recsys_pipeline
1.0.0
Bahasa Inggris | 中文
Menggunakan Dataset Movielens yang terkenal sebagai contoh, kami akan memperkenalkan pipa sistem Rekomendasi dari offline ke online, dengan semua operasi dapat dieksekusi pada satu laptop. Terlepas dari pemanfaatan beberapa komponen, penting untuk dicatat bahwa semuanya terkandung dalam Conda dan Docker, memastikan tidak ada dampak pada lingkungan setempat.
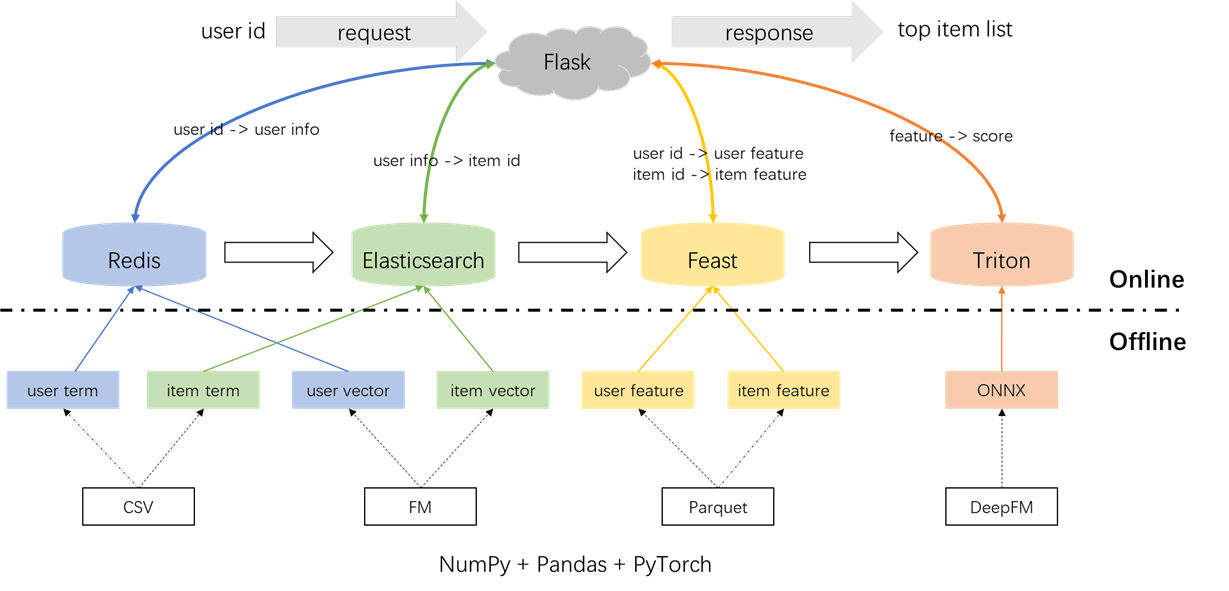
Arsitektur keseluruhan dari sistem rekomendasi diilustrasikan di bawah ini. Sekarang kami akan memperkenalkan proses pengembangan dan penyebaran untuk modul penarikan dan peringkat di tiga fase: offline, offline-to-online, dan online.
conda create -n rsppl python=3.8
conda activate rsppl
conda install --file requirements.txt --channel anaconda --channel conda-forge cd offline/preprocess/
python s1_data_split.py
python s2_term_trans.pyPreprocessing label, sampel, dan fitur:
Penting untuk menyoroti konsep gabungan point-in-time dalam file s2_term_trans.py. Secara khusus, selama pembuatan sampel pelatihan offline (imp_term.pkl), fitur hingga dan termasuk waktu tindakan yang paling dekat dengan saat ini harus digunakan. Menggunakan fitur setelah titik ini akan memperkenalkan kebocoran fitur, sedangkan menggunakan fitur yang secara signifikan jauh dalam waktu dari saat ini akan mengakibatkan ketidakkonsistenan antara offline dan online. Sebaliknya, fitur terbaru harus digunakan untuk melayani online (user_term.pkl dan item_term.pkl).
cd offline/recall/
python s1_term_recall.py
python s2_vector_recall.pyIstilah Recall: Komponen ini menggunakan interaksi pengguna sebelumnya dengan item ('Genre) dalam jendela waktu yang ditentukan untuk mencocokkan preferensi pengguna dengan item. Istilah -istilah ini akan dimuat ke Redis dan Elasticsearch nanti.
Penarikan vektor: Dalam komponen ini, FM (mesin faktorisasi) digunakan, hanya menggunakan ID pengguna dan ID item sebagai fitur. AUC yang dihasilkan (area di bawah kurva) = 0,8081. Setelah menyelesaikan fase pelatihan, vektor pengguna dan item diekstraksi dari pos pemeriksaan model dan akan dimuat ke Redis dan Elasticsearch untuk pemanfaatan selanjutnya.
cd offline/rank/
python s1_feature_engi.py
python s2_model_train.pySecara total, ada 59 fitur termasuk tiga jenis: fitur satu-panas (seperti UserID, itemID, jenis kelamin, dll.), Fitur multi-hot (genre), dan fitur padat (statistik perilaku historis).
Model peringkat yang digunakan adalah DeepFM, mencapai AUC 0,8206. Sementara Pytorch-FM adalah paket elegan untuk algoritma berbasis FM, ia memiliki dua batasan: 1. Ini secara eksklusif mendukung fitur yang jarang dan tidak memiliki dukungan untuk fitur padat. 2. Semua fitur yang jarang berbagi dimensi yang sama, yang melanggar intuisi bahwa "embedding id harus dimensi tinggi, sedangkan embedding info samping harus dimensi rendah.". Untuk mengatasi kendala ini, kami membuat modifikasi pada kode sumber, memungkinkan dukungan untuk fitur padat dan berbagai dimensi embedding untuk fitur yang jarang. Selain itu, tercatat bahwa modul embedding yang dalam berdampak negatif pada kinerja model, yang mendorong penghapusannya dari model. Akibatnya, struktur model saat ini terutama terdiri dari modul FM yang jarang yang diintegrasikan dengan MLP yang padat, itu bukan DeepFM konvensional.
Untuk mencegah dampak pada lingkungan lokal, Redis, Elasticsearch, Feast dan Triton semuanya dipekerjakan dalam wadah Docker. Untuk melanjutkan, pastikan bahwa Docker telah diinstal di laptop Anda, dan kemudian jalankan perintah berikut untuk mengunduh gambar Docker masing -masing.
docker pull redis:6.0.0
docker pull elasticsearch:8.8.0
docker pull feastdev/feature-server:0.31.0
docker pull nvcr.io/nvidia/tritonserver:20.12-py3Redis digunakan sebagai database untuk menyimpan informasi pengguna yang diperlukan untuk dipanggil kembali.
Mulai wadah Redis.
docker run --name redis -p 6379:6379 -d redis:6.0.0Proses ini melibatkan pemuatan istilah, vektor, dan filter pengguna ke Redis. Istilah dan data vektor dihasilkan di Bagian 1.2, sedangkan filter berkaitan dengan item yang telah berinteraksi dengan pengguna sebelumnya. Item yang difilter ini dikecualikan saat menghasilkan rekomendasi.
Setelah data dimuat, langkah validasi akan dilakukan dengan memeriksa data untuk pengguna sampel. Validasi yang berhasil akan ditunjukkan oleh output yang ditampilkan di bawah ini.
cd offline_to_online/recall/
python s1_user_to_redis.py
Elasticsearch digunakan untuk membuat indeks indeks terbalik dan indeks vektor untuk item. Awalnya dirancang untuk aplikasi pencarian, kasus penggunaan mendasar Elasticsearch melibatkan penggunaan kata -kata untuk mengambil dokumen. Dalam konteks sistem rekomendasi, kami memperlakukan item sebagai dokumen, dan istilah -istilahnya, seperti genre film, sebagai kata -kata. Ini memungkinkan kami untuk menggunakan Elasticsearch untuk mengambil item berdasarkan persyaratan ini. Konsep ini selaras dengan gagasan indeks terbalik, menjadikan Elasticsearch alat yang berharga untuk penarikan istilah dalam sistem rekomendasi. Untuk penarikan vektor, alat yang umum digunakan adalah FAISS yang bersumber dari Facebook. Namun, demi kemudahan integrasi, kami telah memilih untuk memanfaatkan kemampuan pengambilan vektor Elasticsearch. Elasticsearch telah mendukung pengambilan vektor sejak versi 7, dan perkiraan pengambilan tetangga K-Nearest (JST) sejak versi 8. Dalam proyek ini, kami menginstal versi Elasticsearch yaitu 8 (atau lebih tinggi). Pilihan ini dibuat karena pengambilan Knn yang tepat sering kali tidak dapat memenuhi persyaratan latensi rendah dari suatu sistem online.
Mulai wadah Elasticsearch dan masukkan terminal internalnya dengan melaksanakan perintah berikut.
docker run --name es8 -p 9200:9200 -it elasticsearch:8.8.0 Salin kata sandi yang ditampilkan di output terminal Anda (seperti yang ditunjukkan di bawah) dan tempel sebagai nilai ES_KEY di file data_exchange_center/constants.py. Langkah ini diperlukan karena Elasticsearch telah menerapkan persyaratan otentikasi kata sandi mulai dari versi 8.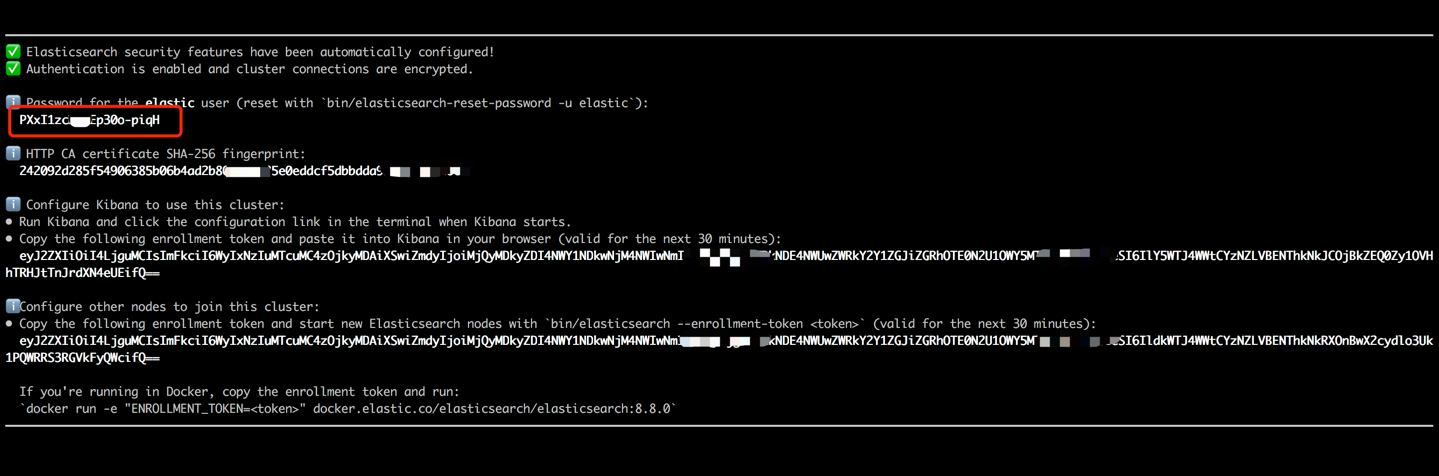
Setelah kata sandi telah ditempelkan, keluar dari terminal internal dengan menggunakan pintasan Ctrl+C (atau Command+C) keyboard. Tindakan ini juga akan menghentikan wadah, jadi kita perlu memulai kembali wadah Elasticsearch dan memastikannya berjalan di latar belakang sebagai bagian dari langkah -langkah selanjutnya.
docker start es8Muat istilah item untuk membuat indeks istilah dan memuat vektor item untuk membuat indeks vektor. Dalam pengaturan industri, kedua indeks ini biasanya dipisahkan untuk kinerja dan fleksibilitas yang lebih baik. Namun, untuk kesederhanaan dalam proyek ini, kami menggabungkannya menjadi satu indeks.
Mengikuti proses pemuatan data, langkah validasi akan dilakukan dengan memeriksa istilah dan vektor item sampel. Validasi yang berhasil akan ditunjukkan oleh output yang ditampilkan di bawah ini.
cd offline_to_online/recall/
python s2_item_to_es.py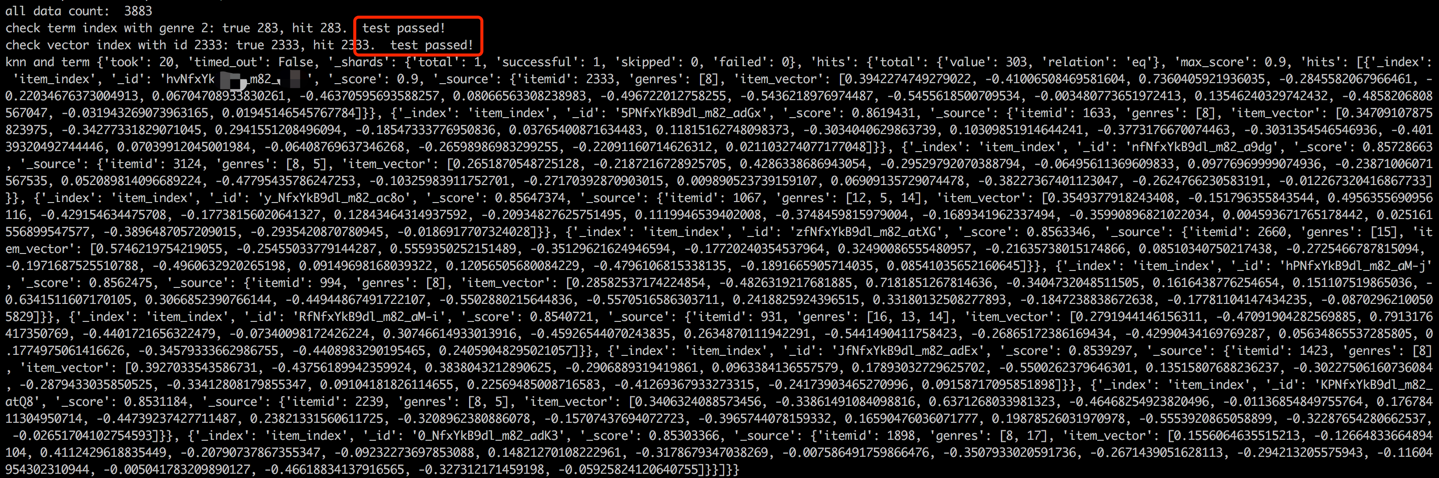
Pesta berdiri sebagai toko fitur open-source perintis, memegang signifikansi historis dalam domain ini. Pesta termasuk komponen offline dan online. Komponen offline terutama memfasilitasi gabungan point-in-time. Namun, karena kami telah mengelola gabungan point-in di panda sendiri, tidak ada keharusan untuk memanfaatkan kemampuan offline Feast. Sebaliknya, kami menggunakan pesta sebagai toko fitur online. Alasan di balik tidak menggunakan Pesta untuk gabungan point-in-time terletak pada fakta bahwa Pesta terutama menawarkan kemampuan penyimpanan fitur dan tidak memiliki kemampuan rekayasa fitur (meskipun telah memperkenalkan beberapa transformasi dasar dalam versi terbaru). Sebagian besar perusahaan lebih suka mesin fitur khusus dengan kemampuan yang lebih kuat. Oleh karena itu, tidak perlu menginvestasikan banyak upaya dalam mempelajari penggunaan offline Feast. Lebih praktis untuk menggunakan alat yang lebih umum seperti panda atau percikan untuk pemrosesan fitur dan memanfaatkan pesta semata -mata sebagai komponen untuk mengangkut fitur antara offline dan online.
Konversi file fitur dari CSV ke format parket untuk memenuhi persyaratan pesta.
cd offline_to_online/rank/
python s1_feature_to_feast.pyBuka terminal baru (disebut terminal 2), mulailah wadah pesta dengan 6566 sebagai port HTTP dan masukkan terminal internalnya dengan melaksanakan perintah berikut.
cd data_exchange_center/online/feast
docker run --rm --name feast-server --entrypoint " bash " -v $( pwd ) :/home/hs -p 6566:6566 -it feastdev/feature-server:0.31.0Jalankan perintah berikut di terminal internal wadah pesta.
# Enter the config directory
cd /home/hs/ml/feature_repo
# Initialize the feature store from config files (read parquet to build database)
feast apply
# Load features from offline to online (defaults to sqlite, with options like Redis available)
feast materialize-incremental " $( date + ' %Y-%m-%d %H:%M:%S ' ) "
# Start the feature server
feast serve -h 0.0.0.0 -p 6566Setelah menyelesaikan semua langkah, output berikut akan ditampilkan.
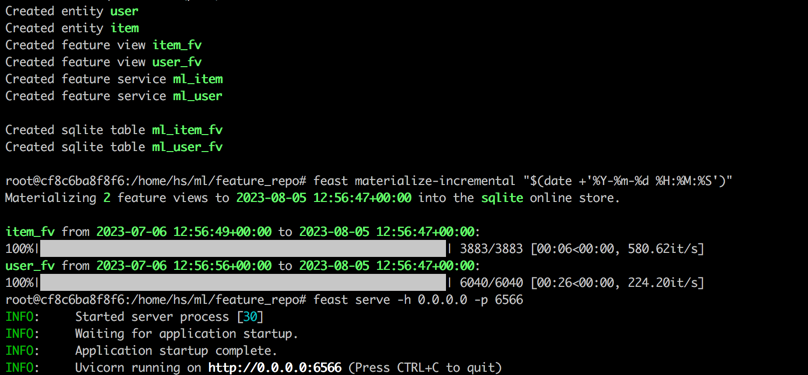
Kembali ke Terminal 1, jalankan perintah berikut untuk menguji apakah Pesta melayani dengan benar. String JSON respons akan dicetak jika berhasil.
curl -X POST
" http://localhost:6566/get-online-features "
-d ' {
"feature_service": "ml_item",
"entities": {
"itemid": [1,3,5]
}
} ' Triton (Triton Inference Server) adalah mesin pelayan inferensi open-source yang dikembangkan oleh NVIDIA. Triton Inference Server menawarkan dukungan untuk beragam kerangka kerja seperti TensorFlow, Pytorch, Onnx, dan opsi tambahan, menjadikannya pilihan yang sangat baik untuk menyajikan model. Meskipun dikembangkan oleh Nvidia, Triton cukup fleksibel untuk melayani dengan CPU, menawarkan fleksibilitas dalam penggunaannya. Sementara solusi industri yang lebih umum melibatkan TensorFlow -> SavedModel -> TensorFlow melayani, Triton mendapatkan popularitas karena kemampuan beradaptasi dalam beralih di antara kerangka kerja yang berbeda. Oleh karena itu, dalam proyek ini, kami mengadopsi pipa yang menggunakan Pytorch -> Onnx -> Triton Server.
Konversi model pytorch ke format ONNX.
cd offline_to_online/rank/
python s2_model_to_triton.pyBuka terminal baru (disebut terminal 3), mulailah wadah Triton dengan 8000 sebagai port HTTP dan 8001 sebagai port GRPC dengan mengeksekusi perintah berikut.
cd data_exchange_center/online/triton
docker run --rm -p8000:8000 -p8001:8001 -p8002:8002 -v $( pwd ) /:/models/ nvcr.io/nvidia/tritonserver:20.12-py3 tritonserver --model-repository=/models/
Kembali ke Terminal 1, jalankan skrip untuk menguji konsistensi antara skor prediksi offline dan online. Langkah ini akan membantu memastikan keandalan sistem rekomendasi.
cd offline_to_online/rank/
python s3_check_offline_and_online.pySeperti yang ditunjukkan di bawah ini, skor offline dan online identik, menunjukkan konsistensi antara offline dan online.

Dalam pengaturan industri, insinyur biasanya memilih java + springboot atau go + gin sebagai backend untuk sistem rekomendasi. Namun, dalam proyek ini demi kemudahan integrasi, Python + Flask digunakan. Perlu dicatat bahwa ada beberapa kerangka kerja web untuk Python, termasuk Django, Flask, Fastapi, dan Tornado, yang semuanya mampu merutekan permintaan RESTAPI ke fungsi untuk diproses. Kerangka kerja ini dapat memenuhi persyaratan kami, Flask dipilih secara acak untuk proyek ini.
Buka terminal baru (disebut terminal 4), mulailah server web Flask dengan 5000 sebagai port HTTP dengan mengeksekusi perintah berikut.
conda activate rsppl
cd online/main
flask --app s1_server.py run --host=0.0.0.0
Kembali ke Terminal 1 dan melakukan tes dengan memanggil layanan rekomendasi dari klien (dalam konteks ini, klien mengacu pada layanan hulu yang memanggil layanan rekomendasi, bukan perangkat pengguna). Hasilnya akan dikembalikan dalam format JSON, dengan 50 ID item yang disarankan yang disarankan ditampilkan. Selanjutnya, layanan hilir dapat menggunakan ID item ini untuk mengambil atribut yang sesuai dan kemudian memberikannya kepada klien (dalam konteks ini, perangkat pengguna). Ini melengkapi aliran rekomendasi penuh.
cd online/main
python s2_client.py


