full lattice search
2.0.0 for Elasticsearch 7.3.0

Dieses Elasticsearch -Plugin ermöglicht die Suche nach Transkripten in Form probabilistischer Gitterstrukturen. Diese Gitter werden in Form der Form automatisierter Spracherkennung (ASR) oder Sprach-zu-Text (STT), optischer Charaktererkennung (OCR), maschineller Translation (MT), automatisierter Bildunterschrift usw. bestehen (ZB am ersten Ort unten sind die möglichen Ausgänge 'und' A '). Im Fall von STT wären die Standorte Zeitbereiche, im Fall von OCR könnten die Standorte XY -Koordinaten oder möglicherweise ein Standort für Leseaufträge bestehen. Jede mögliche Ausgabe hat eine zugeordnete Wahrscheinlichkeit des Auftretens an diesem Ort, sodass die Relevanzbewertung durch die Qualität der Gitterausgabe beeinträchtigt werden kann.
Das Plugin besteht aus drei Komponenten:
Ein Token -Filter vom Typ lattice , der einen Gitter -Token -Stream verarbeitet. Token im Strom geben die Token -Position an, sodass der Strom eine Gitterstruktur wie die oben genannte darstellt. Token im Stream haben auch eine Punktzahl, die bei der Indexierung in der Token -Nutzlast gespeichert ist, um die Bewertung zu beeinflussen.
Der Tokenfilter akzeptiert Token in einem von zwei Formaten. Das Format mit dem Parameter von lattice_format , der auf lattice oder audio eingestellt werden kann.
lattice_format=latticeToken sollten in der Form sein
<token:string>|<position:int>|<rank:int>|<score:float>
Beispiel Stream: the|0|0|0.9 , quick|1|0|0.6 , brick|1|1|0.2 , fox|2|0|0.5 , box|2|1|0.09 , jumped|3|0|1.0
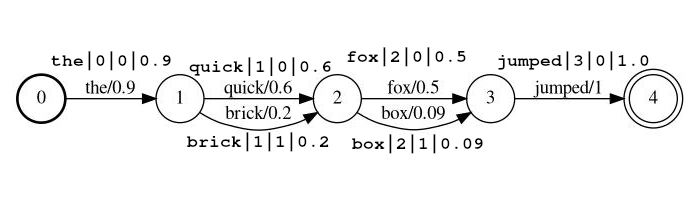
In dem Beispiel über den quick und brick sind in der gleichen Position der Index index, da beide eine Position auf 1 einstellen.
token Das tatsächliche String-Token, gegen das man durchsucht und durch Folgefilter verarbeitet werden sollposition ist die globale Position des Tokens im Quelldokument (verwendet, um festzustellen, ob sich das Token an derselben Stelle wie dem vorherigen Token befinden sollte)rank den Rang des Token relativ zu den anderen möglichen Token an dieser Position (0 ist der wahrscheinlichste Rang)score einen Schwimmer zwischen 0,0 und 1,0 (inklusive). Die Wahrscheinlichkeit eines diesem Tokens an dieser Position. Beachten Sie, wenn Sie tatsächlich eine Punktzahl von Null haben. Das Token wird nicht zurückkehren. Es ist eine Suche und sollte wahrscheinlich aus dem Stream weggelassen werden. lattice_format=audio Token haben alle Felder aus dem lattice mit Zugabe von start_time und stop_time .
Token sollten in der Form sein
<token:string>|<position:int>|<rank:int>|<score:float>|<start_time:float>|<stop_time:float>
Example stream: the|0|0|0.9|0.15|0.25 , quick|1|0|0.6|0.25|0.5 , brick|1|1|0.2|0.25|0.5 , fox|2|0|0.5|1.0|1.3 , box|2|1|0.09|1.0|1.3 , jumped|3|0|1.0|2.0|2.5
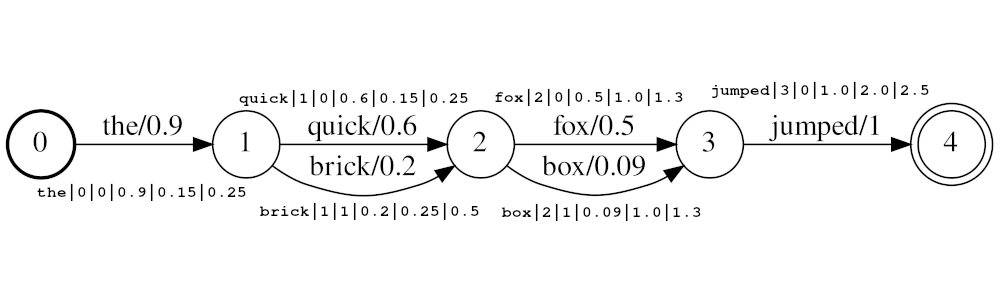
Im Beispiel über den Tokens quick und brick werden an derselben Position der Index sein, da beide die Position auf 1 haben. Der tatsächliche Positionswert der Token wird durch die Zeiten und die audio_position_increment_seconds bestimmt. Derzeit sieht der Filter nur eine Token -Startzeit aus
Wenn audio_position_increment_seconds=0.01 im obigen Beispiel mit einer Position von 15 indiziert the ; quick und brick würden an einer Position von 25 indiziert; usw.
start_time Die Startzeit in Sekunden dieses Tokens relativ zum Beginn des Quell -Audiostop_time Die Startzeit in Sekunden dieses Tokens relativ zum Beginn des Quell -AudioZu den Parametern gehören:
lattice_format (Standard ist Gitter)audio oder latticeaudio_position_increment_secondsscore_buckets (Standard ist keine Duplikation)[0.9, 10, 0.8, 8, 0.7, 7, 0.2, 1] werden Token mit einer Punktzahl> = 0,9 10 -mal dupliziert; Token mit einer Punktzahl> = 0,8 werden 8 -mal dupliziert usw.audio_position_increment_seconds (Standard ist 0,01)lattice=format=audio ist dies die Genauigkeit, zu der die Audiozeiten im Index in Position kodiert werdenfloor(token_start_time / audio_position_increment_seconds) Ein Feld vom Typ lattice enthält Parameter von LatticetokenFilter als Referenz zur Suchzeit. Funktionen genau wie ein Textfeld.
Wenn Sie lattice_format=audio verwenden, müssen Sie einen lattice verwenden, damit Matchlatticequerien korrekt mit den Zeiten arbeiten.
Hinweis: Dies ist nur vorhanden, da derzeit keine Möglichkeit zu den erforderlichen (oder) Informationen vom Analysator zur Abfragezeit zu erhalten scheint. Ich denke, es könnte eine getChainAware() oder eine ähnliche Methode geben, die zur AnalysisProvider -Funktion hinzugefügt wird, ähnlich wie SynonymGraphTokenFilterFactory.getChainAwareTokenFilterFactory() innerhalb AnalysisRegistry . (Weitere Informationen finden Sie im Kommentar oben in dieser Klasse)
Zu den Parametern gehören:
lattice_format muss mit der Konfiguration des in diesem Feld festgelegten LatticeTokenFilter -Set übereinstimmen.audio_position_increment_seconds müssen mit der Konfiguration des in diesem Feld festgelegten LatticeTokenFilter übereinstimmen. Eine Abfrage vom Typ match_lattice fragt ein lattice ab, das mit einem lattice -Token -Filter konfiguriert ist.
Führt eine SpannearQuery durch, die in ein GitterpayloadscoreQuery (Erweiterung von PayloadScoreQuery) eingewickelt ist, das die in jeder Token -Nutzlast codierten Bewertungen verwendet, um passende Übereinstimmungen zu erzielen. Die Punktzahl aus jeder Zeitspanne wird kombiniert, um die Dokumente zu erhalten (siehe Parameter payload_function für Details). Wenn include_span_score eingestellt ist, wird die obige Bewertung mit der konfigurierten Ähnlichkeitsbewertung multipliziert.
Zu den Parametern gehören:
slop -Anzahl von übersprungenen Token, die im Spiel erlaubt sindslop_seconds verwendet, wenn lattice_format=audio . Maximale Sekunden Das Match darf überspannen.in_order , ob das Token in der Reihenfolge erscheinen muss (sollte für lattice_format=audio true )include_span_score , wenn true die konfigurierte Ähnlichkeitsbewertung mit dem Nutzlastwert multipliziert wird (oben beschrieben)payload_function Einer von sum , max oder min (Standard ist sum )sum summiert die Punktzahlen der passenden Spannweitenmax wählt die maximale Punktzahl aus allen passenden Spannweiten ausmin wählt die min -Punktzahl aus allen passenden Spannweiten auspayload_length_norm_factor Ein Float, der definiert, wie viel die Länge der Übereinstimmung der Übereinstimmung der Spannweite normalisieren sollte. Ein Wert einer eins bedeutet, dass die Punktzahl durch die Länge der Spannweite geteilt wird (beachten Sie dies nicht in der Breite der Spannweite in Lucene). Ein Wert von 0 bedeutet, dass es keine Längennormalisierung gibt. Bei Verwendung einer match_lattice -Abfrage mit payload_function=sum eine Dokumentbewertung wird berechnet (in Principal) als
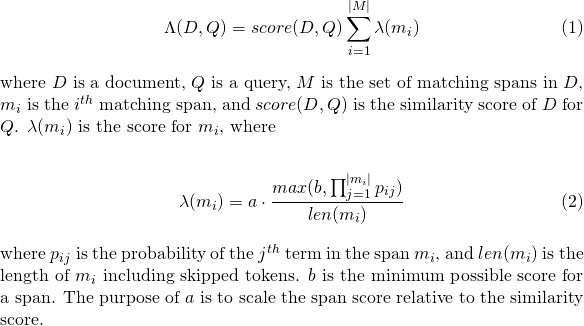
Ähnlich für payload_function=min
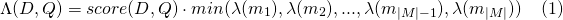
Und für payload_function=max
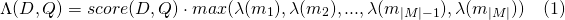
Für die Entwicklung können Sie das unten stehende Docker -Bild verwenden, das einfach vom offiziellen Elasticsearch -Bild stammt und dieses Plugin installiert. Sie können dies für Anweisungen zur Verwendung der Elasticsearch -Bilder lesen.
docker pull messiaen/full-lattice-search:2.0.0-7.3.0
docker-compose.yaml Beispiel:
version : " 2 "
services :
kibana :
image : docker.elastic.co/kibana/kibana:7.3.0
ports :
- 5601:5601
environment :
ELASTICSEARCH_HOSTS : http://es01:9200
es01 :
image : messiaen/full-lattice-search:2.0.0-7.3.0
environment :
- node.name=es01
- discovery.type=single-node
- " ES_JAVA_OPTS=-Xms1024m -Xmx1024m "
ulimits :
memlock :
soft : -1
hard : -1
volumes :
- esdata01:/usr/share/elasticsearch/data
ports :
- 9200:9200
volumes :
esdata01 :
driver : local Kopieren Sie einfach die YAML oben in eine Datei namens Docker-compose.yaml und aus diesem Verzeichnis führen Sie docker-compose up
Angenommen localhost:5601 Sie verwenden den docker-compose.yaml .
PUT audio_lattices
{
"settings": {
"index": {
"number_of_shards": 1,
"number_of_replicas": 0
},
"analysis": {
"analyzer": {
"lattice_analyzer": {
"type": "custom",
"tokenizer": "whitespace",
"filter": ["lattice_filter", "lowercase"]
}
},
"filter": {
"lattice_filter": {
"type": "lattice",
"lattice_format": "audio",
"audio_position_increment_seconds": 0.1
}
}
}
},
"mappings": {
"dynamic": "strict",
"properties": {
"lattices": {
"type": "lattice",
"lattice_format": "audio",
"audio_position_increment_seconds": 0.1,
"analyzer": "lattice_analyzer"
}
}
}
}
POST audio_lattices/_doc/1
{
"lattices": """the|0|0|0.9|0.15|0.25
quick|1|0|0.6|0.25|0.5 brick|1|1|0.2|0.25|0.5
fox|2|0|0.5|1.0|1.3 box|2|1|0.09|1.0|1.3
jumped|3|0|1.0|2.0|2.5"""
}
GET audio_lattices/_search
{
"query": {
"match_lattice": {
"lattices": {
"query": "quick box jumped",
"slop_seconds": 2,
"include_span_score": "true",
"payload_function": "sum",
"in_order": "true"
}
}
}
}
Ansicht in der Konsole
Suche Antwort
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 36.987705,
"hits" : [
{
"_index" : "audio_lattices",
"_type" : "_doc",
"_id" : "1",
"_score" : 36.987705,
"_source" : {
"lattices" : """
the|0|0|0.9|0.15|0.25
quick|1|0|0.6|0.25|0.5 brick|1|1|0.2|0.25|0.5
fox|2|0|0.5|1.0|1.3 box|2|1|0.09|1.0|1.3
jumped|3|0|1.0|2.0|2.5
"""
}
}
]
}
}
PUT text_lattices
{
"settings": {
"index": {
"number_of_shards": 1,
"number_of_replicas": 0
},
"analysis": {
"analyzer": {
"lattice_analyzer": {
"type": "custom",
"tokenizer": "whitespace",
"filter": ["lattice_filter", "lowercase"]
}
},
"filter": {
"lattice_filter": {
"type": "lattice",
"lattice_format": "lattice"
}
}
}
},
"mappings": {
"dynamic": "strict",
"properties": {
"lattices": {
"type": "lattice",
"lattice_format": "lattice",
"analyzer": "lattice_analyzer"
}
}
}
}
POST text_lattices/_doc/1
{
"lattices": """the|0|0|0.9
quick|1|0|0.6 brick|1|1|0.2
fox|2|0|0.5 box|2|1|0.09
jumped|3|0|1.0"""
}
GET text_lattices/_search
{
"query": {
"match_lattice": {
"lattices": {
"query": "quick jumped",
"slop": 1,
"include_span_score": "true",
"payload_function": "sum",
"in_order": "true"
}
}
}
}
Ansicht in der Konsole
Suche Antwort
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 9041.438,
"hits" : [
{
"_index" : "text_lattices",
"_type" : "_doc",
"_id" : "1",
"_score" : 9041.438,
"_source" : {
"lattices" : """
the|0|0|0.9
quick|1|0|0.6 brick|1|1|0.2
fox|2|0|0.5 box|2|1|0.09
jumped|3|0|1.0
"""
}
}
]
}
}
Einfach im Stammverzeichnis make
Wenn Sie das Plugin nur erstellen möchten, ohne Tests auszuführen, können Sie ausführen
./gradlew clean assemble
In beiden Fällen wird das gebaute Plugin build/distributions/full-lattice-search-*.zip
make run erstellt das Plugin und stand eine Elasticsearch (mit dem Plugin installiert) und ein Kibana mit Docker-Compose
Benötigt Elasticsearch 7.3.0 (Unterstützung für andere Versionen (> = 6.0.0), die bald / auf Anfrage kommen)

Dieses Plugin ist nicht so konzipiert, dass sie mit verallgemeinerten Gitterstrukturen funktioniert, sondern mit einer komprimierten Form, die als Verwirrungsnetzwerk oder Wurstschnur bezeichnet wird. Ein Verwirrungsnetzwerk repräsentiert ein verallgemeinertes Gitter mit einem festen Satz von Positionen (Zeitbereiche, Bildorte usw.).
Jede Position hat eine Reihe möglicher Wörter, und jedes Wort hat eine zugeordnete Wahrscheinlichkeit des Auftretens.
Zum Beispiel könnte ein automatisierter Spracherkenner das darunter liegende Gitter erzeugen, in dem der Sprecher wirklich sagte
"Jedes Video sollte unter zehn Minuten sein"

Das obige Gitter kann in das folgende Verwirrungsnetzwerk komprimiert werden.

Beachten Sie, dass die <epsilon> -Token (dh das Fehlen eines Wortes) eingefügt wurde, damit das Wort "Verständnis" eine längere Dauer hat als andere.
Es ist auch erwähnenswert, dass der Prozess der Komprimierung eines Gitters in ein Verwirrungsnetzwerk im Allgemeinen verliert ist, was bedeutet, dass einige Pfade durch ein Verwirrungsnetzwerk im Quellgitter nicht vorhanden sind. Zum Beispiel ist der Ausdruck "zehn Minuten verstehen" im Verwirrungsnetzwerk vorhanden, jedoch nicht im Gitter.
Beachten Sie, dass Sie dafür verantwortlich sind, sicherzustellen, dass Ihre Gitterstrukturen in Verwirrungsnetzwerken formatiert werden.
Siehe LatticetokenFilter -Dokumente für Verwendungsdetails.
Wie in den LatticeteTokenFilter-Dokumenten erwähnt, kann der Parameter score_buckets verwendet werden, um die doppelten Token an derselben Position zu indexieren, um die Begriffsfrequenz dieser Token in Bezug auf die dort Punktzahl zu steigern. Obwohl dies den gewünschten Einfluss hat, gibt es nur wenige Überlegungen.
8x -Duplikation von Token ( score_buckets=[0.9, 72, 0.8, 64, 0.7, 56, 0.6, 48, 0.5, 40, 0.4, 32, 0.2, 16, 0.1, 8, 0.01, 2] ).8x Duplikationskonfiguration in 1, wodurch der phonetische Token-Filter aus dem Analyse-Strom-Stromanfall zu einem 5x-Speedup führte.

