full lattice search
2.0.0 for Elasticsearch 7.3.0

Plugin Elasticsearch ini memungkinkan pencarian lintas transkrip dalam bentuk struktur kisi probabilistik. Kisi-kisi-kisi ini berada dalam bentuk output dengan pengenalan ucapan otomatis (ASR) atau ucapan-ke-teks (STT), pengenalan karakter optik (OCR), terjemahan mesin (MT), captioning gambar otomatis, dll. Kisi-kisi, di mana setiap rangkaian analitik, dapat dilihat sebagai satu-satunya yang diaktifkan dari satu negara (FST) di bawah ini. Dokumen (misalnya di lokasi pertama di bawah ini, output yang mungkin adalah 'The' dan 'A'). Dalam kasus STT, lokasi akan menjadi rentang waktu, dalam kasus OCR, lokasi dapat berupa koordinat XY, atau mungkin lokasi pesanan bacaan. Setiap output yang mungkin memiliki probabilitas kejadian terkait di lokasi yang memungkinkan penilaian relevansi dipengaruhi oleh kualitas output kisi.
Plugin ini terdiri dari tiga komponen:
Filter token tipe lattice yang memproses aliran token kisi. Token dalam aliran menunjukkan posisi token, memungkinkan aliran untuk mewakili struktur kisi seperti yang di atas. Token di aliran juga memiliki skor, yang disimpan dalam muatan token saat diindeks sehingga dapat digunakan untuk mempengaruhi penilaian.
Filter token menerima token dalam salah satu dari dua format. Format set dengan parameter lattice_format , yang dapat diatur ke lattice , atau audio .
lattice_format=latticeToken harus ada dalam bentuk
<token:string>|<position:int>|<rank:int>|<score:float>
Contoh Aliran: the|0|0|0.9 , quick|1|0|0.6 , brick|1|1|0.2 , fox|2|0|0.5 , box|2|1|0.09 , jumped|3|0|1.0
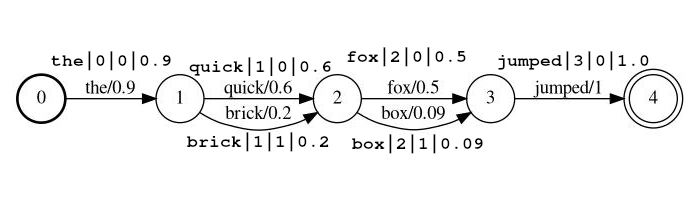
Dalam contoh di atas token quick dan brick akan menjadi indeks pada posisi yang sama, karena mereka berdua memiliki posisi diatur ke 1.
token token string aktual yang harus dicari dan diproses dengan filter lanjutanposition adalah posisi global token dalam dokumen sumber (digunakan untuk menentukan apakah token harus menjadi tempat di lokasi yang sama dengan token sebelumnya)rank peringkat token relatif terhadap token lain yang mungkin di posisi ini (0 adalah peringkat yang paling mungkin)score float antara 0,0 dan 1,0 (inklusif). Probabilitas token ini pada posisi ini. CATATAN Jika Anda benar -benar memiliki skor nol token tidak akan kembali adalah pencarian, dan mungkin harus dihilangkan dari aliran. lattice_format=audio Token memiliki semua bidang dari format lattice dengan penambahan start_time dan stop_time .
Token harus ada dalam bentuk
<token:string>|<position:int>|<rank:int>|<score:float>|<start_time:float>|<stop_time:float>
Contoh Aliran: the|0|0|0.9|0.15|0.25 , quick|1|0|0.6|0.25|0.5 , brick|1|1|0.2|0.25|0.5 , fox|2|0|0.5|1.0|1.3 , box|2|1|0.09|1.0|1.3 , jumped|3|0|1.0|2.0|2.5
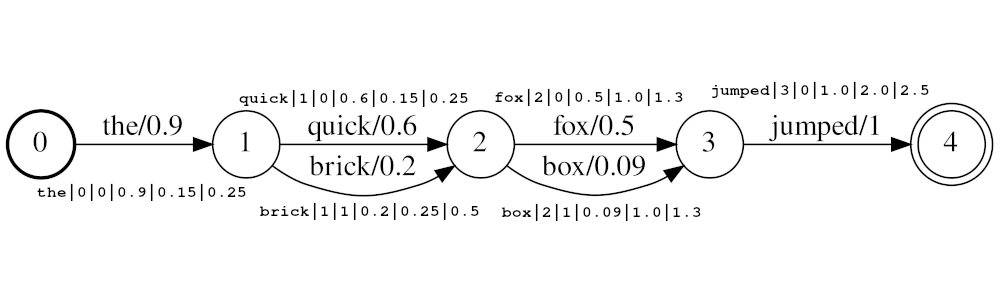
Dalam contoh di atas token quick dan brick akan menjadi indeks pada posisi yang sama, karena keduanya memiliki posisi diatur ke 1. Nilai posisi aktual token ditentukan oleh Times dan audio_position_increment_seconds . Saat ini filter hanya terlihat waktu mulai token
Jika audio_position_increment_seconds=0.01 dalam contoh di atas the diindeks dengan posisi 15; quick dan brick akan diindeks pada posisi 25; dll.
start_time waktu mulai dalam detik token ini relatif terhadap awal audio sumberstop_time waktu mulai dalam detik token ini relatif terhadap awal audio sumberParameter meliputi:
lattice_format (default kisi)audio atau latticeaudio_position_increment_secondsscore_buckets (default tidak ada duplikasi)[0.9, 10, 0.8, 8, 0.7, 7, 0.2, 1] , token dengan skor> = 0,9 akan digandakan 10 kali; Token dengan skor> = 0,8 akan digandakan 8 kali, dll.audio_position_increment_seconds (default adalah 0,01)lattice=format=audio Ini adalah ketepatan di mana waktu audio dikodekan ke posisi dalam indeksfloor(token_start_time / audio_position_increment_seconds) Bidang tipe lattice memegang parameter latticetokenFilter untuk referensi pada waktu pencarian. Fungsi persis seperti bidang teks.
Jika Anda menggunakan lattice_format=audio Anda perlu menggunakan jenis bidang lattice untuk matchlatticequeries agar bekerja dengan benar dengan waktu.
Catatan: Ini hanya ada karena saat ini tampaknya tidak ada cara untuk mendapatkan informasi yang diperlukan (atau apa pun) dari penganalisa pada waktu kueri. Saya pikir mungkin ada getChainAware() atau metode serupa yang ditambahkan ke AnalysisProvider yang berfungsi mirip dengan SynonymGraphTokenFilterFactory.getChainAwareTokenFilterFactory() dalam AnalysisRegistry . (Untuk lebih jelasnya, lihat komentar di bagian atas kelas ini)
Parameter meliputi:
lattice_format harus cocok dengan konfigurasi yang diatur LatticeTokenFilter di bidang ini.audio_position_increment_seconds harus cocok dengan konfigurasi yang diatur LatticeTokenFilter di bidang ini. Kueri tipe match_lattice menanyakan bidang lattice yang dikonfigurasi dengan filter token lattice .
Melakukan spannearquery yang dibungkus dengan latticepayloadscoreQuery (perpanjangan payloadscoreQuery), yang menggunakan skor yang dikodekan di setiap payload token untuk mencetak rentang pencocokan. Skor dari setiap rentang digabungkan untuk memberikan skor dokumen (lihat parameter payload_function untuk detailnya). Jika include_span_score diatur, skor di atas dikalikan dengan skor kesamaan yang dikonfigurasi.
Parameter meliputi:
slop token dilewati diizinkan dalam pertandinganslop_seconds digunakan saat lattice_format=audio . Detik maksimum pertandingan dibiarkan rentang.in_order apakah token harus muncul secara berurutan (harus true untuk lattice_format=audio )include_span_score jika true skor kesamaan yang dikonfigurasi akan dikalikan dengan skor payload (dijelaskan di atas)payload_function salah satu dari sum , max , atau min (default adalah sum )sum SUM SCORE Bentang Pencocokanmax memilih skor maks dari semua rentang pencocokanmin memilih skor min dari semua rentang pencocokanpayload_length_norm_factor Float yang menentukan berapa lama rentang pencocokan harus menormalkan skor rentang. Nilai satu berarti bahwa skor dibagi dengan panjang rentang (perhatikan ini bukan lebar rentang dalam istilah Lucene). Nilai 0 berarti tidak ada normalisasi panjang. Saat menggunakan kueri match_lattice dengan payload_function=sum skor dokumen dihitung (di prinsipal) sebagai
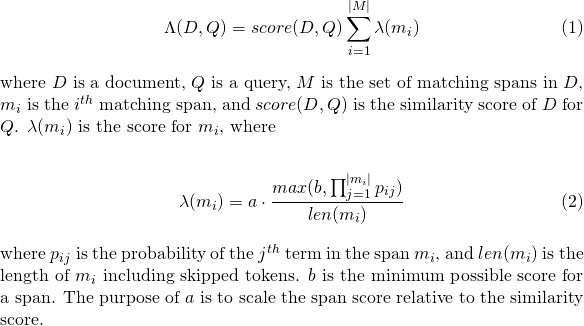
Demikian pula untuk payload_function=min
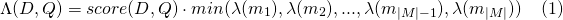
Dan untuk payload_function=max
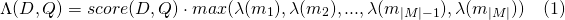
Untuk pengembangan Anda dapat menggunakan gambar Docker di bawah ini, yang hanya mengambil dari gambar Elasticsearch resmi dan menginstal plugin ini. Anda dapat membaca ini untuk instruksi tentang cara menggunakan gambar Elasticsearch.
docker pull messiaen/full-lattice-search:2.0.0-7.3.0
Contoh docker-compose.yaml :
version : " 2 "
services :
kibana :
image : docker.elastic.co/kibana/kibana:7.3.0
ports :
- 5601:5601
environment :
ELASTICSEARCH_HOSTS : http://es01:9200
es01 :
image : messiaen/full-lattice-search:2.0.0-7.3.0
environment :
- node.name=es01
- discovery.type=single-node
- " ES_JAVA_OPTS=-Xms1024m -Xmx1024m "
ulimits :
memlock :
soft : -1
hard : -1
volumes :
- esdata01:/usr/share/elasticsearch/data
ports :
- 9200:9200
volumes :
esdata01 :
driver : local Cukup salin YAML di atas ke dalam file bernama Docker-compose.yaml, dan dari direktori itu, docker-compose up
Dengan asumsi Anda menggunakan docker-compose.yaml di atas menavigasi ke localhost:5601 di browser Anda dan tempel contoh-contoh berikut ke dalam konsol alat dev Kibana.
PUT audio_lattices
{
"settings": {
"index": {
"number_of_shards": 1,
"number_of_replicas": 0
},
"analysis": {
"analyzer": {
"lattice_analyzer": {
"type": "custom",
"tokenizer": "whitespace",
"filter": ["lattice_filter", "lowercase"]
}
},
"filter": {
"lattice_filter": {
"type": "lattice",
"lattice_format": "audio",
"audio_position_increment_seconds": 0.1
}
}
}
},
"mappings": {
"dynamic": "strict",
"properties": {
"lattices": {
"type": "lattice",
"lattice_format": "audio",
"audio_position_increment_seconds": 0.1,
"analyzer": "lattice_analyzer"
}
}
}
}
POST audio_lattices/_doc/1
{
"lattices": """the|0|0|0.9|0.15|0.25
quick|1|0|0.6|0.25|0.5 brick|1|1|0.2|0.25|0.5
fox|2|0|0.5|1.0|1.3 box|2|1|0.09|1.0|1.3
jumped|3|0|1.0|2.0|2.5"""
}
GET audio_lattices/_search
{
"query": {
"match_lattice": {
"lattices": {
"query": "quick box jumped",
"slop_seconds": 2,
"include_span_score": "true",
"payload_function": "sum",
"in_order": "true"
}
}
}
}
Lihat di konsol
Tanggapan Cari
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 36.987705,
"hits" : [
{
"_index" : "audio_lattices",
"_type" : "_doc",
"_id" : "1",
"_score" : 36.987705,
"_source" : {
"lattices" : """
the|0|0|0.9|0.15|0.25
quick|1|0|0.6|0.25|0.5 brick|1|1|0.2|0.25|0.5
fox|2|0|0.5|1.0|1.3 box|2|1|0.09|1.0|1.3
jumped|3|0|1.0|2.0|2.5
"""
}
}
]
}
}
PUT text_lattices
{
"settings": {
"index": {
"number_of_shards": 1,
"number_of_replicas": 0
},
"analysis": {
"analyzer": {
"lattice_analyzer": {
"type": "custom",
"tokenizer": "whitespace",
"filter": ["lattice_filter", "lowercase"]
}
},
"filter": {
"lattice_filter": {
"type": "lattice",
"lattice_format": "lattice"
}
}
}
},
"mappings": {
"dynamic": "strict",
"properties": {
"lattices": {
"type": "lattice",
"lattice_format": "lattice",
"analyzer": "lattice_analyzer"
}
}
}
}
POST text_lattices/_doc/1
{
"lattices": """the|0|0|0.9
quick|1|0|0.6 brick|1|1|0.2
fox|2|0|0.5 box|2|1|0.09
jumped|3|0|1.0"""
}
GET text_lattices/_search
{
"query": {
"match_lattice": {
"lattices": {
"query": "quick jumped",
"slop": 1,
"include_span_score": "true",
"payload_function": "sum",
"in_order": "true"
}
}
}
}
Lihat di konsol
Tanggapan Cari
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 9041.438,
"hits" : [
{
"_index" : "text_lattices",
"_type" : "_doc",
"_id" : "1",
"_score" : 9041.438,
"_source" : {
"lattices" : """
the|0|0|0.9
quick|1|0|0.6 brick|1|1|0.2
fox|2|0|0.5 box|2|1|0.09
jumped|3|0|1.0
"""
}
}
]
}
}
Cukup jalankan make di direktori root
Jika Anda hanya ingin membangun plugin tanpa menjalankan tes, Anda dapat menjalankan
./gradlew clean assemble
Dalam kedua kasus tersebut, plugin yang dibangun akan build/distributions/full-lattice-search-*.zip
make run akan membangun plugin dan berdiri Elasticsearch (dengan plugin yang diinstal) dan kibana dengan compose Docker
Membutuhkan Elasticsearch 7.3.0 (Dukungan untuk versi lain (> = 6.0.0) Segera / sesuai permintaan)

Plugin ini tidak dirancang untuk bekerja dengan struktur kisi umum, tetapi untuk bekerja dengan bentuk terkompresi yang dikenal sebagai jaringan kebingungan, atau string sosis . Jaringan kebingungan mewakili kisi umum dengan serangkaian posisi tetap (rentang waktu, lokasi gambar, dll).
Setiap posisi memiliki satu set kata yang mungkin, dan setiap kata memiliki kemungkinan kejadian yang terkait.
Misalnya pengukur suara otomatis dapat menghasilkan kisi di bawah tempat pembicara benar -benar mengatakan
"Setiap video harus di bawah sepuluh menit"

Kisi di atas dapat dikompres ke dalam jaringan kebingungan di bawah ini.

Perhatikan token <epsilon> (yang berarti tidak adanya kata) telah dimasukkan untuk memungkinkan kata "memahami 'memiliki durasi yang lebih lama daripada yang lain.
Perlu juga dicatat bahwa proses mengompresi kisi ke dalam jaringan kebingungan umumnya lossy, yang berarti bahwa beberapa jalur melalui jaringan kebingungan tidak ada dalam kisi sumber. Misalnya, frasa "dipahami sepuluh menit" hadir dalam jaringan kebingungan, tetapi tidak di kisi.
Catatan Anda bertanggung jawab untuk memastikan struktur kisi Anda diformat jaringan kebingungan.
Lihat dokumen LatticetokenFilter untuk detail penggunaan.
Seperti yang disebutkan dalam dokumen LatticetokenFilter, parameter score_buckets dapat digunakan untuk mengindeks token duplikat pada posisi yang sama untuk meningkatkan istilah frekuensi token relatif terhadap skor yang ada. Meskipun ini memang memiliki pengaruh yang diinginkan, ada beberapa pertimbangan.
8x dari token ( score_buckets=[0.9, 72, 0.8, 64, 0.7, 56, 0.6, 48, 0.5, 40, 0.4, 32, 0.2, 16, 0.1, 8, 0.01, 2] ) berkonfigurasi lebih baik daripada lebih baik.8x dalam 1, menghapus filter token fonetik dari aliran analisis yang menghasilkan speedup 5x.

