recsys_pipeline
1.0.0
英語| 中文
よく知られているMovielensデータセットを例として使用して、すべての操作を1つのラップトップで実行できます。複数のコンポーネントの利用にもかかわらず、すべてがCondaとDockerに含まれていることに注意することが重要であり、ローカル環境に影響を与えないことを保証します。
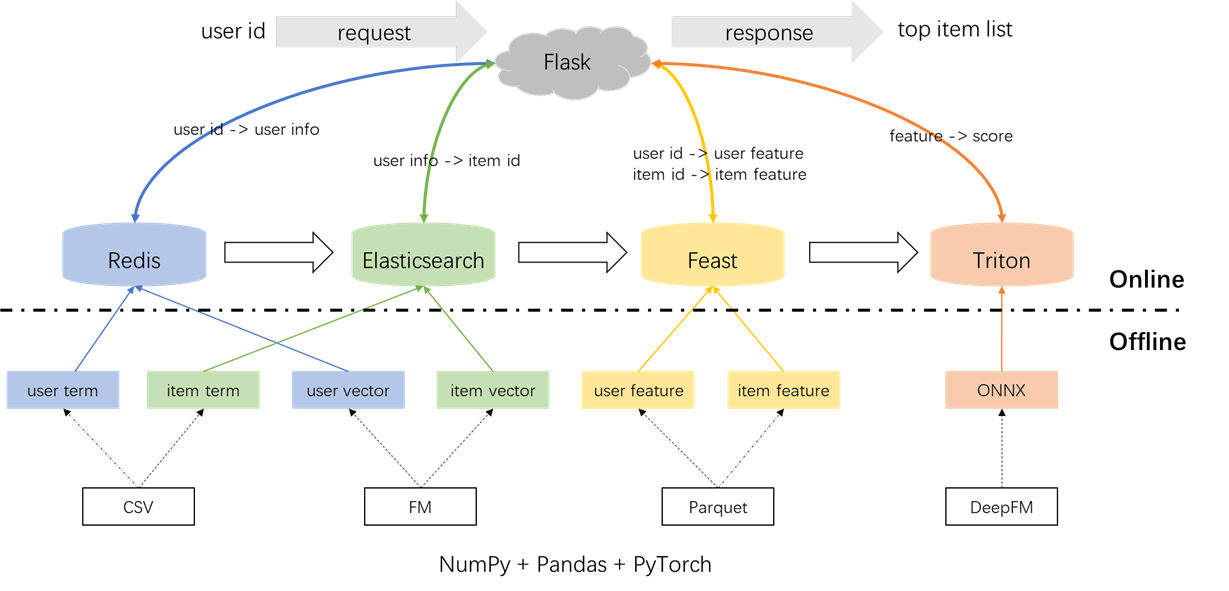
推奨システムの全体的なアーキテクチャを以下に示します。次に、オフライン、オフラインからオンライン、オンラインの3つのフェーズにまたがるリコールおよびランキングモジュールの開発と展開プロセスを導入します。
conda create -n rsppl python=3.8
conda activate rsppl
conda install --file requirements.txt --channel anaconda --channel conda-forge cd offline/preprocess/
python s1_data_split.py
python s2_term_trans.pyラベル、サンプル、および機能の前処理:
s2_term_trans.pyファイルにPoint-in-time結合の概念を強調することが重要です。具体的には、オフライントレーニングサンプル(IMP_TERM.PKL)の生成中に、現在の瞬間に最も近いアクションの時間を使用することを含む機能を使用する必要があります。このポイントの後に機能を使用すると機能が漏れを導入しますが、現在から時間が大きく離れている機能を使用すると、オフラインとオンラインの間に矛盾が生じます。対照的に、最新の機能はオンラインサービング用に展開する必要があります(user_term.pkl and item_term.pkl)。
cd offline/recall/
python s1_term_recall.py
python s2_vector_recall.py用語のリコール:このコンポーネントは、ユーザーの好みとアイテムと一致するために、指定された時間枠内でユーザーの過去のやり取り( 'ジャンル)を利用します。これらの用語は、後でRedisとElasticsearchにロードされます。
Vector Recall:このコンポーネントでは、FM(Factorization Machines)が採用されており、ユーザーIDとアイテムIDのみが機能として使用されます。結果のAUC(曲線下の面積)= 0.8081。トレーニングフェーズが完了すると、ユーザーとアイテムのベクトルがモデルチェックポイントから抽出され、その後の利用のためにRedisとElasticsearchにロードされます。
cd offline/rank/
python s1_feature_engi.py
python s2_model_train.py合計で、3つのタイプを含む59の機能があります:1つのホット機能(userID、itemID、性別など)、マルチホット機能(ジャンル)、密な機能(歴史的行動統計)。
採用されているランキングモデルはDEEPFMであり、0.8206のAUCを達成しています。 Pytorch-FMはFMベースのアルゴリズムのエレガントなパッケージですが、2つの制限があります。 2.すべてのスパース機能は同じ次元を共有しており、「ID埋め込みは高次元である必要がありますが、サイド情報の埋め込みは低次元である必要があります。」これらの制約に対処するために、ソースコードを変更し、密な機能のサポートと、スパース機能の寸法の埋め込みの両方を可能にします。さらに、深い埋め込みモジュールがモデルのパフォーマンスに悪影響を及ぼし、モデルからの削除が促されたことが注目されました。その結果、現在のモデル構造は、主に密なMLPと統合されたスパースFMモジュールで構成されており、従来のDEEPFMではありません。
ローカル環境への影響を防ぐために、Redis、Elasticsearch、Feast、TritonはすべてDockerコンテナ内で採用されています。続行するには、Dockerがラップトップにインストールされていることを確認し、次のコマンドを実行してそれぞれのDocker画像をダウンロードしてください。
docker pull redis:6.0.0
docker pull elasticsearch:8.8.0
docker pull feastdev/feature-server:0.31.0
docker pull nvcr.io/nvidia/tritonserver:20.12-py3Redisは、リコールに必要なユーザー情報を保存するためのデータベースとして使用されます。
Redisコンテナを起動します。
docker run --name redis -p 6379:6379 -d redis:6.0.0このプロセスには、ユーザーの用語、ベクトル、フィルターをRedisにロードすることが含まれます。用語とベクトルデータはセクション1.2で生成され、フィルターはユーザーが以前に対話したアイテムに関係しています。これらのフィルタリングされたアイテムは、推奨事項を生成するときに除外されます。
データがロードされると、サンプルユーザーのデータをチェックすることにより、検証ステップが実行されます。検証の成功は、以下に表示される出力によって示されます。
cd offline_to_online/recall/
python s1_user_to_redis.py
ElasticSearchは、アイテムの反転インデックスとベクトルインデックスの両方を作成するために採用されています。もともと検索アプリケーション向けに設計されたElasticsearchの基本的なユースケースでは、単語を使用してドキュメントを取得することが含まれます。推奨システムのコンテキストでは、アイテムをドキュメントとして扱い、映画のジャンルなどの用語を言葉として扱います。これにより、ElasticSearchを使用してこれらの用語に基づいてアイテムを取得できます。この概念は、反転インデックスの概念と一致しているため、ElasticSearchは推奨システムでの用語リコールにとって貴重なツールになります。 Vector Recallの場合、一般的に使用されるツールはFacebookのオープンソースのFAISSです。ただし、統合を容易にするために、Elasticsearchのベクトル検索機能を利用することを選択しました。 ElasticSearchは、バージョン7以降Vector検索をサポートしており、バージョン8以降のK-Nearest Neighter(ANN)検索をおおよしサポートしています。このプロジェクトでは、8(またはそれ以上)のElasticSearchのバージョンをインストールします。この選択は、正確なKNN検索がオンラインシステムの低遅延要件を満たすことができないことが多いために行われます。
ElasticSearchコンテナを起動し、次のコマンドを実行して内部端子を入力します。
docker run --name es8 -p 9200:9200 -it elasticsearch:8.8.0端末出力(以下に示すように)に表示されたパスワードをコピーし、data_exchange_center/constants.pyファイルのes_keyの値として貼り付けます。 ElasticSearchがバージョン8から始まるパスワード認証要件を実装しているため、このステップが必要です。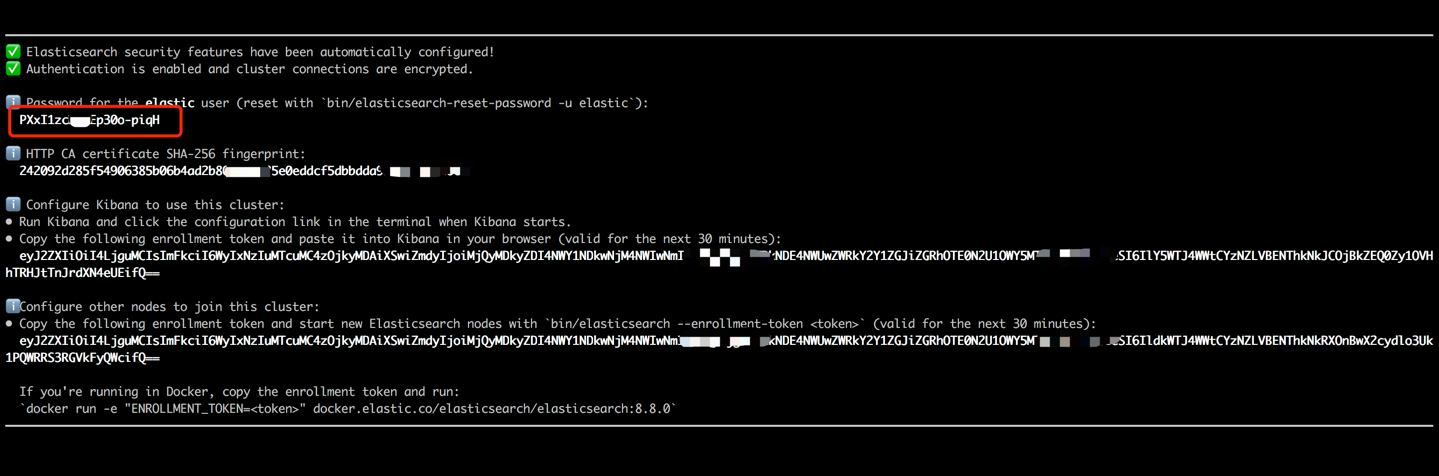
パスワードが貼り付けたら、Ctrl+C(またはコマンド+C)キーボードショートカットを使用して、内部端子を終了します。このアクションはコンテナも停止するため、Elasticsearchコンテナを再起動し、後続の手順の一部としてバックグラウンドで実行されることを確認する必要があります。
docker start es8アイテム用語をロードしてインデックスという用語を作成し、アイテムベクトルをロードしてベクトルインデックスを作成します。産業用設定では、これらの2つのインデックスは通常、パフォーマンスと柔軟性を向上させるために分離されます。ただし、このプロジェクトで簡単にするために、それらを単一のインデックスに組み合わせています。
データの読み込みプロセスに続いて、サンプル項目の用語とベクトルをチェックすることにより、検証ステップが実行されます。検証の成功は、以下に表示される出力によって示されます。
cd offline_to_online/recall/
python s2_item_to_es.py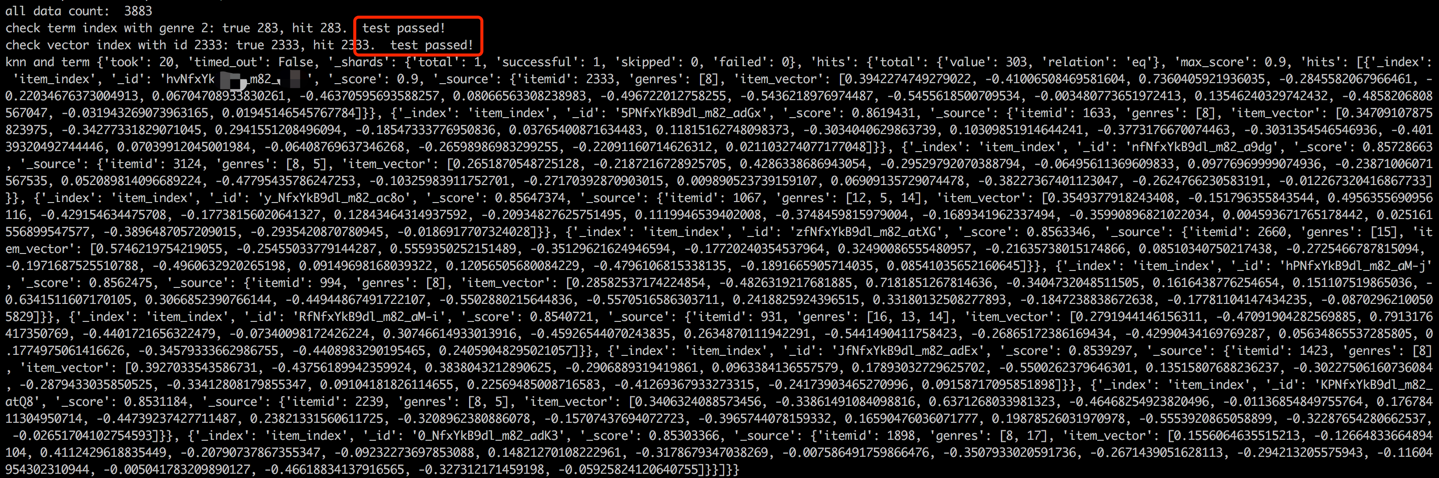
Feastは先駆的なオープンソース機能ストアとして立っており、このドメインで歴史的な重要性を保持しています。ごちそうには、オフラインコンポーネントとオンラインコンポーネントの両方が含まれています。オフラインコンポーネントは、主にポイントインタイム結合を促進します。しかし、私たちは自分自身でパンダに参加するポイントインタイムを管理しているため、Feastのオフライン能力を活用する必要はありません。代わりに、オンライン機能ストアとしてごちそうを採用しています。 Point-in-Time結合にFeastを使用しないと背後にある理由は、Feastが主に機能ストレージ機能を提供し、機能エンジニアリング機能がないという事実にあります(ただし、最近のバージョンにいくつかの基本的な変換が導入されています)。ほとんどの企業は、より強力な機能を備えたカスタマイズされた機能エンジンを好みます。したがって、Feastのオフライン使用を学ぶことに多くの努力を投資する必要はありません。オフラインとオンラインの間で機能を輸送するためのコンポーネントとしてのみ、フィーチャー処理やレバレッジフィーストなど、パンダやSparkなどのより一般的なツールを使用することがより実用的です。
Feastの要件を満たすために、機能ファイルをCSVからParquet形式に変換します。
cd offline_to_online/rank/
python s1_feature_to_feast.py新しい端子(ターミナル2と呼ばれる)を開き、6566をHTTPポートとして開始し、次のコマンドを実行して内部端子を入力します。
cd data_exchange_center/online/feast
docker run --rm --name feast-server --entrypoint " bash " -v $( pwd ) :/home/hs -p 6566:6566 -it feastdev/feature-server:0.31.0Feast Containerの内部端子で次のコマンドを実行します。
# Enter the config directory
cd /home/hs/ml/feature_repo
# Initialize the feature store from config files (read parquet to build database)
feast apply
# Load features from offline to online (defaults to sqlite, with options like Redis available)
feast materialize-incremental " $( date + ' %Y-%m-%d %H:%M:%S ' ) "
# Start the feature server
feast serve -h 0.0.0.0 -p 6566すべてのステップを完了すると、次の出力が表示されます。
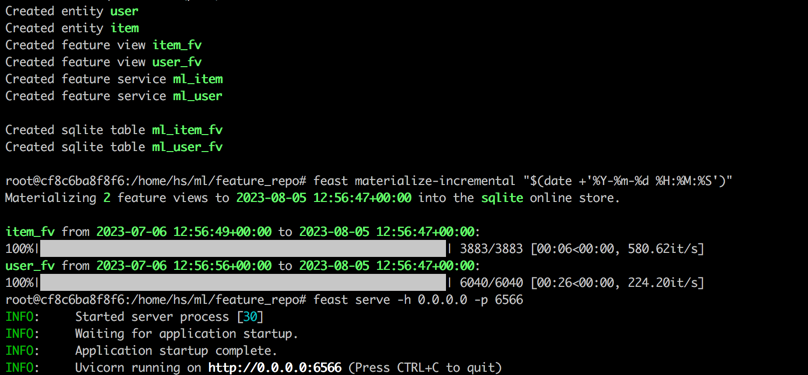
ターミナル1に戻り、次のコマンドを実行して、Feastが適切に提供されているかどうかをテストします。正常にJSON文字列が印刷されます。
curl -X POST
" http://localhost:6566/get-online-features "
-d ' {
"feature_service": "ml_item",
"entities": {
"itemid": [1,3,5]
}
} ' Triton(Triton Inference Server)は、Nvidiaが開発したオープンソースの推論サービスエンジンです。 Triton Inference Serverは、Tensorflow、Pytorch、ONNX、追加オプションなどの多様なフレームワークをサポートしているため、モデルのサービングに最適な選択肢となっています。 Nvidiaによって開発されたにもかかわらず、TritonはCPUを使用するのに十分な用途が広く、その使用に柔軟性を提供します。より一般的な業界ソリューションにはTensorflow-> SavedModel-> Tensorflowサービングが含まれますが、Tritonは異なるフレームワーク間の切り替えに適応性があるため、人気を博しています。したがって、このプロジェクトでは、pytorch-> onnx-> tritonサーバーを使用するパイプラインを採用します。
PytorchモデルをONNX形式に変換します。
cd offline_to_online/rank/
python s2_model_to_triton.py新しい端子(ターミナル3と呼ばれる)を開き、次のコマンドを実行して、HTTPポートとして8000、8001をGRPCポートとして8000で開始します。
cd data_exchange_center/online/triton
docker run --rm -p8000:8000 -p8001:8001 -p8002:8002 -v $( pwd ) /:/models/ nvcr.io/nvidia/tritonserver:20.12-py3 tritonserver --model-repository=/models/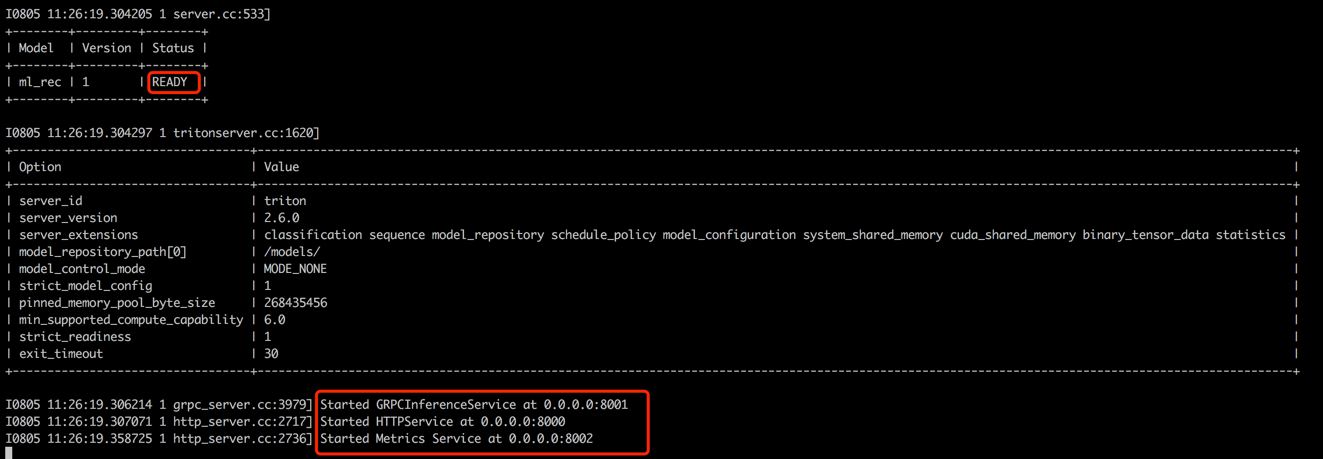
ターミナル1に戻ると、スクリプトを実行して、オフラインとオンラインの予測スコアの一貫性をテストします。このステップは、推奨システムの信頼性を確保するのに役立ちます。
cd offline_to_online/rank/
python s3_check_offline_and_online.py以下に示すように、オフラインとオンラインのスコアは同一であり、オフラインとオンラインの間の一貫性を示しています。

産業環境では、エンジニアは一般に、推奨システムのバックエンドとしてJava + SpringbootまたはGo + Ginを選択します。ただし、このプロジェクトでは、統合を容易にするために、Python + Flaskが利用されています。 Django、Flask、Fastapi、Tornadoなど、PythonにはいくつかのWebフレームワークがあることは注目に値します。これらはすべて、処理のための機能にRestapi要求をルーティングできることです。これらのフレームワークのいずれかが当社の要件を満たすことができ、フラスコはこのプロジェクトのためにランダムに選択されました。
新しい端子(ターミナル4と呼ばれる)を開き、次のコマンドを実行して、HTTPポートとして5000でFlask Webサーバーを起動します。
conda activate rsppl
cd online/main
flask --app s1_server.py run --host=0.0.0.0
ターミナル1に戻り、クライアントから推奨サービスを呼び出すことでテストを実施します(このコンテキストでは、クライアントはユーザーデバイスではなく推奨サービスを呼び出す上流サービスを参照します)。結果はJSON形式で返され、上位50の推奨アイテムIDが表示されます。その後、ダウンストリームサービスは、これらのアイテムIDを使用して対応する属性を取得し、クライアントに提供できます(このコンテキスト、ユーザーデバイス)。これにより、完全な推奨フローが完了します。
cd online/main
python s2_client.py


