full lattice search
2.0.0 for Elasticsearch 7.3.0

Ce plugin ElasticSearch permet la recherche entre les transcriptions sous forme de structures de réseau probabiliste. These lattices are in the form output by Automated Speech Recognition (ASR) or Speech-to-text (STT), Optical Character recognition (OCR), Machine Translation (MT), Automated Image Captioning, etc. The lattices, regardless of the analytic, can be viewed as the Finite State Machine (FST) structure below, where each set of arcs (transitioning from one state to another) represents a set of possible outputs at some location in the source document (par exemple, au premier emplacement ci-dessous, les sorties possibles sont «les» et «a»). Dans le cas de STT, les emplacements seraient des gammes de temps, dans le cas de l'OCR, les emplacements pourraient être des coordonnées XY, ou peut-être un emplacement de commande de lecture. Chaque sortie possible a une probabilité d'occurrence associée à cet emplacement permettant à la notation de pertinence d'être affectée par la qualité de la sortie du réseau.
Le plugin se compose de trois composants:
Un filtre à jeton de lattice de type qui traite un flux de jeton de réseau. Les jetons dans le flux indiquent la position de jeton, permettant au flux de représenter une structure de réseau comme celle ci-dessus. Les jetons dans le flux ont également un score, qui est stocké dans la charge utile du jeton lorsqu'il est indexé, de sorte que cela peut être utilisé pour affecter la notation.
Le filtre de jeton accepte les jetons dans l'un des deux formats. Le format défini avec le paramètre lattice_format , qui peut être défini sur lattice ou audio .
lattice_format=latticeLes jetons doivent être sous la forme
<token:string>|<position:int>|<rank:int>|<score:float>
Exemple de flux: the|0|0|0.9 , quick|1|0|0.6 , brick|1|1|0.2 , fox|2|0|0.5 , box|2|1|0.09 , jumped|3|0|1.0
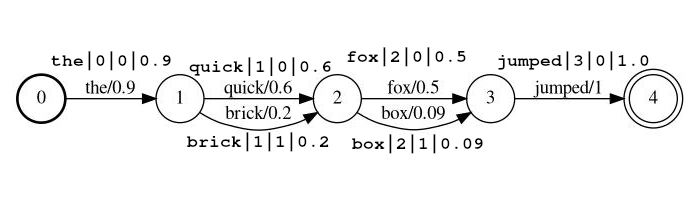
Dans l'exemple ci-dessus, les jetons quick et brick seront indexés à la même position, car ils ont tous deux une position définie sur 1.
token Le jeton de chaîne réel à fouiller et à traiter par des filtres de suiviposition est la position globale du jeton dans le document source (utilisé pour déterminer si le jeton doit être des places au même endroit que le jeton précédent)rank du rang du jeton par rapport aux autres jetons possibles à cette position (0 est le rang le plus probable)score un flotteur entre 0,0 et 1,0 (inclusif). La probabilité de ce jeton à cette position. Remarque Si vous avez réellement un score de zéro, le jeton ne reviendra pas est une recherche et devrait probablement être omis du flux. lattice_format=audio Les jetons ont tous les champs du format lattice avec l'ajout de start_time et stop_time .
Les jetons doivent être sous la forme
<token:string>|<position:int>|<rank:int>|<score:float>|<start_time:float>|<stop_time:float>
Exemple de flux: the|0|0|0.9|0.15|0.25 , quick|1|0|0.6|0.25|0.5 , brick|1|1|0.2|0.25|0.5 , fox|2|0|0.5|1.0|1.3 , box|2|1|0.09|1.0|1.3 , jumped|3|0|1.0|2.0|2.5
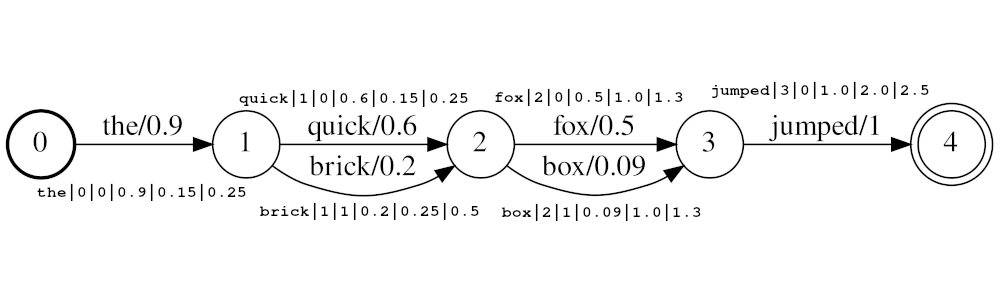
Dans l'exemple ci-dessus, les jetons quick et brick seront indexés à la même position, car ils ont tous deux une position définie sur 1. La valeur de position réelle des jetons est déterminée par le temps et audio_position_increment_seconds . Actuellement, le filtre n'a l'air que des heures de début de jeton
Si audio_position_increment_seconds=0.01 dans l'exemple ci-dessus the indexé avec une position de 15; quick et brick seraient indexés à une position de 25; etc.
start_time l'heure de début en secondes de ce jeton par rapport au début de l'audio sourcestop_time l'heure de début en secondes de ce jeton par rapport au début de l'audio sourceLes paramètres incluent:
lattice_format (par défaut est un réseau)audio ou latticeaudio_position_increment_secondsscore_buckets (par défaut n'est pas une duplication)[0.9, 10, 0.8, 8, 0.7, 7, 0.2, 1] , les jetons avec un score> = 0,9 seront dupliqués 10 fois; Les jetons avec un score> = 0,8 seront dupliqués 8 fois, etc.audio_position_increment_seconds (par défaut est 0,01)lattice=format=audio c'est la précision à laquelle les temps audio sont codés en position dans l'indexfloor(token_start_time / audio_position_increment_seconds) Un champ de lattice de type contient des paramètres de LatticeTokenFilter pour référence au moment de la recherche. Fonctionne exactement comme un champ de texte.
Si vous utilisez lattice_format=audio vous devez utiliser un type de champ de lattice pour MatchlatticeCeries pour fonctionner correctement avec les temps.
Remarque: cela n'existe que car actuellement il ne semble pas y avoir de moyen d'obtenir les informations nécessaires (ou aucune) de l'analyseur au moment de la requête. Je pense qu'il pourrait y avoir une méthode getChainAware() ou similaire ajoutée à AnalysisProvider fonctionnant similaire à SynonymGraphTokenFilterFactory.getChainAwareTokenFilterFactory() dans AnalysisRegistry . (Pour plus de détails, consultez le commentaire en haut de cette classe)
Les paramètres incluent:
lattice_format doit correspondre à la configuration de l'ensemble LatticeTokenFilter sur ce champ.audio_position_increment_seconds doit correspondre à la configuration de l'ensemble LatticeTokenFilter sur ce champ. Une requête de type match_lattice demande un champ lattice configuré avec un filtre à jeton lattice .
Effectue une SpannearQuery enveloppée dans un latdrepayloadscorequery (extension de PayloadScoreQuery), qui utilise les scores codés dans chaque charge utile de jeton pour marquer des portées correspondantes. Le score de chaque portée est combiné pour donner le score du document (voir le paramètre payload_function pour plus de détails). Si include_span_score est définie, le score ci-dessus est multiplié par le score de similitude configuré.
Les paramètres incluent:
slop de jetons ignorés autorisés dans le matchslop_seconds utilisé lorsque lattice_format=audio . Maximum secondes, le match est autorisé à s'étendre.in_order si le jeton doit apparaître dans l'ordre (devrait être true pour lattice_format=audio )include_span_score Si true le score de similitude configuré sera multiplié avec le score de charge utile (décrit ci-dessus)payload_function un de sum , max ou min (par défaut est sum )sum résume les dizaines de travées de correspondancemax sélectionne le score max de toutes les portées correspondantesmin sélectionne le score min parmi toutes les portées correspondantespayload_length_norm_factor Un flotteur définissant la quantité de longueur de la portée de correspondance devrait normaliser le score de la portée. Une valeur de l'un signifie que le score est divisé par la longueur de la portée (notez ceci dans la largeur de la portée en termes lunene). Une valeur de 0 signifie qu'il n'y a pas de normalisation de longueur. Lorsque vous utilisez une requête match_lattice avec payload_function=sum Un score de document est calculé (en principe) comme
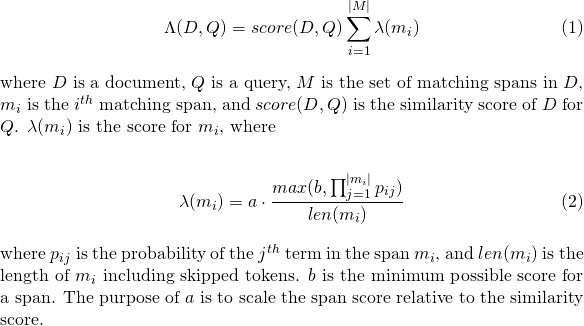
De même pour payload_function=min
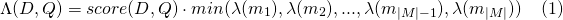
Et pour payload_function=max
Pour le développement, vous pouvez utiliser l'image Docker ci-dessous, qui prend simplement de l'image Elasticsearch officielle et installe ce plugin. Vous pouvez lire ceci pour des instructions sur la façon d'utiliser les images Elasticsearch.
docker pull messiaen/full-lattice-search:2.0.0-7.3.0
docker-compose.yaml Exemple:
version : " 2 "
services :
kibana :
image : docker.elastic.co/kibana/kibana:7.3.0
ports :
- 5601:5601
environment :
ELASTICSEARCH_HOSTS : http://es01:9200
es01 :
image : messiaen/full-lattice-search:2.0.0-7.3.0
environment :
- node.name=es01
- discovery.type=single-node
- " ES_JAVA_OPTS=-Xms1024m -Xmx1024m "
ulimits :
memlock :
soft : -1
hard : -1
volumes :
- esdata01:/usr/share/elasticsearch/data
ports :
- 9200:9200
volumes :
esdata01 :
driver : local Copiez simplement le yaml ci-dessus dans un fichier nommé docker-compose.yaml, et à partir de ce répertoire exécuté docker-compose up
En supposant que vous utilisez le docker-compose.yaml au-dessus de la navigation vers localhost:5601 dans votre navigateur et collez les exemples suivants dans la console Dev Tools de Kibana.
PUT audio_lattices
{
"settings": {
"index": {
"number_of_shards": 1,
"number_of_replicas": 0
},
"analysis": {
"analyzer": {
"lattice_analyzer": {
"type": "custom",
"tokenizer": "whitespace",
"filter": ["lattice_filter", "lowercase"]
}
},
"filter": {
"lattice_filter": {
"type": "lattice",
"lattice_format": "audio",
"audio_position_increment_seconds": 0.1
}
}
}
},
"mappings": {
"dynamic": "strict",
"properties": {
"lattices": {
"type": "lattice",
"lattice_format": "audio",
"audio_position_increment_seconds": 0.1,
"analyzer": "lattice_analyzer"
}
}
}
}
POST audio_lattices/_doc/1
{
"lattices": """the|0|0|0.9|0.15|0.25
quick|1|0|0.6|0.25|0.5 brick|1|1|0.2|0.25|0.5
fox|2|0|0.5|1.0|1.3 box|2|1|0.09|1.0|1.3
jumped|3|0|1.0|2.0|2.5"""
}
GET audio_lattices/_search
{
"query": {
"match_lattice": {
"lattices": {
"query": "quick box jumped",
"slop_seconds": 2,
"include_span_score": "true",
"payload_function": "sum",
"in_order": "true"
}
}
}
}
Voir dans Console
Réponse de recherche
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 36.987705,
"hits" : [
{
"_index" : "audio_lattices",
"_type" : "_doc",
"_id" : "1",
"_score" : 36.987705,
"_source" : {
"lattices" : """
the|0|0|0.9|0.15|0.25
quick|1|0|0.6|0.25|0.5 brick|1|1|0.2|0.25|0.5
fox|2|0|0.5|1.0|1.3 box|2|1|0.09|1.0|1.3
jumped|3|0|1.0|2.0|2.5
"""
}
}
]
}
}
PUT text_lattices
{
"settings": {
"index": {
"number_of_shards": 1,
"number_of_replicas": 0
},
"analysis": {
"analyzer": {
"lattice_analyzer": {
"type": "custom",
"tokenizer": "whitespace",
"filter": ["lattice_filter", "lowercase"]
}
},
"filter": {
"lattice_filter": {
"type": "lattice",
"lattice_format": "lattice"
}
}
}
},
"mappings": {
"dynamic": "strict",
"properties": {
"lattices": {
"type": "lattice",
"lattice_format": "lattice",
"analyzer": "lattice_analyzer"
}
}
}
}
POST text_lattices/_doc/1
{
"lattices": """the|0|0|0.9
quick|1|0|0.6 brick|1|1|0.2
fox|2|0|0.5 box|2|1|0.09
jumped|3|0|1.0"""
}
GET text_lattices/_search
{
"query": {
"match_lattice": {
"lattices": {
"query": "quick jumped",
"slop": 1,
"include_span_score": "true",
"payload_function": "sum",
"in_order": "true"
}
}
}
}
Voir dans Console
Réponse de recherche
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 9041.438,
"hits" : [
{
"_index" : "text_lattices",
"_type" : "_doc",
"_id" : "1",
"_score" : 9041.438,
"_source" : {
"lattices" : """
the|0|0|0.9
quick|1|0|0.6 brick|1|1|0.2
fox|2|0|0.5 box|2|1|0.09
jumped|3|0|1.0
"""
}
}
]
}
}
Exécutez simplement make dans le répertoire racine
Si vous souhaitez créer le plugin uniquement sans exécuter des tests, vous pouvez fonctionner
./gradlew clean assemble
Dans les deux cas, le plugin construit sera build/distributions/full-lattice-search-*.zip
make run construira le plugin et se tiendra sur Elasticsearch (avec le plugin installé) et un kibana avec docker-compose
Nécessite Elasticsearch 7.3.0 (support pour les autres versions (> = 6.0.0) à venir bientôt / sur demande)

Ce plugin n'est pas conçu pour fonctionner avec des structures de réseau généralisées, mais pour fonctionner avec une forme compressée connue sous le nom de réseau de confusion ou de chaîne de saucisse . Un réseau de confusion représente un réseau généralisé avec un ensemble fixe de positions (gammes de temps, emplacements d'image, etc.).
Chaque position a un ensemble de mots possibles, et chaque mot a une probabilité d'occurrence associée.
Par exemple, un reconnaissance vocale automatisée pourrait générer le réseau ci-dessous où l'orateur a vraiment dit
"Chaque vidéo devrait durer moins de dix minutes"

Le réseau ci-dessus peut être comprimé dans le réseau de confusion ci-dessous.

Remarquez les jetons <epsilon> (ce qui signifie l'absence d'un mot) ont été insérés pour permettre au mot «comprendre» une durée plus longue que les autres.
Il convient également de noter que le processus de compression d'un réseau dans un réseau de confusion est généralement avec perte, ce qui signifie que certains chemins à travers un réseau de confusion ne sont pas présents dans le réseau source. Par exemple, l'expression "être comprendre dix minutes" est présente dans le réseau de confusion, mais pas dans le réseau.
Remarque Vous êtes chargé de garantir que vos structures en réseau sont formatées sur des réseaux de confusion.
Voir LatticeTokenFilter Docs pour les détails d'utilisation.
Comme mentionné dans les documents LatticeTokenFilter, le paramètre score_buckets peut être utilisé pour indexer les jetons en double à la même position afin d'augmenter la fréquence à terme de ces jetons par rapport à leur score. Bien que cela ait l'affect souhaité, il y a quelques considérations.
8x de jetons ( score_buckets=[0.9, 72, 0.8, 64, 0.7, 56, 0.6, 48, 0.5, 40, 0.4, 32, 0.2, 16, 0.1, 8, 0.01, 2] ) a été bien meilleure que des configurations avec moins de duplication.8x dans 1 indexage 5x.

