recsys_pipeline
1.0.0
Inglês | 中文
Usando o conhecido conjunto de dados do MovéLens como exemplo, apresentaremos o pipeline do sistema de recomendação do offline para o online, com todas as operações podem ser executadas em um único laptop. Apesar da utilização de vários componentes, é importante observar que tudo está contido em Conde e Docker, garantindo nenhum impacto no ambiente local.
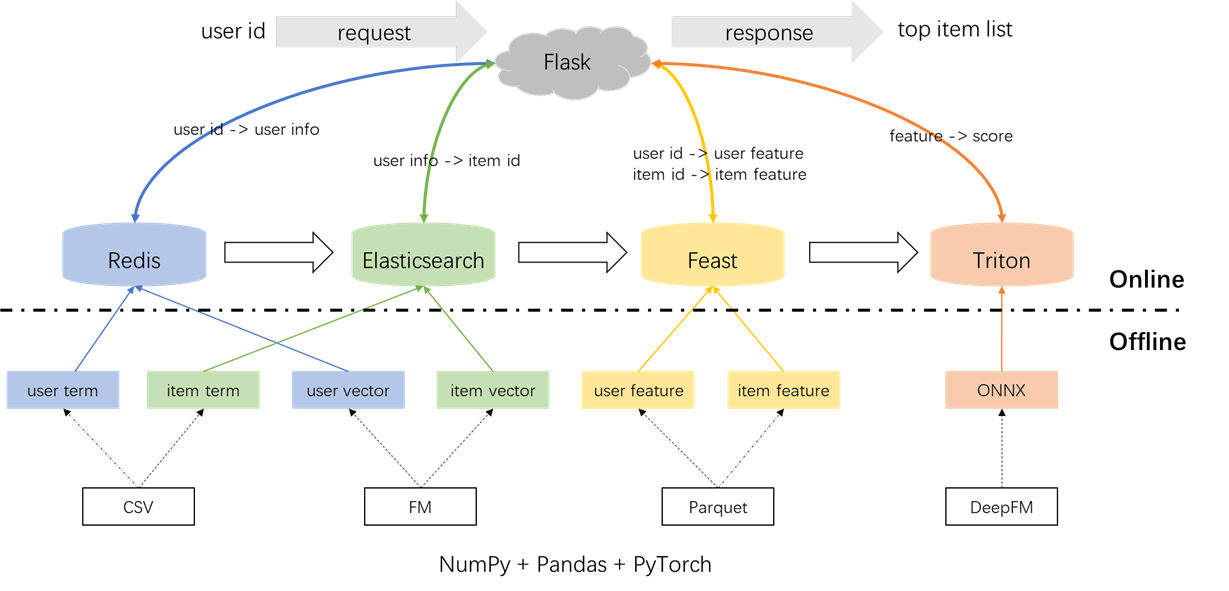
A arquitetura geral do sistema de recomendação é ilustrada abaixo. Agora, apresentaremos os processos de desenvolvimento e implantação para os módulos de recall e classificação em três fases: offline, offline para linha e online.
conda create -n rsppl python=3.8
conda activate rsppl
conda install --file requirements.txt --channel anaconda --channel conda-forge cd offline/preprocess/
python s1_data_split.py
python s2_term_trans.pyPré -processamento de rótulos, amostras e recursos:
É importante destacar o conceito de junções pontuais no arquivo s2_term_trans.py. Especificamente, durante a geração de amostras de treinamento offline (IMP_TERM.PKL), os recursos até e incluindo a hora da ação mais próxima do momento presente devem ser utilizados. O uso de recursos após esse ponto introduziria vazamento de recursos, enquanto o uso de recursos que estão significativamente distantes no tempo do presente resultariam em inconsistências entre offline e online. Por outro lado, os recursos mais recentes devem ser implantados para servir on -line (user_term.pkl e item_term.pkl).
cd offline/recall/
python s1_term_recall.py
python s2_vector_recall.pyRecall de termo: Este componente utiliza as interações anteriores do usuário com itens ('gêneros) dentro de uma janela de tempo especificada para corresponder às preferências do usuário com os itens. Esses termos serão carregados em Redis e Elasticsearch posteriormente.
Recall de vetor: Neste componente, FM (Máquinas de Factorização) são empregadas, utilizando apenas o ID do usuário e o ID do item como recursos. A AUC resultante (área sob a curva) = 0,8081. Após a conclusão da fase de treinamento, os vetores do usuário e do item são extraídos do ponto de verificação do modelo e serão carregados no Redis e no Elasticsearch para a utilização subsequente.
cd offline/rank/
python s1_feature_engi.py
python s2_model_train.pyNo total, existem 59 recursos, incluindo três tipos: recursos de um hots (como UserID, ItemID, Gênero, etc.), recursos multi-hot (gêneros) e recursos densos (estatísticas comportamentais históricas).
O modelo de classificação empregado é o DeepFM, alcançando uma AUC de 0,8206. Embora o Pytorch-FM seja um pacote elegante para algoritmos baseados em FM, ele possui duas limitações: 1. Ele suporta exclusivamente recursos esparsos e não possui suporte para recursos densos. 2. Todos os recursos esparsos compartilham a mesma dimensão, que viola a intuição de que "as incorporações de ID devem ser de alta dimensão, enquanto as informações laterais incorporam as incorporações de baixa dimensão". Para abordar essas restrições, fizemos modificações no código -fonte, permitindo suporte para recursos densos e dimensões de incorporação variadas para recursos escassos. Além disso, observou -se que o módulo de incorporação profundo impactou negativamente o desempenho do modelo, o que levou sua remoção do modelo. Como resultado, a estrutura do modelo atual consiste principalmente em um módulo FM esparso integrado a um MLP denso, não é um DeepFM convencional.
Para evitar qualquer impacto no ambiente local, Redis, Elasticsearch, Feast e Triton estão todos empregados em recipientes do Docker. Para prosseguir, verifique se o Docker foi instalado no seu laptop e execute os seguintes comandos para baixar as respectivas imagens do Docker.
docker pull redis:6.0.0
docker pull elasticsearch:8.8.0
docker pull feastdev/feature-server:0.31.0
docker pull nvcr.io/nvidia/tritonserver:20.12-py3O Redis é utilizado como um banco de dados para armazenar informações do usuário necessárias para recall.
Inicie o recipiente Redis.
docker run --name redis -p 6379:6379 -d redis:6.0.0O processo envolve o carregamento do termo, vetor e filtro do usuário no redis. O termo e os dados do vetor são gerados na Seção 1.2, enquanto o filtro refere -se aos itens com os quais o usuário interagiu anteriormente. Esses itens filtrados são excluídos ao gerar recomendações.
Depois que os dados forem carregados, uma etapa de validação será realizada verificando os dados para um usuário de amostra. Uma validação bem -sucedida será indicada pela saída exibida abaixo.
cd offline_to_online/recall/
python s1_user_to_redis.py
O Elasticsearch é empregado para criar índice invertido e índice vetorial para itens. Originalmente projetado para aplicativos de pesquisa, o caso de uso fundamental do Elasticsearch envolve o uso de palavras para recuperar documentos. No contexto dos sistemas de recomendação, tratamos um item como um documento e seus termos, como gêneros de filmes, como palavras. Isso nos permite usar o Elasticsearch para recuperar itens com base nesses termos. Esse conceito se alinha com a noção de índices invertidos, tornando o Elasticsearch uma ferramenta valiosa para recall de termos em sistemas de recomendação. Para recall de vetores, uma ferramenta comumente usada é o FAISS de código aberto do Facebook. No entanto, por uma questão de facilidade de integração, optamos por utilizar as capacidades de recuperação de vetor da Elasticsearch. O Elasticsearch apoiou a recuperação do vetor desde a versão 7 e a recuperação aproximada do vizinho K-Dreeest (Ann) desde a versão 8. Neste projeto, instalamos uma versão do Elasticsearch que é 8 (ou superior). Essa opção é feita porque a recuperação precisa do KNN geralmente não pode atender aos requisitos de baixa latência de um sistema on-line.
Inicie o contêiner Elasticsearch e insira seu terminal interno executando os seguintes comandos.
docker run --name es8 -p 9200:9200 -it elasticsearch:8.8.0 Copie a senha exibida na saída do terminal (conforme indicado abaixo) e cole -a como o valor para ES_KEY no arquivo data_exchange_center/constants.py. Esta etapa é necessária porque o Elasticsearch implementou requisitos de autenticação por senha a partir da versão 8.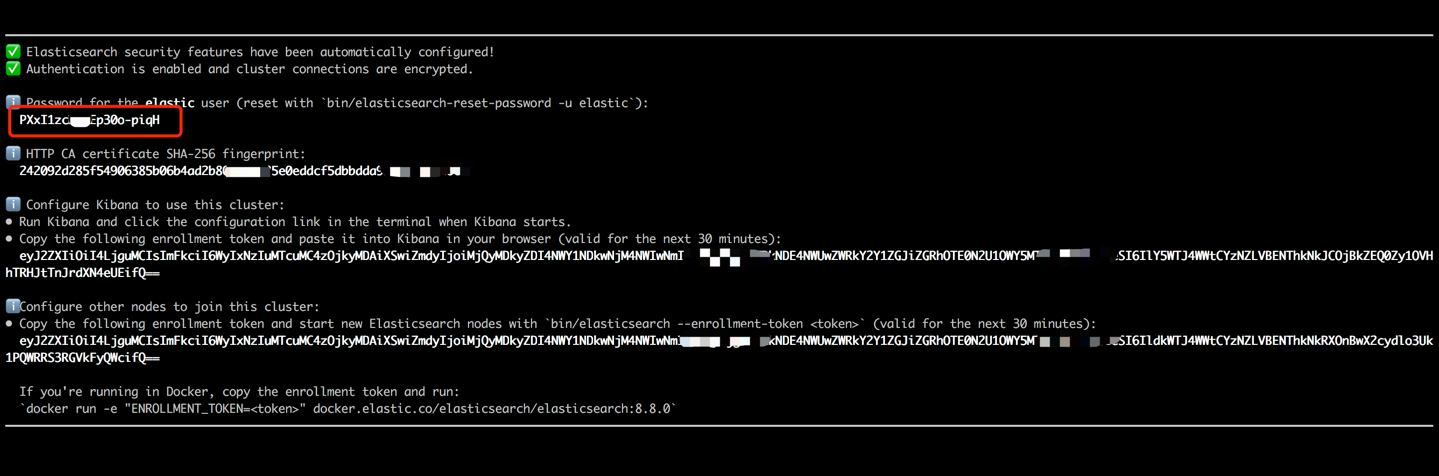
Depois que a senha for colada, saia do terminal interno usando o atalho de teclado Ctrl+C (ou Command+C). Essa ação também interrompe o contêiner, portanto, precisamos reiniciar o contêiner Elasticsearch e garantir que ele seja executado em segundo plano como parte das etapas subsequentes.
docker start es8Carregue os termos do item para criar o termo índice e carregar os vetores do item para criar o índice vetorial. Em ambientes industriais, esses dois índices geralmente são separados para melhor desempenho e flexibilidade. No entanto, para simplificar neste projeto, estamos combinando -os em um único índice.
Após o processo de carregamento de dados, uma etapa de validação será realizada verificando o termo e o vetor de um item de amostra. Uma validação bem -sucedida será indicada pela saída exibida abaixo.
cd offline_to_online/recall/
python s2_item_to_es.py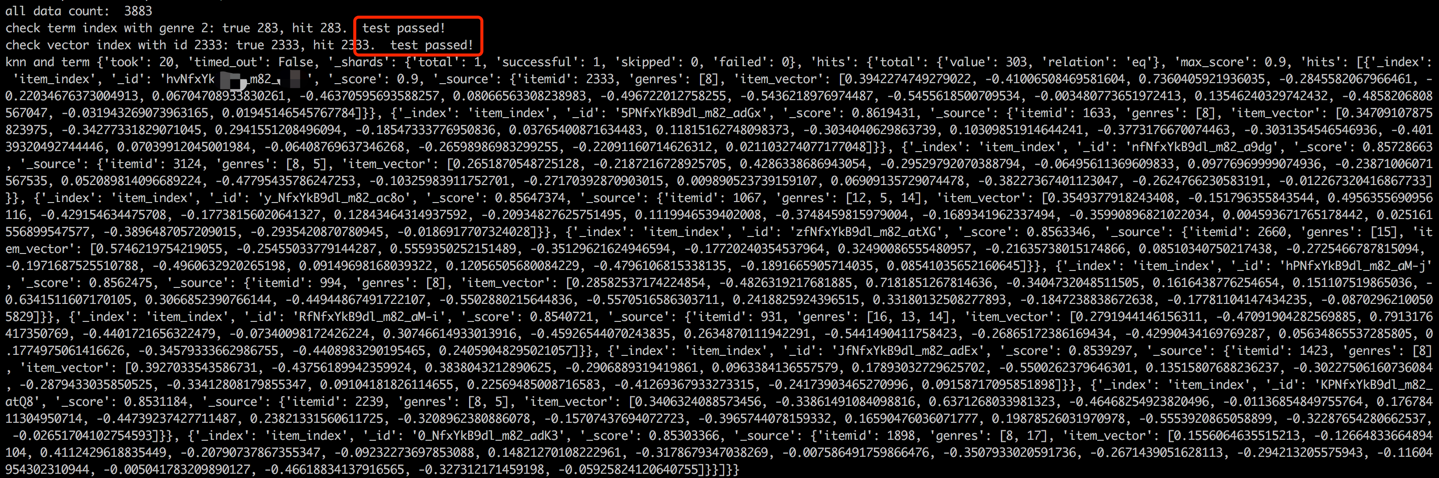
A Feast é a pioneira da loja de recursos de código aberto, mantendo o significado histórico nesse domínio. A festa inclui componentes offline e on -line. O componente offline facilita principalmente as junções de ponto-tempo. No entanto, como gerenciamos as junções pontuais em pandas, não há necessidade de utilizar as capacidades offline da Feast. Em vez disso, empregamos o Feast como uma loja de recursos on -line. A razão por trás de não usar o Feast for Point-in-time Juns reside no fato de que a Feast oferece principalmente recursos de armazenamento de recursos e carece de recursos de engenharia de recursos (embora tenha introduzido algumas transformações básicas nas versões recentes). A maioria das empresas prefere mecanismos de recursos personalizados com recursos mais poderosos. Portanto, não há necessidade de investir muito esforço para aprender o uso offline da Feast. É mais prático empregar ferramentas mais gerais, como pandas ou faíscas para processamento de recursos e alavancar o banquete apenas como um componente para o transporte de recursos entre offline e online.
Converta os arquivos de recurso do formato CSV em Parquet para atender aos requisitos da Feast.
cd offline_to_online/rank/
python s1_feature_to_feast.pyAbra um novo terminal (chamado terminal 2), inicie o contêiner de festa com 6566 como a porta HTTP e insira seu terminal interno executando os seguintes comandos.
cd data_exchange_center/online/feast
docker run --rm --name feast-server --entrypoint " bash " -v $( pwd ) :/home/hs -p 6566:6566 -it feastdev/feature-server:0.31.0Execute os seguintes comandos no terminal interno do contêiner de festa.
# Enter the config directory
cd /home/hs/ml/feature_repo
# Initialize the feature store from config files (read parquet to build database)
feast apply
# Load features from offline to online (defaults to sqlite, with options like Redis available)
feast materialize-incremental " $( date + ' %Y-%m-%d %H:%M:%S ' ) "
# Start the feature server
feast serve -h 0.0.0.0 -p 6566Depois de concluir todas as etapas, a seguinte saída será exibida.
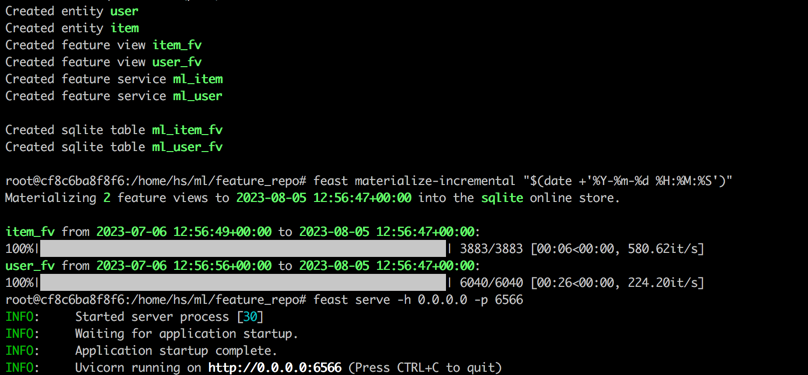
Voltando ao Terminal 1, execute o seguinte comando para testar se a festa estiver servindo corretamente. Uma string json de resposta será impressa se com sucesso.
curl -X POST
" http://localhost:6566/get-online-features "
-d ' {
"feature_service": "ml_item",
"entities": {
"itemid": [1,3,5]
}
} ' O Triton (Triton Inference Server) é uma inferência de código aberto mecanismo desenvolvido pela NVIDIA. O Triton Inference Server oferece suporte para uma gama diversificada de estruturas como Tensorflow, Pytorch, Onnx e opções adicionais, tornando -a uma excelente opção para a porção de modelos. Apesar de ser desenvolvido pela Nvidia, o Triton é versátil o suficiente para servir com as CPUs, oferecendo flexibilidade em seu uso. Embora uma solução da indústria mais prevalente envolva o TensorFlow -> SavedModel -> porção de tensorflow, o Triton está ganhando popularidade devido à sua adaptabilidade na troca entre diferentes estruturas. Portanto, neste projeto, adotamos um pipeline que utiliza Pytorch -> Onnx -> Triton Server.
Converta o modelo Pytorch em formato ONNX.
cd offline_to_online/rank/
python s2_model_to_triton.pyAbra um novo terminal (chamado terminal 3), inicie o contêiner Triton com 8000 como a porta HTTP e 8001 como a porta GRPC executando os seguintes comandos.
cd data_exchange_center/online/triton
docker run --rm -p8000:8000 -p8001:8001 -p8002:8002 -v $( pwd ) /:/models/ nvcr.io/nvidia/tritonserver:20.12-py3 tritonserver --model-repository=/models/
Voltando ao Terminal 1, execute o script para testar a consistência entre as pontuações offline e on -line de previsão. Esta etapa ajudará a garantir a confiabilidade do sistema de recomendação.
cd offline_to_online/rank/
python s3_check_offline_and_online.pyComo mostrado abaixo, as pontuações offline e online são idênticas, indicando a consistência entre offline e online.

Em ambientes industriais, os engenheiros geralmente optam por Java + Springboot ou Go + Gin como o back -end para os sistemas de recomendação. No entanto, neste projeto, por uma questão de facilidade de integração, o frasco Python + é utilizado. Vale a pena notar que existem várias estruturas da Web para Python, incluindo Django, Flask, FASTAPI e Tornado, todos capazes de rotear solicitações de repouso para funções de processamento. Qualquer uma dessas estruturas poderia atender aos nossos requisitos, o Flask foi selecionado aleatoriamente para este projeto.
Abra um novo terminal (chamado Terminal 4), inicie o Flask Web Server com 5000 como a porta HTTP executando os seguintes comandos.
conda activate rsppl
cd online/main
flask --app s1_server.py run --host=0.0.0.0
Voltar ao Terminal 1 e realizar um teste chamando o Serviço de Recomendação de um cliente (neste contexto, o cliente se refere ao serviço a montante que chama o Serviço de Recomendação, não os dispositivos de usuário). Os resultados serão retornados no formato JSON, com os 50 principais IDs de itens recomendados exibidos. Posteriormente, o serviço a jusante pode usar esses IDs de itens para recuperar seus atributos correspondentes e, em seguida, fornecê -los ao cliente (nesse contexto, dispositivo de usuário). Isso completa um fluxo de recomendação completo.
cd online/main
python s2_client.py


