full lattice search
2.0.0 for Elasticsearch 7.3.0

이 Elasticsearch 플러그인을 사용하면 확률 론적 격자 구조의 형태로 전 사체를 검색 할 수 있습니다. 이러한 격자는 자동화 된 음성 인식 (ASR) 또는 STT (Speech-to-Text), 광학 문자 인식 (OCR), 기계 번역 (MT), 자동화 된 이미지 캡션 등의 양식 출력에 있습니다. 분석에 관계없이 격자는 아래의 유한 상태 머신 (FST) 구조 (다른 상태로부터의 전이)로 볼 수 있습니다. 문서 (예 : 아래 첫 번째 위치에서 가능한 출력은 'the'및 'a'입니다). STT의 경우 위치는 시간 범위가 될 것입니다. OCR의 경우 위치는 XY 좌표 일 수 있거나 읽기 순서 위치 일 수 있습니다. 가능한 각 출력은 해당 위치에서 관련된 발생 확률을 가지며, 관련성 스코어는 격자 출력의 품질에 영향을받을 수 있습니다.
플러그인은 세 가지 구성 요소로 구성됩니다.
격자 토큰 스트림을 처리하는 유형 lattice 의 토큰 필터. 스트림의 토큰은 토큰 위치를 나타내며 스트림은 위와 같은 격자 구조를 나타낼 수 있습니다. 스트림의 토큰은 또한 점수가 있으며,이 점수는 색인이 표시 될 때 토큰 페이로드에 저장되므로 점수에 영향을 줄 수 있습니다.
토큰 필터는 두 가지 형식 중 하나로 토큰을 허용합니다. lattice_format 매개 변수로 설정된 형식은 lattice 또는 audio 로 설정할 수 있습니다.
lattice_format=lattice토큰은 형식이어야합니다
<token:string>|<position:int>|<rank:int>|<score:float>
예제 스트림 : the|0|0|0.9 , quick|1|0|0.6 , brick|1|1|0.2 , fox|2|0|0.5 , box|2|1|0.09 , jumped|3|0|1.0
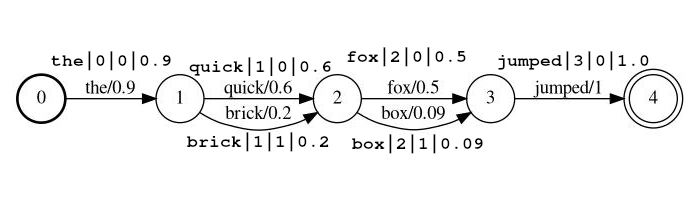
위의 예에서는 토큰 quick brick 모두 1로 설정된 위치를 갖기 때문에 동일한 위치에서 색인이됩니다.
token 검색하고 후속 필터로 처리됩니다.position 소스 문서에서 토큰의 글로벌 위치입니다 (토큰이 이전 토큰과 같은 위치에있는 장소 여부를 결정하는 데 사용됨)rank (0은 가장 가능성있는 순위입니다).score (포함). 이 위치 에서이 토큰의 확률. 참고 실제로 점수가 0 인 경우 토큰은 검색이 아니며 스트림에서 생략해야합니다. lattice_format=audio 토큰에는 start_time 및 stop_time 이 추가되어 lattice 형식의 모든 필드가 있습니다.
토큰은 형식이어야합니다
<token:string>|<position:int>|<rank:int>|<score:float>|<start_time:float>|<stop_time:float>
하천 예 : the|0|0|0.9|0.15|0.25 , quick|1|0|0.6|0.25|0.5 , brick|1|1|0.2|0.25|0.5 fox|2|0|0.5|1.0|1.3 box|2|1|0.09|1.0|1.3 jumped|3|0|1.0|2.0|2.5 , 박스 |
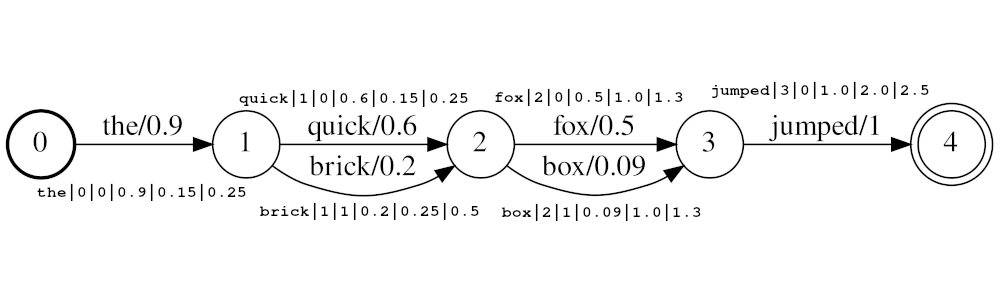
위의 예에서 토큰 quick brick 동일한 위치에서 색인이됩니다. 둘 다 1로 설정되어 있기 때문입니다. 토큰의 실제 위치 값은 Times 및 audio_position_increment_seconds 에 의해 결정됩니다. 현재 필터는 토큰 시작 시간 만 보입니다
위의 예에서 audio_position_increment_seconds=0.01 인 경우 15의 위치로 the 됩니다. quick brick 25의 위치에서 색인화됩니다. 등.
start_time 소스 오디오의 시작에 비해이 토큰의 초의 시작 시간stop_time 소스 오디오의 시작에 비해이 토큰의 초의 시작 시간매개 변수는 다음과 같습니다.
lattice_format (기본값은 격자입니다)audio 또는 lattice 정의합니다.audio_position_increment_seconds 참조하십시오score_buckets (기본값은 중복이 아닙니다)[0.9, 10, 0.8, 8, 0.7, 7, 0.2, 1] 의 값의 경우, 점수> = 0.9를 갖는 토큰이 10 배 복제됩니다. 점수> = 0.8의 토큰은 8 번 복제됩니다.audio_position_increment_seconds (기본값은 0.01)lattice=format=audio 경우 오디오 시간이 인덱스에서 위치로 인코딩되는 정밀도입니다.floor(token_start_time / audio_position_increment_seconds) 유형 lattice 필드는 검색 시간에 참조 할 수있는 LatticeTokenFilter의 매개 변수를 보유합니다. 텍스트 필드와 똑같이 기능합니다.
lattice_format=audio 사용하는 경우 MatchLatticeQueries의 lattice 필드 유형을 사용하여 시간을 올바르게 작동해야합니다.
참고 : 이것은 현재 쿼리 시간에 분석기로부터 필요한 정보를 얻을 수있는 방법이없는 것처럼 보이기 때문에 존재합니다. AnalysisRegistry 내에서 getChainAware() 또는 유사한 메소드가 SynonymGraphTokenFilterFactory.getChainAwareTokenFilterFactory() 와 유사한 AnalysisProvider 에 추가 될 수 있다고 생각합니다. (자세한 내용은이 수업 상단의 의견을 참조하십시오)
매개 변수는 다음과 같습니다.
lattice_format 필드의 LatticeTokenFilter 의 구성과 일치해야합니다.audio_position_increment_seconds 이 필드의 LatticeTokenFilter 의 구성과 일치해야합니다. match_lattice 유형의 쿼리는 lattice 토큰 필터로 구성된 lattice 필드를 쿼리합니다.
격자 미세 부하 스코어 (Payloadscorequery의 확장)로 랩핑 된 스팬 렉 슈리를 수행하며, 각 토큰 페이로드에서 인코딩 된 점수를 사용하여 일치하는 스팬을 득점합니다. 각 스팬의 점수는 문서 점수를 제공하기 위해 결합됩니다 (자세한 내용은 payload_function 매개 변수 참조). include_span_score 설정되면 위의 점수에 구성된 유사성 점수가 곱합니다.
매개 변수는 다음과 같습니다.
slop 수slop_seconds lattice_format=audio 에서 사용됩니다. 최대 초의 경기가 허용됩니다.in_order 토큰이 순서대로 나타나야하는지 여부 ( lattice_format=audio 의 경우 true 해야합니다)include_span_score true 인 경우 구성된 유사성 점수가 페이로드 점수를 곱합니다 (위에서 설명)payload_function sum , max 또는 min 중 하나 (기본값은 sum )sum 매칭 스팬의 점수를 합산합니다max 일치하는 모든 스팬에서 Max 점수를 선택합니다.min 모든 일치하는 스팬에서 최소 점수를 선택합니다.payload_length_norm_factor 플로트 매칭 스팬의 길이가 스팬 점수를 정규화 해야하는지 정의합니다. 하나의 값은 점수가 스팬의 길이로 나뉘어져 있음을 의미합니다 (루센 항의 범위의 너비가 아님). 0의 값은 길이 정규화가 없음을 의미합니다. payload_function=sum 에서 match_lattice query를 사용할 때 문서 점수는 다음과 같이 계산됩니다.
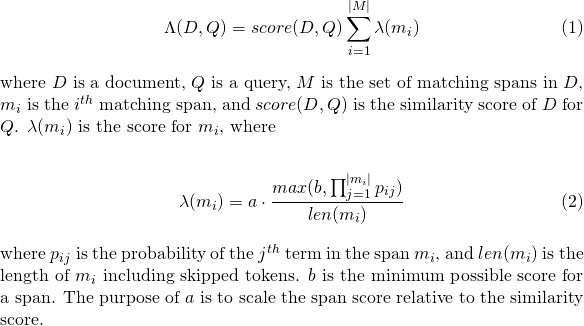
유사하게 payload_function=min
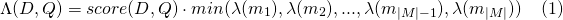
그리고 payload_function=max 의 경우
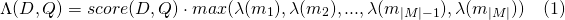
개발을 위해 공식 Elasticsearch 이미지에서 가져와이 플러그인을 설치하는 아래 Docker Image를 사용할 수 있습니다. Elasticsearch 이미지 사용 방법에 대한 지침은이 글을 읽을 수 있습니다.
docker pull messiaen/full-lattice-search:2.0.0-7.3.0
docker-compose.yaml 예 :
version : " 2 "
services :
kibana :
image : docker.elastic.co/kibana/kibana:7.3.0
ports :
- 5601:5601
environment :
ELASTICSEARCH_HOSTS : http://es01:9200
es01 :
image : messiaen/full-lattice-search:2.0.0-7.3.0
environment :
- node.name=es01
- discovery.type=single-node
- " ES_JAVA_OPTS=-Xms1024m -Xmx1024m "
ulimits :
memlock :
soft : -1
hard : -1
volumes :
- esdata01:/usr/share/elasticsearch/data
ports :
- 9200:9200
volumes :
esdata01 :
driver : local 위의 YAML을 Docker-Compose.yaml이라는 파일로 복사하고 해당 디렉토리에서 docker-compose up 실행하십시오.
위의 docker-compose.yaml 사용한다고 가정하면 브라우저에서 localhost:5601 로 이동하여 다음 예제를 Kibana의 DEV 도구 콘솔에 붙여 넣습니다.
PUT audio_lattices
{
"settings": {
"index": {
"number_of_shards": 1,
"number_of_replicas": 0
},
"analysis": {
"analyzer": {
"lattice_analyzer": {
"type": "custom",
"tokenizer": "whitespace",
"filter": ["lattice_filter", "lowercase"]
}
},
"filter": {
"lattice_filter": {
"type": "lattice",
"lattice_format": "audio",
"audio_position_increment_seconds": 0.1
}
}
}
},
"mappings": {
"dynamic": "strict",
"properties": {
"lattices": {
"type": "lattice",
"lattice_format": "audio",
"audio_position_increment_seconds": 0.1,
"analyzer": "lattice_analyzer"
}
}
}
}
POST audio_lattices/_doc/1
{
"lattices": """the|0|0|0.9|0.15|0.25
quick|1|0|0.6|0.25|0.5 brick|1|1|0.2|0.25|0.5
fox|2|0|0.5|1.0|1.3 box|2|1|0.09|1.0|1.3
jumped|3|0|1.0|2.0|2.5"""
}
GET audio_lattices/_search
{
"query": {
"match_lattice": {
"lattices": {
"query": "quick box jumped",
"slop_seconds": 2,
"include_span_score": "true",
"payload_function": "sum",
"in_order": "true"
}
}
}
}
콘솔에서 볼 수 있습니다
검색 응답
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 36.987705,
"hits" : [
{
"_index" : "audio_lattices",
"_type" : "_doc",
"_id" : "1",
"_score" : 36.987705,
"_source" : {
"lattices" : """
the|0|0|0.9|0.15|0.25
quick|1|0|0.6|0.25|0.5 brick|1|1|0.2|0.25|0.5
fox|2|0|0.5|1.0|1.3 box|2|1|0.09|1.0|1.3
jumped|3|0|1.0|2.0|2.5
"""
}
}
]
}
}
PUT text_lattices
{
"settings": {
"index": {
"number_of_shards": 1,
"number_of_replicas": 0
},
"analysis": {
"analyzer": {
"lattice_analyzer": {
"type": "custom",
"tokenizer": "whitespace",
"filter": ["lattice_filter", "lowercase"]
}
},
"filter": {
"lattice_filter": {
"type": "lattice",
"lattice_format": "lattice"
}
}
}
},
"mappings": {
"dynamic": "strict",
"properties": {
"lattices": {
"type": "lattice",
"lattice_format": "lattice",
"analyzer": "lattice_analyzer"
}
}
}
}
POST text_lattices/_doc/1
{
"lattices": """the|0|0|0.9
quick|1|0|0.6 brick|1|1|0.2
fox|2|0|0.5 box|2|1|0.09
jumped|3|0|1.0"""
}
GET text_lattices/_search
{
"query": {
"match_lattice": {
"lattices": {
"query": "quick jumped",
"slop": 1,
"include_span_score": "true",
"payload_function": "sum",
"in_order": "true"
}
}
}
}
콘솔에서 볼 수 있습니다
검색 응답
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 9041.438,
"hits" : [
{
"_index" : "text_lattices",
"_type" : "_doc",
"_id" : "1",
"_score" : 9041.438,
"_source" : {
"lattices" : """
the|0|0|0.9
quick|1|0|0.6 brick|1|1|0.2
fox|2|0|0.5 box|2|1|0.09
jumped|3|0|1.0
"""
}
}
]
}
}
루트 디렉토리에서 make 실행하십시오
테스트를 실행하지 않고 플러그인 만 빌드하려면 실행할 수 있습니다.
./gradlew clean assemble
두 경우 모두 내장 플러그인은 build/distributions/full-lattice-search-*.zip
make run 플러그인을 빌드하고 엘라스틱 검색 (플러그인이 설치된 상태)과 Docker-Compose의 Kibana를 견딜 수 있습니다.
Elasticsearch 7.3.0이 필요합니다 (다른 버전에 대한 지원 (> = 6.0.0)이 곧 제공 / 요청)

이 플러그인은 일반화 된 격자 구조와 함께 작동하도록 설계된 것이 아니라 혼란 네트워크 또는 소시지 문자열 로 알려진 압축 형식으로 작동하도록 설계되었습니다. 혼란 네트워크는 고정 된 위치 세트 (시간 범위, 이미지 위치 등)가있는 일반화 된 격자를 나타냅니다.
각 위치에는 가능한 단어 세트가 있으며 각 단어는 관련 가능성이 있습니다.
예를 들어 자동화 된 음성 인식기는 스피커가 실제로 말한 곳 아래의 격자를 생성 할 수 있습니다.
"각 비디오는 10 분 미만이어야합니다."

위의 격자는 아래의 혼란 네트워크로 압축 될 수 있습니다.

<epsilon> 토큰 (단어 부재를 의미)은 "이해 '라는 단어가 다른 것보다 더 긴 기간을 가질 수 있도록 삽입되었습니다.
또한 격자를 혼란 네트워크로 압축하는 과정은 일반적으로 손실이라는 점에 주목할 가치가 있습니다. 즉, 혼란 네트워크를 통한 일부 경로는 소스 격자에 존재하지 않습니다. 예를 들어, "이해하기 10 분"이라는 문구는 혼란 네트워크에 있지만 격자에는 없습니다.
참고 격자 구조가 혼란 네트워크로 형식화되도록합니다.
사용에 대한 자세한 내용은 LatticeTokenFilter 문서를 참조하십시오.
LatticetokenFilter DOC에서 언급 한 바와 같이, score_buckets 매개 변수는 점수에 비해 해당 토큰의 용어 주파수를 높이기 위해 동일한 위치에서 중복 토큰을 색인화하는 데 사용될 수 있습니다. 이것은 원하는 영향을 미치지 만 고려 사항은 거의 없습니다.
8x 선형 복제 ( score_buckets=[0.9, 72, 0.8, 64, 0.7, 56, 0.6, 48, 0.5, 40, 0.4, 32, 0.2, 16, 0.1, 8, 0.01, 2]8x 복제 구성을 테스트하는 동안 Stemmer 토큰 필터를 사용하는 경우, 인덱싱의 5x 속도를 제거한 음성 토큰 필터에서 음성 토큰 필터를 제거합니다.

