full lattice search
2.0.0 for Elasticsearch 7.3.0

Этот плагин Elasticsearch позволяет искать в разных транскриптах в виде вероятностных структур решетки. Эти решетки находятся в выводе формы с помощью автоматического распознавания речи (ASR) или речи в тексте (STT), оптического распознавания символов (OCR), машинного перевода (MT), автоматического настройки изображений и т. Д., Независимо от анализа, которые можно рассматривать в виде конечного состояния (FST). (Например, в первом месте ниже возможные выходы - «и» А »). В случае STT местоположения будут диапазонами времени, в случае OCR местоположения могут быть координатами XY или, возможно, местоположением заказа на чтение. Каждый возможный выход имеет связанную вероятность возникновения в этом месте, что позволяет влиять на качество выхода решетки.
Плагин состоит из трех компонентов:
Фильтр токенов с lattice типа, который обрабатывает поток токена решетки. Токены в потоке указывают положение токена, позволяя потоку представлять структуру решетки, подобную той, которая выше. Токены в потоке также имеют оценку, которая хранится в полезной нагрузке токена при индексации, так что это можно использовать для влияния на оценку.
Фильтр токена принимает токены в одном из двух форматов. Формат установлен с параметром lattice_format , который может быть установлен на lattice или audio .
lattice_format=latticeТокены должны быть в форме
<token:string>|<position:int>|<rank:int>|<score:float>
Пример потока: the|0|0|0.9 , quick|1|0|0.6 , brick|1|1|0.2 , fox|2|0|0.5 , box|2|1|0.09 , jumped|3|0|1.0
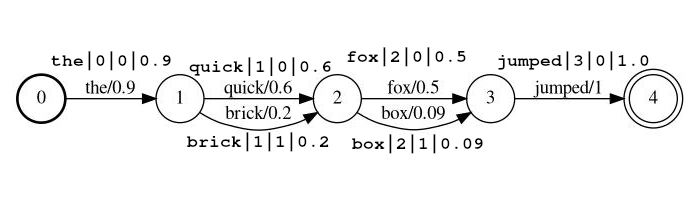
В примере приведенного выше токенов quick и brick будут индексом в одной и той же положении, потому что они оба имеют позицию, установленную в 1.
token фактический токен строкового токена, который будет искать и обрабатывать последующими фильтрамиposition является глобальной позицией токена в исходном документе (используется для определения того, должен ли токен быть местами в том же месте, что и предыдущий токен)rank звание токена по сравнению с другими возможными токенами на этой позиции (0 - наиболее вероятное звание)score поплавок от 0,0 до 1,0 (включительно). Вероятность этого токена в этой позиции. ПРИМЕЧАНИЕ Если у вас действительно есть ноль, токен не вернет, является поиском, и, вероятно, должен быть опущен из потока. lattice_format=audio Токены имеют все поля из формата lattice с добавлением start_time и stop_time .
Токены должны быть в форме
<token:string>|<position:int>|<rank:int>|<score:float>|<start_time:float>|<stop_time:float>
Пример потока: the|0|0|0.9|0.15|0.25 , quick|1|0|0.6|0.25|0.5 , brick|1|1|0.2|0.25|0.5 , fox|2|0|0.5|1.0|1.3 , box|2|1|0.09|1.0|1.3 jumped|3|0|1.0|2.0|2.5
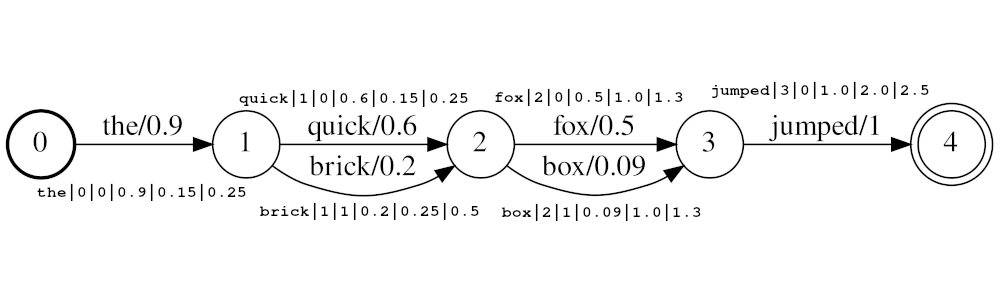
В примере приведенного выше токенов quick и brick будут индекс в одной и той же положении, потому что они оба имеют позицию, установленную в 1. Фактическое значение положения токенов определяется Times и audio_position_increment_seconds . В настоящее время фильтр выглядит только в токен
Если audio_position_increment_seconds=0.01 в приведенном выше примере приведенного выше the 15; quick и brick будет проиндексирован в положении 25; и т. д.
start_time Время начала в секундах этого токена по сравнению с началом исходного звукаstop_time Время начала в секундах этого токена относительно начала исходного звукаПараметры включают:
lattice_format (по умолчанию решетка)audio , либо latticeaudio_position_increment_secondsscore_buckets (по умолчанию не дублирование)[0.9, 10, 0.8, 8, 0.7, 7, 0.2, 1] токенов с оценкой> = 0,9 будут дублироваться в 10 раз; Токены с оценкой> = 0,8 будут дублироваться 8 раз и т. Д.audio_position_increment_seconds (по умолчанию 0,01)lattice=format=audio это точность, при которой время звука кодируется в положение в индексеfloor(token_start_time / audio_position_increment_seconds) Поле lattice типа содержит параметры LatticetOkenfilter для справки во время поиска. Функционирует точно так же, как текстовое поле.
Если вы используете lattice_format=audio вам нужно использовать тип поля lattice для MatchLatticeQueries для правильной работы со временем.
Примечание: это существует только потому, что в настоящее время не существует способа получить необходимую (или любую) информацию от анализатора в запросе. Я думаю, что может быть getChainAware() или аналогичный метод, добавленный в функционирование AnalysisProvider , аналогичное SynonymGraphTokenFilterFactory.getChainAwareTokenFilterFactory() в рамках AnalysisRegistry . (Для получения более подробной информации см. Комментарий в верхней части этого класса)
Параметры включают:
lattice_format должен соответствовать конфигурации набора LatticeTokenFilter в этом поле.audio_position_increment_seconds должен соответствовать конфигурации набора LatticeTokenFilter в этом поле. Запрос типа match_lattice Запроки запрашивает поле lattice , настроенное с помощью токенового фильтра lattice .
Выполняет Spansearquery, завернутый в LatticePayLoadScoreQuery (расширение PayLoadScoreQuery), в котором используются оценки, закодированные в каждой полезной нагрузке токена для оценки соответствующих пролетов. Оценка с каждого промежутка объединяется, чтобы дать оценку документа (подробности см. Параметр payload_function ). Если include_span_score установлен, оценка выше умножается на настроенный показатель сходства.
Параметры включают:
slop пропущенных токенов, разрешенных в матчеslop_seconds используется, когда lattice_format=audio . Максимум секунды, что матч разрешено охватывать.in_order , должен ли токен появиться в порядке (должно быть true для lattice_format=audio )include_span_score Если true настройка сходства будет умножена с оценкой полезной нагрузки (описано выше)payload_function sum max min sumsum суммирование баллов соответствующих пролетовmax выбирает оценку MAX из всех соответствующих пролетовmin выбирает минимальный счет из всех соответствующих пролетовpayload_length_norm_factor Плавание, определяющее, насколько длина сопоставления должна нормализовать оценку SPAN. Значение одного означает, что оценка делится на длину пролета (обратите внимание на это не по ширине пролета в терминах Lucene). Значение 0 означает, что нет нормализации длины. При использовании запроса match_lattice с помощью payload_function=sum оценка документа вычисляется (в принципу) как
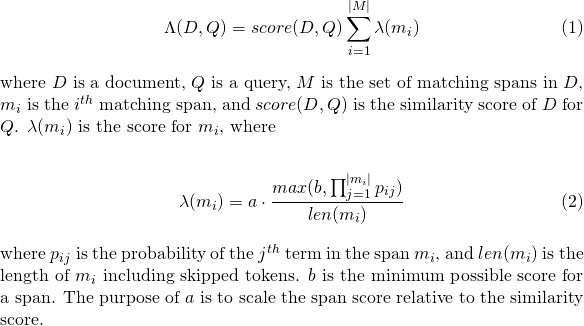
Точно так же для payload_function=min
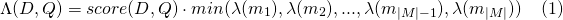
И для payload_function=max
Для разработки вы можете использовать изображение Docker ниже, которое просто берет на себя официальное изображение Elasticsearch и устанавливает этот плагин. Вы можете прочитать это для инструкций о том, как использовать изображения Elasticsearch.
docker pull messiaen/full-lattice-search:2.0.0-7.3.0
docker-compose.yaml Пример:
version : " 2 "
services :
kibana :
image : docker.elastic.co/kibana/kibana:7.3.0
ports :
- 5601:5601
environment :
ELASTICSEARCH_HOSTS : http://es01:9200
es01 :
image : messiaen/full-lattice-search:2.0.0-7.3.0
environment :
- node.name=es01
- discovery.type=single-node
- " ES_JAVA_OPTS=-Xms1024m -Xmx1024m "
ulimits :
memlock :
soft : -1
hard : -1
volumes :
- esdata01:/usr/share/elasticsearch/data
ports :
- 9200:9200
volumes :
esdata01 :
driver : local Просто скопируйте YAML выше в файл с именем docker-compose.yaml и из этого каталога запустить docker-compose up
Предполагая, что вы используете docker-compose.yaml выше, перейдите к localhost:5601 в вашем браузере и вставьте следующие примеры в консоль инструментов Dev Kibana.
PUT audio_lattices
{
"settings": {
"index": {
"number_of_shards": 1,
"number_of_replicas": 0
},
"analysis": {
"analyzer": {
"lattice_analyzer": {
"type": "custom",
"tokenizer": "whitespace",
"filter": ["lattice_filter", "lowercase"]
}
},
"filter": {
"lattice_filter": {
"type": "lattice",
"lattice_format": "audio",
"audio_position_increment_seconds": 0.1
}
}
}
},
"mappings": {
"dynamic": "strict",
"properties": {
"lattices": {
"type": "lattice",
"lattice_format": "audio",
"audio_position_increment_seconds": 0.1,
"analyzer": "lattice_analyzer"
}
}
}
}
POST audio_lattices/_doc/1
{
"lattices": """the|0|0|0.9|0.15|0.25
quick|1|0|0.6|0.25|0.5 brick|1|1|0.2|0.25|0.5
fox|2|0|0.5|1.0|1.3 box|2|1|0.09|1.0|1.3
jumped|3|0|1.0|2.0|2.5"""
}
GET audio_lattices/_search
{
"query": {
"match_lattice": {
"lattices": {
"query": "quick box jumped",
"slop_seconds": 2,
"include_span_score": "true",
"payload_function": "sum",
"in_order": "true"
}
}
}
}
Просмотр в консоли
Ответ поиска
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 36.987705,
"hits" : [
{
"_index" : "audio_lattices",
"_type" : "_doc",
"_id" : "1",
"_score" : 36.987705,
"_source" : {
"lattices" : """
the|0|0|0.9|0.15|0.25
quick|1|0|0.6|0.25|0.5 brick|1|1|0.2|0.25|0.5
fox|2|0|0.5|1.0|1.3 box|2|1|0.09|1.0|1.3
jumped|3|0|1.0|2.0|2.5
"""
}
}
]
}
}
PUT text_lattices
{
"settings": {
"index": {
"number_of_shards": 1,
"number_of_replicas": 0
},
"analysis": {
"analyzer": {
"lattice_analyzer": {
"type": "custom",
"tokenizer": "whitespace",
"filter": ["lattice_filter", "lowercase"]
}
},
"filter": {
"lattice_filter": {
"type": "lattice",
"lattice_format": "lattice"
}
}
}
},
"mappings": {
"dynamic": "strict",
"properties": {
"lattices": {
"type": "lattice",
"lattice_format": "lattice",
"analyzer": "lattice_analyzer"
}
}
}
}
POST text_lattices/_doc/1
{
"lattices": """the|0|0|0.9
quick|1|0|0.6 brick|1|1|0.2
fox|2|0|0.5 box|2|1|0.09
jumped|3|0|1.0"""
}
GET text_lattices/_search
{
"query": {
"match_lattice": {
"lattices": {
"query": "quick jumped",
"slop": 1,
"include_span_score": "true",
"payload_function": "sum",
"in_order": "true"
}
}
}
}
Просмотр в консоли
Ответ поиска
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 9041.438,
"hits" : [
{
"_index" : "text_lattices",
"_type" : "_doc",
"_id" : "1",
"_score" : 9041.438,
"_source" : {
"lattices" : """
the|0|0|0.9
quick|1|0|0.6 brick|1|1|0.2
fox|2|0|0.5 box|2|1|0.09
jumped|3|0|1.0
"""
}
}
]
}
}
Просто запустите make в корневом каталоге
Если вы хотите создать только плагин без запуска тестов, вы можете запустить
./gradlew clean assemble
В любом случае, встроенный плагин будет build/distributions/full-lattice-search-*.zip
make run создаст плагин и встанет на Elasticsearch (с установленным плагином) и кибана с докером
Требуется Elasticsearch 7.3.0 (поддержка других версий (> = 6.0.0) скоро / по запросу)

Этот плагин предназначен не для работы с обобщенными структурами решетки, а для работы с сжатой формой, известной как путаница, или строка колбасы . Сеть путаницы представляет обобщенную решетку с фиксированным набором позиций (временные диапазоны, местоположения изображений и т. Д.).
Каждая позиция имеет набор возможных слов, и каждое слово имеет связанную вероятность возникновения.
Например, автоматизированное распознавание речи может генерировать решетку ниже, где динамик действительно сказал
"Каждое видео должно быть менее десяти минут"

Решетка выше может быть сжата в сеть путаницы ниже.

Обратите внимание, что токены <epsilon> (что означает отсутствие слова) были вставлены, чтобы позволить слову «понять» иметь более длительную продолжительность, чем другие.
Стоит также отметить, что процесс сжатия решетки в сеть путаницы, как правило, является потерянным, что означает, что некоторые пути через сеть путаницы не присутствуют в исходной решетке. Например, в сети путаницы присутствуют фраза «понять десять минут» , но не в решетке.
Обратите внимание, что вы несете ответственность за обеспечение отформатирования ваших решетчатых структур.
См. Документы LatticetOkenFilter для деталей использования.
Как упомянуто в документах LatticetOkenfilter, параметр score_buckets может использоваться для индексации дубликатов токенов в той же позиции, чтобы повысить термин-частоту этих токенов относительно баллов. Хотя это имеет желаемый аффект, мало соображений.
8x линейное дублирование токенов ( score_buckets=[0.9, 72, 0.8, 64, 0.7, 56, 0.6, 48, 0.5, 40, 0.4, 32, 0.2, 16, 0.1, 8, 0.01, 2] ), выполненные намного лучше, чем конфигурация с меньшей дублированием.8x дублирования на конфигурации в 1, удаляя фонетический токен фильтр из потока анализа, в результате чего в индексации 5x.

