหรับโมดูลการเรียกคืนและการจัดอันดับในสามขั้นตอน: ออฟไลน์ออฟไลน์ถึงออนไลน์และออนไลน์
conda create -n rsppl python=3.8
conda activate rsppl
conda install --file requirements.txt --channel anaconda --channel conda-forge cd offline/preprocess/
python s1_data_split.py
python s2_term_trans.pyการประมวลผลล่วงหน้าของฉลากตัวอย่างและคุณสมบัติ:
มันเป็นสิ่งสำคัญที่จะเน้นแนวคิดของการเข้าร่วมจุดในเวลาในไฟล์ s2_term_trans.py โดยเฉพาะอย่างยิ่งในระหว่างการสร้างตัวอย่างการฝึกอบรมออฟไลน์ (imp_term.pkl) มีคุณสมบัติจนถึงและรวมถึงเวลาของการกระทำที่ใกล้เคียงที่สุดกับช่วงเวลาปัจจุบันควรใช้ การใช้คุณสมบัติหลังจากจุดนี้จะแนะนำการรั่วไหลของคุณลักษณะในขณะที่การใช้คุณสมบัติที่อยู่ไกลอย่างมากในเวลาจากปัจจุบันจะส่งผลให้เกิดความไม่สอดคล้องกันระหว่างออฟไลน์และออนไลน์ ในทางตรงกันข้ามคุณสมบัติล่าสุดควรปรับใช้สำหรับการให้บริการออนไลน์ (user_term.pkl และ item_term.pkl)
cd offline/recall/
python s1_term_recall.py
python s2_vector_recall.pyการเรียกคืนคำว่า: ส่วนประกอบนี้ใช้การโต้ตอบที่ผ่านมาของผู้ใช้กับรายการ ('ประเภท) ภายในหน้าต่างเวลาที่กำหนดเพื่อให้ตรงกับการตั้งค่าผู้ใช้กับรายการ ข้อกำหนดเหล่านี้จะถูกโหลดลงใน Redis และ Elasticsearch ในภายหลัง
การเรียกคืนเวกเตอร์: ในส่วนประกอบนี้มีการใช้งาน FM (เครื่องแยกส่วน) โดยใช้เฉพาะ ID ผู้ใช้และ ITIT ID เป็นคุณสมบัติ AUC ที่เกิดขึ้น (พื้นที่ใต้เส้นโค้ง) = 0.8081 เมื่อเสร็จสิ้นขั้นตอนการฝึกอบรมผู้ใช้และไอเท็มเวกเตอร์จะถูกดึงออกมาจากจุดตรวจสอบแบบจำลองและจะถูกโหลดลงใน Redis และ Elasticsearch เพื่อการใช้งานที่ตามมา
cd offline/rank/
python s1_feature_engi.py
python s2_model_train.pyโดยรวมแล้วมีคุณสมบัติ 59 รายการรวมถึงสามประเภท: คุณลักษณะหนึ่งที่ร้อนแรง (เช่น userId, itemid, เพศ, ฯลฯ ), คุณสมบัติหลายอย่างร้อนแรง (ประเภท) และคุณสมบัติที่หนาแน่น (สถิติพฤติกรรมเชิงประวัติศาสตร์)
รูปแบบการจัดอันดับที่ใช้คือ DeepFM ซึ่งได้รับ AUC ที่ 0.8206 ในขณะที่ Pytorch-FM เป็นแพ็คเกจที่สง่างามสำหรับอัลกอริทึมที่ใช้ FM แต่ก็มีข้อ จำกัด สองประการ: 1. รองรับคุณสมบัติกระจัดกระจายโดยเฉพาะและขาดการรองรับคุณสมบัติที่หนาแน่น 2. คุณสมบัติกระจัดกระจายทั้งหมดแบ่งปันมิติเดียวกันซึ่งละเมิดสัญชาตญาณว่า "การฝัง ID ควรเป็นมิติสูงในขณะที่การฝังข้อมูลด้านข้างควรเป็นมิติต่ำ" เพื่อจัดการกับข้อ จำกัด เหล่านี้เราได้ทำการปรับเปลี่ยนซอร์สโค้ดเพื่อให้การสนับสนุนสำหรับทั้งคุณสมบัติที่หนาแน่นและมิติการฝังที่แตกต่างกันสำหรับคุณสมบัติกระจัดกระจาย นอกจากนี้ยังมีข้อสังเกตว่าโมดูลการฝังลึกส่งผลกระทบต่อประสิทธิภาพของโมเดลซึ่งส่งผลให้เกิดการลบออกจากแบบจำลอง เป็นผลให้โครงสร้างโมเดลปัจจุบันส่วนใหญ่ประกอบด้วยโมดูล FM แบบเบาบางที่รวมเข้ากับ MLP หนาแน่นมันไม่ได้เป็น DeepFM ทั่วไป
เพื่อป้องกันผลกระทบใด ๆ ที่มีต่อสภาพแวดล้อมในท้องถิ่น Redis, Elasticsearch, Feast และ Triton ล้วนมีการใช้งานภายในตู้คอนเทนเนอร์ Docker ในการดำเนินการต่อโปรดตรวจสอบให้แน่ใจว่ามีการติดตั้ง Docker บนแล็ปท็อปของคุณแล้วดำเนินการคำสั่งต่อไปนี้เพื่อดาวน์โหลดรูปภาพ Docker ที่เกี่ยวข้อง
docker pull redis:6.0.0
docker pull elasticsearch:8.8.0
docker pull feastdev/feature-server:0.31.0
docker pull nvcr.io/nvidia/tritonserver:20.12-py3Redis ถูกใช้เป็นฐานข้อมูลสำหรับการจัดเก็บข้อมูลผู้ใช้ที่จำเป็นสำหรับการเรียกคืน
เริ่มคอนเทนเนอร์ Redis
docker run --name redis -p 6379:6379 -d redis:6.0.0กระบวนการเกี่ยวข้องกับการโหลดคำศัพท์เวกเตอร์และกรองของผู้ใช้ลงใน Redis ข้อมูลคำและเวกเตอร์ถูกสร้างขึ้นในส่วนที่ 1.2 ในขณะที่ตัวกรองเกี่ยวข้องกับรายการที่ผู้ใช้ได้โต้ตอบก่อนหน้านี้ รายการที่ผ่านการกรองเหล่านี้จะถูกแยกออกเมื่อสร้างคำแนะนำ
เมื่อโหลดข้อมูลขั้นตอนการตรวจสอบจะดำเนินการโดยการตรวจสอบข้อมูลสำหรับผู้ใช้ตัวอย่าง การตรวจสอบที่ประสบความสำเร็จจะถูกระบุโดยเอาต์พุตที่แสดงด้านล่าง
cd offline_to_online/recall/
python s1_user_to_redis.py
Elasticsearch ใช้เพื่อสร้างดัชนีกลับด้านและดัชนีเวกเตอร์สำหรับรายการ เดิมทีออกแบบมาสำหรับแอปพลิเคชันการค้นหากรณีการใช้งานพื้นฐานของ Elasticsearch เกี่ยวข้องกับการใช้คำเพื่อดึงเอกสาร ในบริบทของระบบผู้แนะนำเราถือว่ารายการเป็นเอกสารและข้อกำหนดของมันเช่นประเภทภาพยนตร์เป็นคำ สิ่งนี้ช่วยให้เราสามารถใช้ Elasticsearch เพื่อดึงรายการตามข้อกำหนดเหล่านี้ แนวคิดนี้สอดคล้องกับแนวคิดของดัชนีคว่ำทำให้ Elasticsearch เป็นเครื่องมือที่มีค่าสำหรับการเรียกคืนคำในระบบผู้แนะนำ สำหรับการเรียกคืนเวกเตอร์เครื่องมือที่ใช้กันทั่วไปคือ FAISS แบบเปิดโล่งของ Facebook อย่างไรก็ตามเพื่อความสะดวกในการรวมเราเลือกที่จะใช้ความสามารถในการดึงเวกเตอร์ของ Elasticsearch Elasticsearch ได้รองรับการดึงเวกเตอร์มาตั้งแต่เวอร์ชัน 7 และการเรียกคืน K-Nearest เพื่อนบ้านโดยประมาณ (ANN) ตั้งแต่เวอร์ชัน 8 ในโครงการนี้เราติดตั้ง Elasticsearch เวอร์ชันที่ 8 (หรือสูงกว่า) ตัวเลือกนี้ทำขึ้นเนื่องจากการดึงข้อมูล KNN ที่แม่นยำมักจะไม่สามารถตอบสนองความต้องการต่ำของระบบออนไลน์ได้
เริ่มคอนเทนเนอร์ Elasticsearch และป้อนเทอร์มินัลภายในโดยดำเนินการคำสั่งต่อไปนี้
docker run --name es8 -p 9200:9200 -it elasticsearch:8.8.0 คัดลอกรหัสผ่านที่แสดงในเอาต์พุตเทอร์มินัลของคุณ (ตามที่ระบุไว้ด้านล่าง) และวางเป็นค่าสำหรับ ES_KEY ในไฟล์ data_exchange_center/constants.py ขั้นตอนนี้เป็นสิ่งจำเป็นเนื่องจาก Elasticsearch ได้ใช้ข้อกำหนดการตรวจสอบรหัสผ่านเริ่มต้นจากเวอร์ชัน 8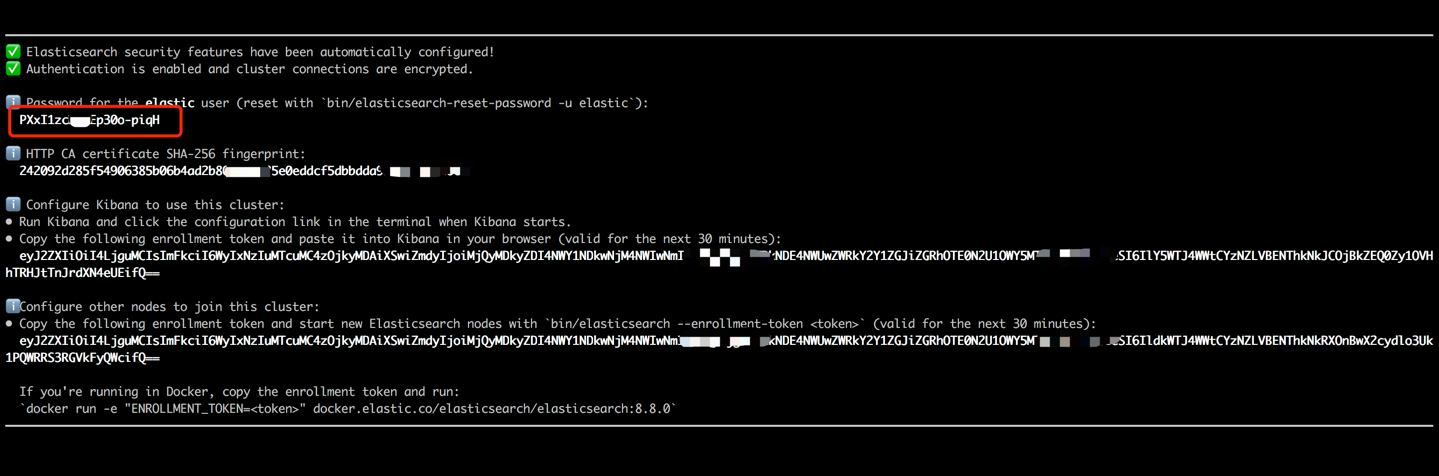
เมื่อรหัสผ่านถูกวางแล้วให้ออกจากเทอร์มินัลภายในโดยใช้คีย์บอร์ด CTRL+C (หรือคำสั่ง+C) การกระทำนี้จะหยุดคอนเทนเนอร์ด้วยดังนั้นเราจำเป็นต้องรีสตาร์ทคอนเทนเนอร์ Elasticsearch และตรวจสอบให้แน่ใจว่ามันทำงานในพื้นหลังเป็นส่วนหนึ่งของขั้นตอนต่อไป
docker start es8โหลดข้อกำหนดรายการเพื่อสร้างดัชนีคำและโหลดเวกเตอร์รายการเพื่อสร้างดัชนีเวกเตอร์ ในการตั้งค่าอุตสาหกรรมดัชนีทั้งสองนี้จะถูกแยกออกเพื่อประสิทธิภาพและความยืดหยุ่นที่ดีขึ้น อย่างไรก็ตามเพื่อความเรียบง่ายในโครงการนี้เรากำลังรวมเข้ากับดัชนีเดียว
หลังจากกระบวนการโหลดข้อมูลขั้นตอนการตรวจสอบจะดำเนินการโดยการตรวจสอบคำและเวกเตอร์ของรายการตัวอย่าง การตรวจสอบที่ประสบความสำเร็จจะถูกระบุโดยเอาต์พุตที่แสดงด้านล่าง
cd offline_to_online/recall/
python s2_item_to_es.py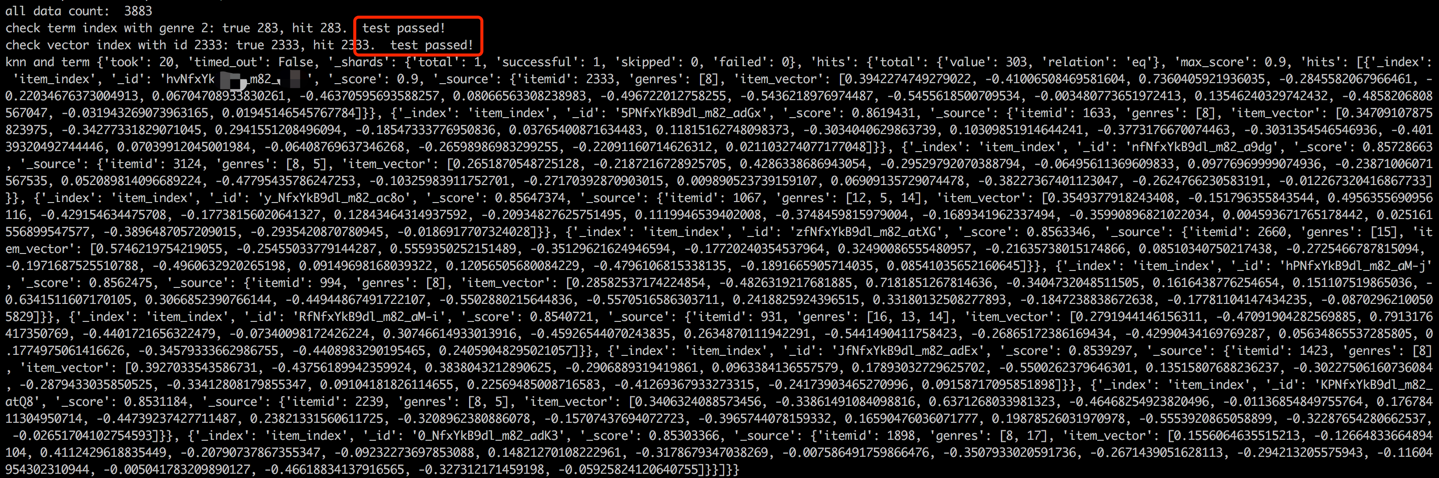
งานเลี้ยงหมายถึงร้านค้าฟีเจอร์โอเพ่นซอร์สผู้บุกเบิกโดยมีความสำคัญทางประวัติศาสตร์ในโดเมนนี้ งานเลี้ยงรวมทั้งส่วนประกอบออฟไลน์และออนไลน์ ส่วนประกอบออฟไลน์ส่วนใหญ่อำนวยความสะดวกในการเข้าร่วม point-in-time อย่างไรก็ตามเนื่องจากเรามีการจัดการจุดเข้าร่วมในแพนด้าด้วยตนเองจึงไม่มีความจำเป็นที่จะใช้ประโยชน์จากความสามารถออฟไลน์ของงานเลี้ยง แต่เราใช้งานฉลองเป็นร้านค้าออนไลน์ เหตุผลที่อยู่เบื้องหลังการไม่ใช้งานฉลองสำหรับการเข้าร่วมแบบจุดอยู่ในความจริงที่ว่างานเลี้ยงส่วนใหญ่มีความสามารถในการจัดเก็บข้อมูลคุณสมบัติและขาดความสามารถทางวิศวกรรมคุณลักษณะ (แม้ว่ามันจะแนะนำการเปลี่ยนแปลงขั้นพื้นฐานบางอย่างในเวอร์ชันล่าสุด) บริษัท ส่วนใหญ่ชอบเอ็นจิ้นคุณสมบัติที่กำหนดเองที่มีความสามารถที่ทรงพลังกว่า ดังนั้นจึงไม่จำเป็นต้องลงทุนอย่างมากในการเรียนรู้การใช้งานออฟไลน์ของ Feast มันเป็นประโยชน์มากขึ้นในการใช้เครื่องมือทั่วไปมากขึ้นเช่นแพนด้าหรือ Spark สำหรับการประมวลผลคุณสมบัติและการใช้ประโยชน์จากงานเลี้ยง แต่เพียงผู้เดียวเป็นองค์ประกอบสำหรับการขนส่งคุณสมบัติระหว่างออฟไลน์และออนไลน์
แปลงไฟล์ฟีเจอร์จาก CSV เป็นรูปแบบ Parquet เพื่อตอบสนองความต้องการของงานเลี้ยง
cd offline_to_online/rank/
python s1_feature_to_feast.pyเปิดเทอร์มินัลใหม่ (เรียกว่าเทอร์มินัล 2) เริ่มคอนเทนเนอร์งานเลี้ยงด้วย 6566 เป็นพอร์ต HTTP และป้อนเทอร์มินัลภายในโดยดำเนินการคำสั่งต่อไปนี้
cd data_exchange_center/online/feast
docker run --rm --name feast-server --entrypoint " bash " -v $( pwd ) :/home/hs -p 6566:6566 -it feastdev/feature-server:0.31.0ดำเนินการคำสั่งต่อไปนี้ในเทอร์มินัลภายในของคอนเทนเนอร์
# Enter the config directory
cd /home/hs/ml/feature_repo
# Initialize the feature store from config files (read parquet to build database)
feast apply
# Load features from offline to online (defaults to sqlite, with options like Redis available)
feast materialize-incremental " $( date + ' %Y-%m-%d %H:%M:%S ' ) "
# Start the feature server
feast serve -h 0.0.0.0 -p 6566หลังจากทำตามขั้นตอนทั้งหมดเสร็จแล้วเอาต์พุตต่อไปนี้จะปรากฏขึ้น
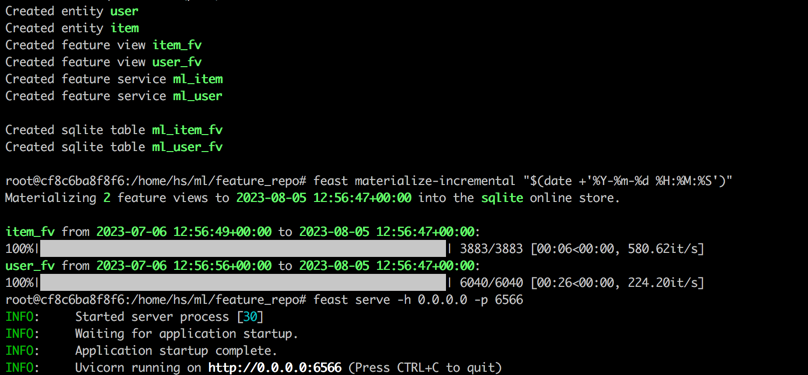
กลับไปที่เทอร์มินัล 1 ดำเนินการคำสั่งต่อไปนี้เพื่อทดสอบว่างานเลี้ยงให้บริการอย่างถูกต้องหรือไม่ สตริงการตอบกลับ JSON จะถูกพิมพ์หากประสบความสำเร็จ
curl -X POST
" http://localhost:6566/get-online-features "
-d ' {
"feature_service": "ml_item",
"entities": {
"itemid": [1,3,5]
}
} ' Triton (Triton Inference Server) เป็นเครื่องมือที่ให้บริการแบบโอเพนซอร์ซที่พัฒนาโดย NVIDIA เซิร์ฟเวอร์การอนุมาน Triton ให้การสนับสนุนสำหรับเฟรมเวิร์กที่หลากหลายเช่น TensorFlow, Pytorch, ONNX และตัวเลือกเพิ่มเติมทำให้เป็นตัวเลือกที่ยอดเยี่ยมสำหรับการให้บริการแบบจำลอง แม้จะมีการพัฒนาโดย Nvidia แต่ Triton ก็มีความหลากหลายเพียงพอที่จะรับใช้ด้วยซีพียูซึ่งให้ความยืดหยุ่นในการใช้งาน ในขณะที่โซลูชันอุตสาหกรรมที่แพร่หลายมากขึ้นเกี่ยวข้องกับ TensorFlow -> SavedModel -> การให้บริการ TensorFlow, Triton ได้รับความนิยมเนื่องจากการปรับตัวในการสลับระหว่างเฟรมเวิร์กที่แตกต่างกัน ดังนั้นในโครงการนี้เราใช้ท่อที่ใช้ pytorch -> onnx -> Triton Server
แปลงรูปแบบ pytorch เป็นรูปแบบ onnx
cd offline_to_online/rank/
python s2_model_to_triton.pyเปิดเทอร์มินัลใหม่ (เรียกว่าเทอร์มินัล 3) เริ่มคอนเทนเนอร์ไทรทันด้วย 8000 เป็นพอร์ต HTTP และ 8001 เป็นพอร์ต GRPC โดยดำเนินการคำสั่งต่อไปนี้
cd data_exchange_center/online/triton
docker run --rm -p8000:8000 -p8001:8001 -p8002:8002 -v $( pwd ) /:/models/ nvcr.io/nvidia/tritonserver:20.12-py3 tritonserver --model-repository=/models/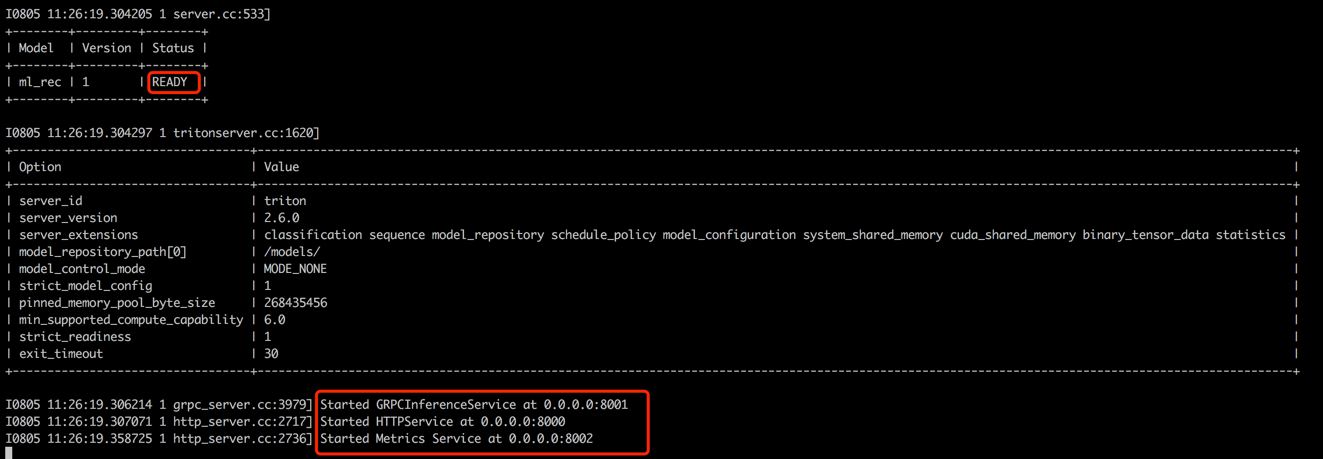
กลับไปที่เทอร์มินัล 1 เรียกใช้สคริปต์เพื่อทดสอบความสอดคล้องระหว่างคะแนนการทำนายออฟไลน์และออนไลน์ ขั้นตอนนี้จะช่วยให้มั่นใจถึงความน่าเชื่อถือของระบบผู้แนะนำ
cd offline_to_online/rank/
python s3_check_offline_and_online.pyดังที่แสดงไว้ด้านล่างคะแนนออฟไลน์และออนไลน์เหมือนกันซึ่งบ่งบอกถึงความสอดคล้องระหว่างออฟไลน์และออนไลน์

ในการตั้งค่าอุตสาหกรรมวิศวกรมักเลือกใช้ Java + Springboot หรือ Go + Gin เป็นแบ็กเอนด์สำหรับระบบแนะนำ อย่างไรก็ตามในโครงการนี้เพื่อความสะดวกในการรวม Python + Flask ถูกนำมาใช้ เป็นที่น่าสังเกตว่ามีเฟรมเวิร์กเว็บหลายเฟรมสำหรับ Python รวมถึง Django, Flask, Fastapi และ Tornado ซึ่งทั้งหมดนี้มีความสามารถในการกำหนดเส้นทางการร้องขอ Restapi ไปยังฟังก์ชั่นสำหรับการประมวลผล กรอบใด ๆ เหล่านี้สามารถตอบสนองความต้องการของเรา Flask ได้รับการสุ่มเลือกสำหรับโครงการนี้
เปิดเทอร์มินัลใหม่ (เรียกว่าเทอร์มินัล 4) เริ่มต้นเว็บเซิร์ฟเวอร์ Flask ด้วย 5000 เป็นพอร์ต HTTP โดยดำเนินการคำสั่งต่อไปนี้
conda activate rsppl
cd online/main
flask --app s1_server.py run --host=0.0.0.0
กลับไปที่เทอร์มินัล 1 และดำเนินการทดสอบโดยเรียกใช้บริการแนะนำจากลูกค้า (ในบริบทนี้ไคลเอนต์หมายถึงบริการต้นน้ำที่เรียกบริการแนะนำไม่ใช่อุปกรณ์ผู้ใช้) ผลลัพธ์จะถูกส่งกลับในรูปแบบ JSON โดยแสดงรหัสรายการที่แนะนำ 50 อันดับแรก ต่อจากนั้นบริการดาวน์สตรีมสามารถใช้ ID รายการเหล่านี้เพื่อดึงคุณลักษณะที่เกี่ยวข้องของพวกเขาจากนั้นให้พวกเขากับไคลเอนต์ (ในบริบทนี้อุปกรณ์ผู้ใช้) สิ่งนี้ทำให้โฟลว์คำแนะนำทั้งหมดเสร็จสมบูรณ์
cd online/main
python s2_client.py


