full lattice search
2.0.0 for Elasticsearch 7.3.0

該Elasticsearch插件可以以概率晶格結構的形式進行搜索。這些晶格是按自動語音識別(ASR)或語音到文本(STT),光學特徵識別(OCR),機器翻譯(MT),自動圖像字幕等等形式輸出的形式。無論是分析的,都可以將晶格視為下面的有限狀態機器(FST)的一部分(一個可能的均設置)(在某些情況下)(均可置入均可構建的一個設置)(均可將其視為一個均可構建的一組)(文檔(例如,在下面的第一個位置,可能的輸出為“和a”)。在STT的情況下,位置將是時間範圍,在OCR的情況下,位置可以是XY坐標,或者可能是閱讀訂單位置。每個可能的輸出在該位置都有相關的發生概率,從而使相關評分受晶格輸出質量的影響。
該插件由三個組件組成:
lattice類型的令牌濾波器,該晶格處理晶格令牌流。流中的令牌表示令牌位置,允許流像上面的晶格結構一樣。流中的令牌還具有一個分數,該分數在索引時存儲在令牌有效載荷中,因此可以用來影響評分。
令牌過濾器以兩種格式之一接受令牌。使用lattice_format參數設置的格式,可以將其設置為lattice或audio 。
lattice_format=lattice令牌應該以形式
<token:string>|<position:int>|<rank:int>|<score:float>
示例流: the|0|0|0.9 , quick|1|0|0.6 brick|1|1|0.2 fox|2|0|0.5 | 0 | 0 | 0 | box|2|1|0.09 , jumped|3|0|1.0
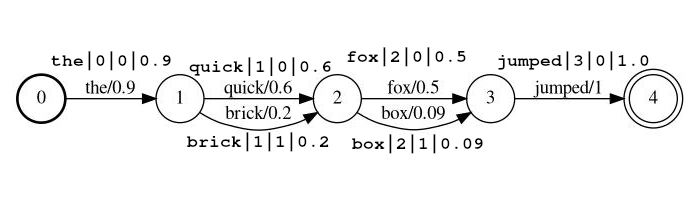
在上面的示例中,令牌quick和brick將在同一位置處為索引,因為它們都設置為1。
token實際字符串令牌要搜索並通過後續過濾器處理position是代幣在源文檔中的全局位置(用於確定令牌是否應與以前的令牌同一位置位置)rank令牌的等級相對於該位置處的其他可能令牌(0是最可能的等級)score 。這個立場在此位置的可能性。請注意,如果您的分數為零,則令牌不會返回是搜索,並且可能會從流中省略。 lattice_format=audio代幣通過添加start_time和stop_time具有從lattice格式的所有字段。
令牌應該以形式
<token:string>|<position:int>|<rank:int>|<score:float>|<start_time:float>|<stop_time:float>
Example stream: the|0|0|0.9|0.15|0.25 , quick|1|0|0.6|0.25|0.5 , brick|1|1|0.2|0.25|0.5 , fox|2|0|0.5|1.0|1.3 , box|2|1|0.09|1.0|1.3 , jumped|3|0|1.0|2.0|2.5
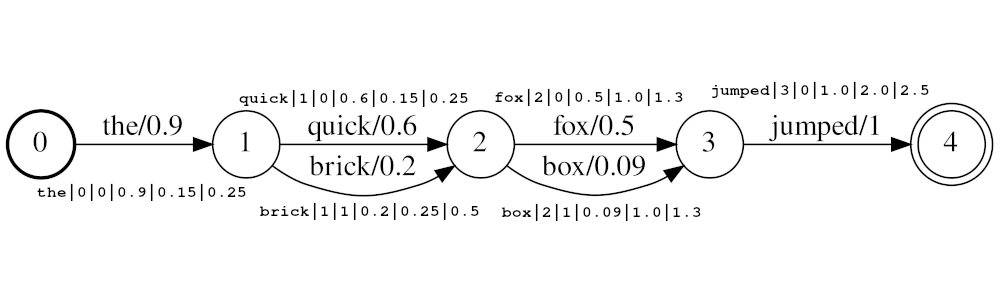
在audio_position_increment_seconds的示例中,令牌quick和brick將在同一位置處為索引,因為它們都將位置設置為1。目前,該過濾器僅看起來是像徵性的開始時間
如果audio_position_increment_seconds=0.01在上面的示例中the則將以15的位置索引; quick和brick將在25個位置索引; ETC。
start_time相對於源音頻的開頭,該令牌的開始時間秒stop_time相對於源音頻的開頭,此令牌的開始時間參數包括:
lattice_format (默認為晶格)audio或latticeaudio_position_increment_secondsscore_buckets (默認不重複)[0.9, 10, 0.8, 8, 0.7, 7, 0.2, 1]的值,得分> = 0.9的令牌將重複10次;分數> = 0.8的令牌將重複8次,等等。audio_position_increment_seconds (默認為0.01)lattice=format=audio這是在索引中編碼音頻時間的精度floor(token_start_time / audio_position_increment_seconds)類型lattice字段包含LatticeTokenFilter的參數,可在搜索時間參考。函數完全像文本字段。
如果使用lattice_format=audio則需要使用lattice字段類型進行Matchlatticequeries與時間正確工作。
注意:這僅是因為目前似乎沒有一種方法可以從查詢時間從分析儀那裡獲取必要的信息(或任何)信息。我認為在AnalysisRegistry中,可能會在AnalysisProvider中添加一個類似於分析的getChainAware() SynonymGraphTokenFilterFactory.getChainAwareTokenFilterFactory()類似的方法。 (有關更多詳細信息,請參閱此類頂部的評論)
參數包括:
lattice_format必須匹配該字段上設置的LatticeTokenFilter的配置。audio_position_increment_seconds必須匹配該字段上LatticeTokenFilter的配置。 type match_lattice的查詢查詢使用lattice令牌過濾器配置的lattice字段。
執行包裹在LatticePayloadScoreQuery(PayloadScoreQuery的擴展)中的Spannearquery,該QuaryQuery(PayloadScoreQuery的擴展)使用每個令牌有效載荷中編碼的分數來得分匹配匹配跨度。每個跨度的分數合併以給出文檔分數(有關詳細信息,請參見payload_function參數)。如果設置了include_span_score ,則以上分數將乘以配置的相似性分數。
參數包括:
sloplattice_format=audio時使用的slop_seconds 。最多幾秒鐘允許比賽跨度。in_order是否必須按順序出現令牌(對於lattice_format=audio應該是true )include_span_score如果為true則配置的相似性分數將乘以有效載荷分數(如上所述)payload_function sum , max或min之一(默認為sum )sum總和匹配跨度的得分max從所有匹配跨度中選擇最大分數min從所有匹配跨度中選擇最小分數payload_length_norm_factor a float定義匹配跨度的長度應標準化跨度分數。一個值的值意味著分數除以跨度的長度(請在lucene術語中以跨度的寬度為單位)。值為0表示沒有長度歸一化。 使用payload_function使用match_lattice查詢payload_function=sum計算文檔分數(principtal)為
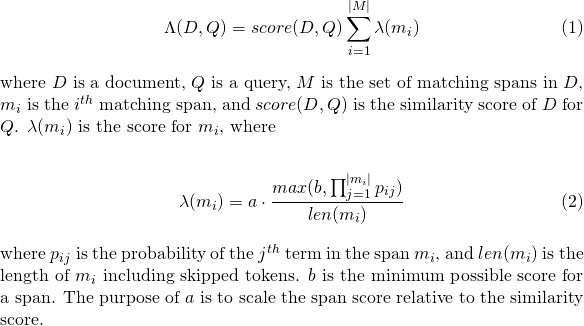
同樣, payload_function=min
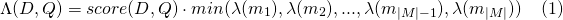
和payload_function=max
為了開發,您可以使用下面的Docker映像,這些圖像僅取自官方的Elasticsearch圖像並安裝此插件。您可以閱讀此信息,以獲取有關如何使用Elasticsearch圖像的說明。
docker pull messiaen/full-lattice-search:2.0.0-7.3.0
docker-compose.yaml示例:
version : " 2 "
services :
kibana :
image : docker.elastic.co/kibana/kibana:7.3.0
ports :
- 5601:5601
environment :
ELASTICSEARCH_HOSTS : http://es01:9200
es01 :
image : messiaen/full-lattice-search:2.0.0-7.3.0
environment :
- node.name=es01
- discovery.type=single-node
- " ES_JAVA_OPTS=-Xms1024m -Xmx1024m "
ulimits :
memlock :
soft : -1
hard : -1
volumes :
- esdata01:/usr/share/elasticsearch/data
ports :
- 9200:9200
volumes :
esdata01 :
driver : local只需將上面的yaml複製到名為docker-compose.yaml的文件中,然後從該目錄運行docker-compose up
假設您在瀏覽器中使用docker-compose.yaml導航到localhost:5601 ,然後將以下示例粘貼到Kibana的Dev Tools Console中。
PUT audio_lattices
{
"settings": {
"index": {
"number_of_shards": 1,
"number_of_replicas": 0
},
"analysis": {
"analyzer": {
"lattice_analyzer": {
"type": "custom",
"tokenizer": "whitespace",
"filter": ["lattice_filter", "lowercase"]
}
},
"filter": {
"lattice_filter": {
"type": "lattice",
"lattice_format": "audio",
"audio_position_increment_seconds": 0.1
}
}
}
},
"mappings": {
"dynamic": "strict",
"properties": {
"lattices": {
"type": "lattice",
"lattice_format": "audio",
"audio_position_increment_seconds": 0.1,
"analyzer": "lattice_analyzer"
}
}
}
}
POST audio_lattices/_doc/1
{
"lattices": """the|0|0|0.9|0.15|0.25
quick|1|0|0.6|0.25|0.5 brick|1|1|0.2|0.25|0.5
fox|2|0|0.5|1.0|1.3 box|2|1|0.09|1.0|1.3
jumped|3|0|1.0|2.0|2.5"""
}
GET audio_lattices/_search
{
"query": {
"match_lattice": {
"lattices": {
"query": "quick box jumped",
"slop_seconds": 2,
"include_span_score": "true",
"payload_function": "sum",
"in_order": "true"
}
}
}
}
在控制台中查看
搜索響應
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 36.987705,
"hits" : [
{
"_index" : "audio_lattices",
"_type" : "_doc",
"_id" : "1",
"_score" : 36.987705,
"_source" : {
"lattices" : """
the|0|0|0.9|0.15|0.25
quick|1|0|0.6|0.25|0.5 brick|1|1|0.2|0.25|0.5
fox|2|0|0.5|1.0|1.3 box|2|1|0.09|1.0|1.3
jumped|3|0|1.0|2.0|2.5
"""
}
}
]
}
}
PUT text_lattices
{
"settings": {
"index": {
"number_of_shards": 1,
"number_of_replicas": 0
},
"analysis": {
"analyzer": {
"lattice_analyzer": {
"type": "custom",
"tokenizer": "whitespace",
"filter": ["lattice_filter", "lowercase"]
}
},
"filter": {
"lattice_filter": {
"type": "lattice",
"lattice_format": "lattice"
}
}
}
},
"mappings": {
"dynamic": "strict",
"properties": {
"lattices": {
"type": "lattice",
"lattice_format": "lattice",
"analyzer": "lattice_analyzer"
}
}
}
}
POST text_lattices/_doc/1
{
"lattices": """the|0|0|0.9
quick|1|0|0.6 brick|1|1|0.2
fox|2|0|0.5 box|2|1|0.09
jumped|3|0|1.0"""
}
GET text_lattices/_search
{
"query": {
"match_lattice": {
"lattices": {
"query": "quick jumped",
"slop": 1,
"include_span_score": "true",
"payload_function": "sum",
"in_order": "true"
}
}
}
}
在控制台中查看
搜索響應
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 9041.438,
"hits" : [
{
"_index" : "text_lattices",
"_type" : "_doc",
"_id" : "1",
"_score" : 9041.438,
"_source" : {
"lattices" : """
the|0|0|0.9
quick|1|0|0.6 brick|1|1|0.2
fox|2|0|0.5 box|2|1|0.09
jumped|3|0|1.0
"""
}
}
]
}
}
只需在根目錄中運行make
如果您只想在不運行測試的情況下構建插件,則可以運行
./gradlew clean assemble
無論哪種情況,內置的插件都將是build/distributions/full-lattice-search-*.zip
make run將構建插件並站起來一個Elasticsearch(安裝了插件)和帶有Docker-Compose的Kibana
需要Elasticsearch 7.3.0(支持其他版本(> = 6.0.0)即將到來 /應要求)

該插件的目的不是與廣義晶格結構一起使用,而是使用稱為混亂網絡或香腸字符串的壓縮形式。混淆網絡代表具有固定位置(時間範圍,圖像位置等)的廣義晶格。
每個位置都有一組可能的單詞,每個單詞都有相關的發生的可能性。
例如,自動語音識別器可以在下面產生晶格
“每個視頻都應在10分鐘以下”

上面的晶格可以壓縮到下面的混淆網絡中。

請注意,已插入<epsilon>令牌(意味著缺少一個單詞),以允許“理解”一詞比其他單詞更長。
還值得注意的是,將晶格壓縮到混淆網絡中的過程通常是有損的,這意味著通過混亂網絡的某些路徑不存在於源晶格中。例如, “理解十分鐘”一詞存在於混亂網絡中,但不在晶格中。
請注意,您有責任確保將晶格結構格式化為混亂網絡。
有關使用詳細信息,請參見LatticeTokenFilter文檔。
如LatticeTokenFilter文檔中所述, score_buckets參數可用於在相同位置進行索引重複令牌,以提高這些令牌相對於那裡得分的術語頻率。儘管這確實具有理想的影響,但很少考慮。
8x線性重複( score_buckets=[0.9, 72, 0.8, 64, 0.7, 56, 0.6, 48, 0.5, 40, 0.4, 32, 0.2, 16, 0.1, 8, 0.01, 2] )在與較少的配置中更差。8x重複配置的索引過程中,在1中刪除了1倍的分析流中的分析流中,導致了5x速度的分析流中,以刪除了8倍重複配置的索引。

