full lattice search
2.0.0 for Elasticsearch 7.3.0

Este complemento ElasticSearch permite la búsqueda a través de las transcripciones en forma de estructuras de red probabilística. Estas redes están en la salida de formulario mediante reconocimiento de voz automatizado (ASR) o Speech-to-Text (STT), Reconocimiento de caracteres ópticos (OCR), traducción automática (MT), subtítulos de imagen automatizados, etc. Las retrasos, independientemente del análisis, se pueden ver como la estructura de la máquina de la máquina finita (FST) a continuación, donde cada conjunto de arcos (transición de un estado a otro) representa un conjunto posible de la fuente de la fuente de la fuente de la fuente de la fuente de la fuente de la fuente de la fuente de la fuente (por ejemplo, en la primera ubicación a continuación, las posibles salidas son 'y' a '). En el caso de STT, las ubicaciones serían rangos de tiempo, en el caso de OCR, las ubicaciones podrían ser coordenadas XY, o tal vez una ubicación de orden de lectura. Cada salida posible tiene una probabilidad asociada de ocurrencia en esa ubicación, lo que permite que la puntuación de relevancia se vea afectada por la calidad de la salida de la red.
El complemento consta de tres componentes:
Un filtro de token de lattice de tipo que procesa una secuencia de tokens de celosía. Los tokens en la corriente indican la posición del token, permitiendo que la corriente represente una estructura de red como la anterior. Los tokens en la corriente también tienen una puntuación, que se almacena en la carga útil del token cuando se indexa para que se pueda usar para afectar la puntuación.
El filtro de tokens acepta tokens en uno de los dos formatos. El formato establecido con el parámetro lattice_format , que se puede configurar en lattice o audio .
lattice_format=latticeLos tokens deben estar en la forma
<token:string>|<position:int>|<rank:int>|<score:float>
Ejemplo de transmisión: the|0|0|0.9 , quick|1|0|0.6 , brick|1|1|0.2 , fox|2|0|0.5 , box|2|1|0.09 , jumped|3|0|1.0
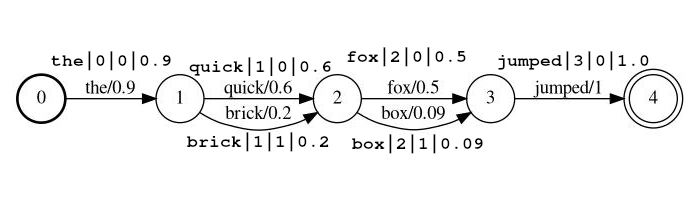
En el ejemplo anterior, los tokens quick y brick serán índice en la misma posición, porque ambos tienen una posición establecida en 1.
token El token de cadena real para ser buscado y para ser procesado por filtros de seguimientoposition es la posición global del token en el documento de origen (utilizado para determinar si el token debe ser lugares en la misma ubicación que el token anterior)rank de rango del token en relación con los otros tokens posibles en esta posición (0 es el rango más probable)score un flotador entre 0.0 y 1.0 (inclusive). La probabilidad de un token en esta posición. Tenga en cuenta que si realmente tiene una puntuación de cero, el token no volverá es una búsqueda, y probablemente debería omitirse desde la transmisión. lattice_format=audio Los tokens tienen todos los campos del formato lattice con la adición de start_time y stop_time .
Los tokens deben estar en la forma
<token:string>|<position:int>|<rank:int>|<score:float>|<start_time:float>|<stop_time:float>
Ejemplo de transmisión: the|0|0|0.9|0.15|0.25 , quick|1|0|0.6|0.25|0.5 , brick|1|1|0.2|0.25|0.5 , fox|2|0|0.5|1.0|1.3 , box|2|1|0.09|1.0|1.3 , jumped|3|0|1.0|2.0|2.5
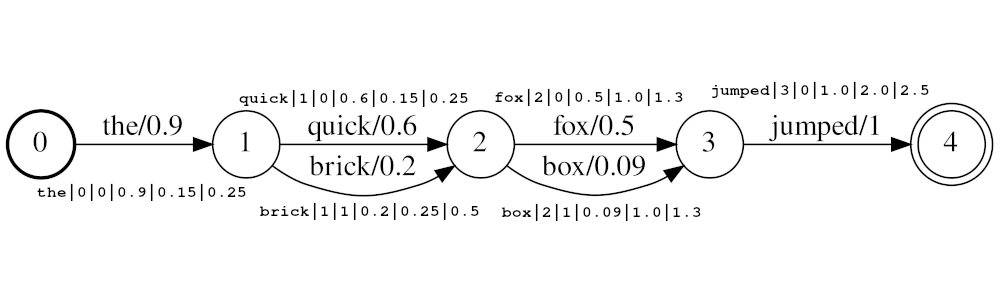
En el ejemplo anterior, los tokens quick y brick serán índice en la misma posición, porque ambos tienen una posición establecida en 1. El valor de posición real de los tokens está determinado por los tiempos y audio_position_increment_seconds . Actualmente, el filtro solo parece un horario de inicio de token
Si audio_position_increment_seconds=0.01 en el ejemplo anterior the indexaría con una posición de 15; quick y brick se indexarían en una posición de 25; etc.
start_time la hora de inicio en segundos de este token en relación con el comienzo del audio de origenstop_time la hora de inicio en segundos de este token en relación con el comienzo del audio de origenLos parámetros incluyen:
lattice_format (el valor predeterminado es la red)audio o latticeaudio_position_increment_secondsscore_buckets (el valor predeterminado no es duplicación)[0.9, 10, 0.8, 8, 0.7, 7, 0.2, 1] , los tokens con una puntuación> = 0.9 se duplicarán 10 veces; Los tokens con una puntuación> = 0.8 se duplicarán 8 veces, etc.audio_position_increment_seconds (el valor predeterminado es 0.01)lattice=format=audio esta es la precisión a la que los tiempos de audio están codificados en posición en el índicefloor(token_start_time / audio_position_increment_seconds) Un campo de lattice de tipo contiene parámetros de LatticeTokenFilter para referencia en el momento de la búsqueda. Funciona exactamente como un campo de texto.
Si usa lattice_format=audio debe usar un tipo de campo de lattice para MatchLatticequeries para funcionar correctamente con los tiempos.
Nota: Esto solo existe porque actualmente no parece haber una forma de obtener la información necesaria (o cualquier) del analizador en el momento de la consulta. Creo que podría haber un getChainAware() o un método similar agregado a AnalysisProvider Funcioning de manera similar a SynonymGraphTokenFilterFactory.getChainAwareTokenFilterFactory() dentro de AnalysisRegistry . (Para más detalles, consulte el comentario en la parte superior de esta clase)
Los parámetros incluyen:
lattice_format debe coincidir con la configuración del conjunto LatticeTokenFilter establecido en este campo.audio_position_increment_seconds debe coincidir con la configuración del conjunto LatticeTokenFilter en este campo. Una consulta de Tipo match_lattice consulta Un campo lattice configurado con un filtro de token lattice .
Realiza una SpannearQuery envuelta en un LatticePayLoadScoreQuery (Extensión de PayloadScoreQuery), que utiliza los puntajes codificados en cada carga útil de token para calificar los tramos coincidentes. La puntuación de cada tramo se combina para dar la puntuación del documento (consulte el parámetro payload_function para más detalles). Si se establece include_span_score , la puntuación anterior se multiplica por la puntuación de similitud configurada.
Los parámetros incluyen:
slop de tokens omitidos permitidos en el partidoslop_seconds usado cuando lattice_format=audio . Secondes máximos El partido puede abarcar.in_order si el token debe aparecer en orden (debe ser true para lattice_format=audio )include_span_score Si true el puntaje de similitud configurado se multiplicará con el puntaje de carga útil (descrito anteriormente)payload_function uno de sum , max o min (el valor predeterminado es sum )sum suma los puntajes de los tramos a juegomax selecciona el puntaje máximo de todos los tramos coincidentesmin selecciona el puntaje min de todos los tramos coincidentespayload_length_norm_factor Un flotador Definición de cuánto la longitud del tramo de coincidencia debe normalizar el puntaje del tramo. Un valor de uno significa que la puntuación se divide por la longitud del tramo (tenga en cuenta esto no en el ancho del tramo en términos de Lucene). Un valor de 0 significa que no hay normalización de longitud. Cuando se usa una consulta match_lattice con payload_function=sum se calcula una puntuación de documento (en principal) como
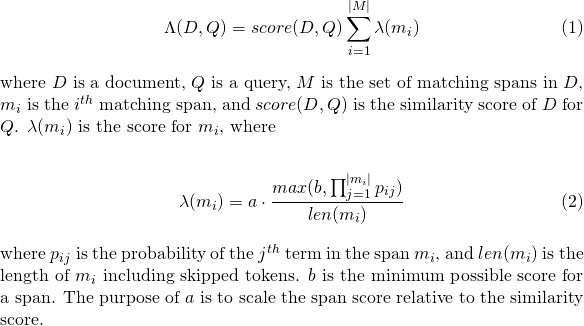
De manera similar para payload_function=min
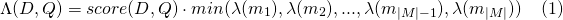
Y para payload_function=max
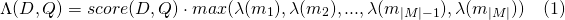
Para el desarrollo, puede usar la imagen de Docker a continuación, que simplemente toma de la imagen oficial de Elasticsearch e instala este complemento. Puede leer esto para obtener instrucciones sobre cómo usar las imágenes Elasticsearch.
docker pull messiaen/full-lattice-search:2.0.0-7.3.0
docker-compose.yaml Ejemplo:
version : " 2 "
services :
kibana :
image : docker.elastic.co/kibana/kibana:7.3.0
ports :
- 5601:5601
environment :
ELASTICSEARCH_HOSTS : http://es01:9200
es01 :
image : messiaen/full-lattice-search:2.0.0-7.3.0
environment :
- node.name=es01
- discovery.type=single-node
- " ES_JAVA_OPTS=-Xms1024m -Xmx1024m "
ulimits :
memlock :
soft : -1
hard : -1
volumes :
- esdata01:/usr/share/elasticsearch/data
ports :
- 9200:9200
volumes :
esdata01 :
driver : local Simplemente copie el YAML anterior en un archivo llamado Docker-Compose.yaml, y desde ese directorio ejecuta docker-compose up
Suponiendo que está utilizando el docker-compose.yaml anterior, navegue a localhost:5601 en su navegador y pegue los siguientes ejemplos en la consola Dev Tools de Kibana.
PUT audio_lattices
{
"settings": {
"index": {
"number_of_shards": 1,
"number_of_replicas": 0
},
"analysis": {
"analyzer": {
"lattice_analyzer": {
"type": "custom",
"tokenizer": "whitespace",
"filter": ["lattice_filter", "lowercase"]
}
},
"filter": {
"lattice_filter": {
"type": "lattice",
"lattice_format": "audio",
"audio_position_increment_seconds": 0.1
}
}
}
},
"mappings": {
"dynamic": "strict",
"properties": {
"lattices": {
"type": "lattice",
"lattice_format": "audio",
"audio_position_increment_seconds": 0.1,
"analyzer": "lattice_analyzer"
}
}
}
}
POST audio_lattices/_doc/1
{
"lattices": """the|0|0|0.9|0.15|0.25
quick|1|0|0.6|0.25|0.5 brick|1|1|0.2|0.25|0.5
fox|2|0|0.5|1.0|1.3 box|2|1|0.09|1.0|1.3
jumped|3|0|1.0|2.0|2.5"""
}
GET audio_lattices/_search
{
"query": {
"match_lattice": {
"lattices": {
"query": "quick box jumped",
"slop_seconds": 2,
"include_span_score": "true",
"payload_function": "sum",
"in_order": "true"
}
}
}
}
Ver en la consola
Respuesta de búsqueda
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 36.987705,
"hits" : [
{
"_index" : "audio_lattices",
"_type" : "_doc",
"_id" : "1",
"_score" : 36.987705,
"_source" : {
"lattices" : """
the|0|0|0.9|0.15|0.25
quick|1|0|0.6|0.25|0.5 brick|1|1|0.2|0.25|0.5
fox|2|0|0.5|1.0|1.3 box|2|1|0.09|1.0|1.3
jumped|3|0|1.0|2.0|2.5
"""
}
}
]
}
}
PUT text_lattices
{
"settings": {
"index": {
"number_of_shards": 1,
"number_of_replicas": 0
},
"analysis": {
"analyzer": {
"lattice_analyzer": {
"type": "custom",
"tokenizer": "whitespace",
"filter": ["lattice_filter", "lowercase"]
}
},
"filter": {
"lattice_filter": {
"type": "lattice",
"lattice_format": "lattice"
}
}
}
},
"mappings": {
"dynamic": "strict",
"properties": {
"lattices": {
"type": "lattice",
"lattice_format": "lattice",
"analyzer": "lattice_analyzer"
}
}
}
}
POST text_lattices/_doc/1
{
"lattices": """the|0|0|0.9
quick|1|0|0.6 brick|1|1|0.2
fox|2|0|0.5 box|2|1|0.09
jumped|3|0|1.0"""
}
GET text_lattices/_search
{
"query": {
"match_lattice": {
"lattices": {
"query": "quick jumped",
"slop": 1,
"include_span_score": "true",
"payload_function": "sum",
"in_order": "true"
}
}
}
}
Ver en la consola
Respuesta de búsqueda
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 9041.438,
"hits" : [
{
"_index" : "text_lattices",
"_type" : "_doc",
"_id" : "1",
"_score" : 9041.438,
"_source" : {
"lattices" : """
the|0|0|0.9
quick|1|0|0.6 brick|1|1|0.2
fox|2|0|0.5 box|2|1|0.09
jumped|3|0|1.0
"""
}
}
]
}
}
Simplemente ejecute make en el directorio de raíz
Si desea construir solo el complemento sin ejecutar pruebas, puede ejecutar
./gradlew clean assemble
En cualquier caso, el complemento construido será build/distributions/full-lattice-search-*.zip
make run construirá el complemento y se mantendrá un ElasticSearch (con el complemento instalado) y un Kibana con Docker-Compose
Requiere Elasticsearch 7.3.0 (soporte para otras versiones (> = 6.0.0) Próximamente / bajo solicitud)

Este complemento no está diseñado para funcionar con estructuras de red generalizadas, sino para trabajar con una forma comprimida conocida como red de confusión o cadena de salchichas . Una red de confusión representa una red generalizada con un conjunto fijo de posiciones (rangos de tiempo, ubicaciones de imágenes, etc.).
Cada posición tiene un conjunto de posibles palabras, y cada palabra tiene una probabilidad asociada de ocurrencia.
Por ejemplo, un reconocedor de voz automatizado podría generar la red a continuación donde el hablante realmente dijo
"Cada video debe tener menos de diez minutos"

La red de arriba se puede comprimir en la red de confusión a continuación.

Tenga en cuenta que los tokens <epsilon> (lo que significa la ausencia de una palabra) se han insertado para permitir que la palabra "comprender" tenga una duración más larga que otras.
También vale la pena señalar que el proceso de comprimir una red en una red de confusión es generalmente con pérdida, lo que significa que algunas rutas a través de una red de confusión no están presentes en la red de origen. Por ejemplo, la frase "Be Entender Diez minutos" está presente en la red de confusión, pero no en la red.
Tenga en cuenta que es responsable de garantizar que sus estructuras de celosía estén formateadas en redes de confusión.
Consulte los documentos de LatticeKokenFilter para obtener detalles de uso.
Como se mencionó en los documentos LatticeTokenFilter, el parámetro score_buckets puede usarse para indexar tokens duplicados en la misma posición para aumentar la frecuencia de término de esos tokens en relación con la puntuación. Aunque esto tiene el efecto deseado, hay pocas consideraciones.
8x de tokens ( score_buckets=[0.9, 72, 0.8, 64, 0.7, 56, 0.6, 48, 0.5, 40, 0.4, 32, 0.2, 16, 0.1, 8, 0.01, 2] ) realizaron mucho mejor que las configuraciones con menos duplicación.8x en 1, eliminando el filtro de token fonético del flujo de análisis que resultó en una velocidad de 5X en la indexación.

