full lattice search
2.0.0 for Elasticsearch 7.3.0

يتيح هذا البرنامج المساعد Elasticsearch البحث عبر النصوص في شكل هياكل شعرية احتمالية. تكون هذه الشاشات في النموذج الناتج عن طريق التعرف على الكلام الآلي (ASR) أو الكلام إلى النص (STT) ، والتعرف على الأحرف البصرية (OCR) ، والترجمة الآلية (MT) ، وتوصيل الصور الآلي ، وما إلى ذلك. (على سبيل المثال في الموقع الأول أدناه ، المخرجات المحتملة هي "و" A "). في حالة STT ، ستكون المواقع هي نطاقات الوقت ، في حالة OCR ، يمكن أن تكون المواقع إحداثيات XY ، أو ربما موقع ترتيب القراءة. كل خرج محتمل له احتمال مرتبط بالحدوث في هذا الموقع مما يسمح بتأثر تسجيل الأهمية بجودة إخراج الشبكة.
يتكون البرنامج المساعد من ثلاثة مكونات:
مرشح رمزي من lattice التي تعالج دفق رمز شعرية. تشير الرموز في التيار إلى موضع الرمز المميز ، مما يسمح للتيار بتمثيل بنية شعرية مثل تلك أعلاه. تحتوي الرموز في الدفق أيضًا على درجة ، يتم تخزينها في الحمولة الرمزية عند فهرستها بحيث يمكن استخدامها للتأثير على التسجيل.
يقبل مرشح الرمز المميز الرموز في أحد التنسيقين. تم تعيين التنسيق باستخدام معلمة lattice_format ، والتي يمكن ضبطها على lattice ، أو audio .
lattice_format=latticeيجب أن تكون الرموز في الشكل
<token:string>|<position:int>|<rank:int>|<score:float>
مثال دفق: the|0|0|0.9 ، quick|1|0|0.6 ، brick|1|1|0.2 ، fox|2|0|0.5 ، box|2|1|0.09 ، jumped|3|0|1.0
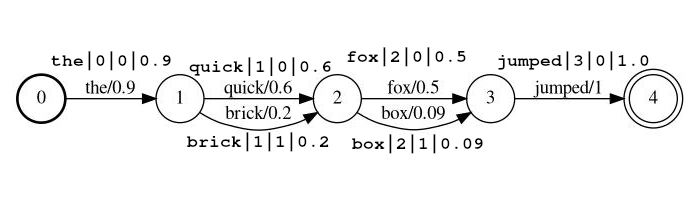
في المثال أعلاه ، سيكون الرموز quick brick فهرسة في نفس الموقف ، لأن كلاهما لديه موقع على 1.
token الرمز المميز للسلسلة الفعلية المراد البحث عنها ومعالجتها بواسطة مرشحات متابعةposition هو الموضع العالمي للرمز المميز في المستند المصدر (المستخدم لتحديد ما إذا كان الرمز المميز يجب أن يكون أماكن في نفس موقع الرمز المميز السابق)rank رتبة الرمز المميز بالنسبة للرموز الأخرى الممكنة في هذا الموقف (0 هي المرتبة الأكثر احتمالا)score تعويم بين 0.0 و 1.0 (شامل). احتمال هذا الرمز المميز في هذا الموقف. لاحظ أنه إذا كان لديك بالفعل درجة صفر ، فلن يتم إرجاع الرمز المميز هو بحث ، وربما يجب حذفه من الدفق. lattice_format=audio تحتوي الرموز على جميع الحقول من تنسيق lattice مع إضافة start_time و stop_time .
يجب أن تكون الرموز في الشكل
<token:string>|<position:int>|<rank:int>|<score:float>|<start_time:float>|<stop_time:float>
مثال على الدفق: the|0|0|0.9|0.15|0.25 ، Quick | brick|1|1|0.2|0.25|0.5 quick|1|0|0.6|0.25|0.5 box|2|1|0.09|1.0|1.3 fox|2|0|0.5|1.0|1.3 ، fox jumped|3|0|1.0|2.0|2.5
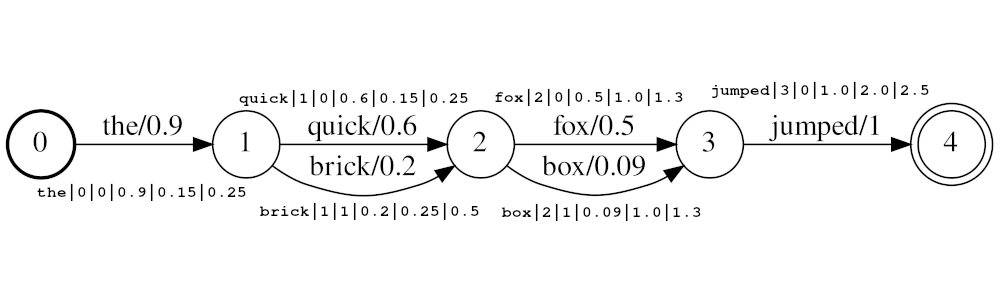
في المثال أعلاه audio_position_increment_seconds سيتم فهرس الرموز quick brick في نفس الموضع ، لأن كلاهما لديه موقع على 1. حاليًا ، يبدو المرشح أوقات بدء الرمز المميز فقط
إذا كان audio_position_increment_seconds=0.01 في المثال أعلاه the فهرسة مع موضع 15 ؛ سيتم فهرسة quick brick في موقع 25 ؛ إلخ.
start_time وقت البدء في ثوانٍ من هذا الرمز المميز بالنسبة لبداية الصوت المصدرstop_time وقت البدء في ثوانٍ من الرمز المميز هذا بالنسبة لبداية الصوت المصدرتشمل المعلمات:
lattice_format (الافتراضي هو شعرية)audio أو latticeaudio_position_increment_secondsscore_buckets (الافتراضي ليس ازدواجية)[0.9, 10, 0.8, 8, 0.7, 7, 0.2, 1] ، سيتم تكرار الرموز مع درجة> = 0.9 10 مرات ؛ سيتم تكرار الرموز ذات النتيجة> = 0.8 8 مرات ، إلخ.audio_position_increment_seconds (الافتراضي هو 0.01)lattice=format=audio فهذه هي الدقة التي يتم فيها ترميز أوقات الصوت في موضعها في الفهرسfloor(token_start_time / audio_position_increment_seconds) حقل من النوع lattice يحمل معلمات من latticeTokenFilter للرجوع إليها في وقت البحث. وظائف تمامًا مثل حقل النص.
إذا كنت تستخدم lattice_format=audio فأنت بحاجة إلى استخدام نوع حقل lattice لـ MatchLatticequeries للعمل بشكل صحيح مع الأوقات.
ملاحظة: هذا موجود فقط لأنه لا يبدو أن هناك وسيلة للحصول على المعلومات الضرورية (أو أي) من المحلل في وقت الاستعلام. أعتقد أنه يمكن أن يكون هناك getChainAware() أو طريقة مماثلة تمت إضافتها إلى AnalysisProvider التي تعمل على غرار SynonymGraphTokenFilterFactory.getChainAwareTokenFilterFactory() داخل AnalysisRegistry . (لمزيد من التفاصيل ، راجع التعليق في الجزء العلوي من هذا الفصل)
تشمل المعلمات:
lattice_format مع تكوين مجموعة LatticeTokenFilter في هذا الحقل.audio_position_increment_seconds مع تكوين مجموعة LatticeTokenFilter التي تم تعيينها على هذا الحقل. استعلام من النوع match_lattice يستفسر حقل lattice تم تكوينه باستخدام مرشح رمز lattice .
يؤدي spannearquery ملفوفة في latticepayloadscorequery (امتداد payloadscorequery) ، والذي يستخدم الدرجات المشفرة في كل حمولة رمزية لتسجيل فترات مطابقة. يتم الجمع بين النتيجة من كل فترة لإعطاء درجة المستند (انظر معلمة payload_function للحصول على التفاصيل). في حالة تعيين include_span_score ، يتم ضرب النتيجة أعلاه بواسطة درجة التشابه المكونة.
تشمل المعلمات:
slop من الرموز المميزة المسموح بها في المباراةslop_seconds المستخدمة عند lattice_format=audio . كحد أقصى الثواني المسموح بها المباراة.in_order ما إذا كان يجب أن يظهر الرمز المميز بالترتيب (يجب أن يكون true لـ lattice_format=audio )include_span_score إذا كان true فسيتم ضرب درجة التشابه التي تم تكوينها مع درجة الحمولة النافعة (الموضحة أعلاه)payload_function واحدة من sum أو max أو min (الافتراضي هو sum )sum عشرات الفترات المطابقةmax درجة الحد الأقصى من جميع الفترات المطابقةmin يختار درجة MIN من جميع الامتدادات المطابقةpayload_length_norm_factor a تعويم يحدد مقدار طول فترة المطابقة يجب أن يطبيع درجة Span. قيمة واحدة تعني أن النتيجة مقسمة على طول المدى (لاحظ هذا بعدم عرض الفترة من حيث Lucene). قيمة 0 تعني عدم وجود تطبيع طول. عند استخدام استعلام match_lattice مع payload_function=sum يتم حساب درجة المستند (في الأساس) كـ
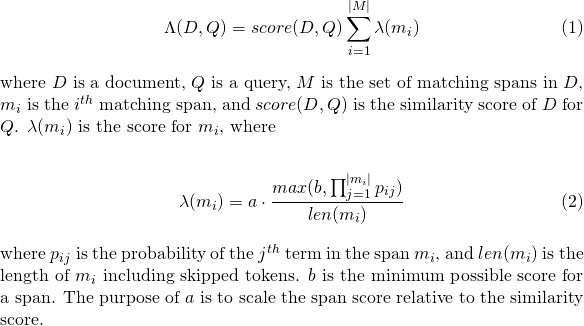
وبالمثل بالنسبة لـ payload_function=min
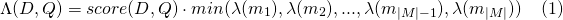
وللحمولة payload_function=max
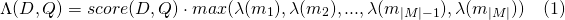
للتطوير ، يمكنك استخدام صورة Docker أدناه ، والتي تأخذ ببساطة من صورة Elasticsearch الرسمية وتثبيت هذا البرنامج المساعد. يمكنك قراءة هذا للحصول على إرشادات حول كيفية استخدام صور Elasticsearch.
docker pull messiaen/full-lattice-search:2.0.0-7.3.0
docker-compose.yaml مثال:
version : " 2 "
services :
kibana :
image : docker.elastic.co/kibana/kibana:7.3.0
ports :
- 5601:5601
environment :
ELASTICSEARCH_HOSTS : http://es01:9200
es01 :
image : messiaen/full-lattice-search:2.0.0-7.3.0
environment :
- node.name=es01
- discovery.type=single-node
- " ES_JAVA_OPTS=-Xms1024m -Xmx1024m "
ulimits :
memlock :
soft : -1
hard : -1
volumes :
- esdata01:/usr/share/elasticsearch/data
ports :
- 9200:9200
volumes :
esdata01 :
driver : local ما عليك سوى نسخ YAML أعلاه إلى ملف يسمى Docker-corm.yaml ، ومن هذا الدليل تشغيل docker-compose up
على افتراض أنك تستخدم docker-compose.yaml أعلاه ، انتقل إلى localhost:5601 في متصفحك ولصق الأمثلة التالية في وحدة التحكم في أدوات Dev Kibana.
PUT audio_lattices
{
"settings": {
"index": {
"number_of_shards": 1,
"number_of_replicas": 0
},
"analysis": {
"analyzer": {
"lattice_analyzer": {
"type": "custom",
"tokenizer": "whitespace",
"filter": ["lattice_filter", "lowercase"]
}
},
"filter": {
"lattice_filter": {
"type": "lattice",
"lattice_format": "audio",
"audio_position_increment_seconds": 0.1
}
}
}
},
"mappings": {
"dynamic": "strict",
"properties": {
"lattices": {
"type": "lattice",
"lattice_format": "audio",
"audio_position_increment_seconds": 0.1,
"analyzer": "lattice_analyzer"
}
}
}
}
POST audio_lattices/_doc/1
{
"lattices": """the|0|0|0.9|0.15|0.25
quick|1|0|0.6|0.25|0.5 brick|1|1|0.2|0.25|0.5
fox|2|0|0.5|1.0|1.3 box|2|1|0.09|1.0|1.3
jumped|3|0|1.0|2.0|2.5"""
}
GET audio_lattices/_search
{
"query": {
"match_lattice": {
"lattices": {
"query": "quick box jumped",
"slop_seconds": 2,
"include_span_score": "true",
"payload_function": "sum",
"in_order": "true"
}
}
}
}
عرض في وحدة التحكم
استجابة البحث
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 36.987705,
"hits" : [
{
"_index" : "audio_lattices",
"_type" : "_doc",
"_id" : "1",
"_score" : 36.987705,
"_source" : {
"lattices" : """
the|0|0|0.9|0.15|0.25
quick|1|0|0.6|0.25|0.5 brick|1|1|0.2|0.25|0.5
fox|2|0|0.5|1.0|1.3 box|2|1|0.09|1.0|1.3
jumped|3|0|1.0|2.0|2.5
"""
}
}
]
}
}
PUT text_lattices
{
"settings": {
"index": {
"number_of_shards": 1,
"number_of_replicas": 0
},
"analysis": {
"analyzer": {
"lattice_analyzer": {
"type": "custom",
"tokenizer": "whitespace",
"filter": ["lattice_filter", "lowercase"]
}
},
"filter": {
"lattice_filter": {
"type": "lattice",
"lattice_format": "lattice"
}
}
}
},
"mappings": {
"dynamic": "strict",
"properties": {
"lattices": {
"type": "lattice",
"lattice_format": "lattice",
"analyzer": "lattice_analyzer"
}
}
}
}
POST text_lattices/_doc/1
{
"lattices": """the|0|0|0.9
quick|1|0|0.6 brick|1|1|0.2
fox|2|0|0.5 box|2|1|0.09
jumped|3|0|1.0"""
}
GET text_lattices/_search
{
"query": {
"match_lattice": {
"lattices": {
"query": "quick jumped",
"slop": 1,
"include_span_score": "true",
"payload_function": "sum",
"in_order": "true"
}
}
}
}
عرض في وحدة التحكم
استجابة البحث
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 9041.438,
"hits" : [
{
"_index" : "text_lattices",
"_type" : "_doc",
"_id" : "1",
"_score" : 9041.438,
"_source" : {
"lattices" : """
the|0|0|0.9
quick|1|0|0.6 brick|1|1|0.2
fox|2|0|0.5 box|2|1|0.09
jumped|3|0|1.0
"""
}
}
]
}
}
ما عليك سوى تشغيل make في دليل الجذر
إذا كنت ترغب في إنشاء المكون الإضافي فقط دون إجراء اختبارات يمكنك تشغيلها
./gradlew clean assemble
في كلتا الحالتين ، سيكون المكون الإضافي المبني build/distributions/full-lattice-search-*.zip
سيقوم make run ببناء المكون الإضافي والوقوف على Elasticsearch (مع تثبيت المكون الإضافي) وكيبانا مع موكك Docker
يتطلب Elasticsearch 7.3.0 (دعم الإصدارات الأخرى (> = 6.0.0) قريبًا / عند الطلب)

هذا البرنامج المساعد غير مصمم للعمل مع هياكل شعرية معممة ، ولكن للعمل مع نموذج مضغوط يعرف باسم شبكة الارتباك ، أو سلسلة النقانق . تمثل شبكة الارتباك شعرية معممة مع مجموعة ثابتة من المواضع (نطاقات الوقت ، ومواقع الصور ، إلخ).
يحتوي كل موقف على مجموعة من الكلمات الممكنة ، وكل كلمة لها احتمال حدوثها.
على سبيل المثال ، يمكن لمزود التعرف على الكلام الآلي إنشاء شعرية أدناه حيث قال المتحدث حقًا
"يجب أن يكون كل مقطع فيديو أقل من عشر دقائق"

يمكن ضغط الشبكة أعلاه في شبكة الارتباك أدناه.

لاحظ تم إدخال الرموز المميزة <epsilon> (وهذا يعني عدم وجود كلمة) للسماح بكلمة "فهم" أن يكون لها مدة أطول من غيرها.
تجدر الإشارة أيضًا إلى أن عملية ضغط الشبكة في شبكة الارتباك أمر خاطئ بشكل عام ، مما يعني أن بعض المسارات من خلال شبكة الارتباك ليست موجودة في الشبكة المصدر. على سبيل المثال ، توجد عبارة "Be Be Fource Ten" في شبكة الارتباك ، ولكن ليس في الشبكة.
لاحظ أنك مسؤول عن ضمان تنسيق هياكل الشبكة الخاصة بك بشبكات ارتباك.
انظر docs latticeTokenFilter للحصول على تفاصيل الاستخدام.
كما هو مذكور في مستندات latticeTokenFilter ، يمكن استخدام معلمة score_buckets لفهرسة الرموز المكررة في نفس الوضع من أجل تعزيز التردد في مصطلح تلك الرموز بالنسبة إلى درجة هناك. على الرغم من أن هذا له التأثير المطلوب ، إلا أن هناك اعتبارات قليلة.
8x من الرموز ( score_buckets=[0.9, 72, 0.8, 64, 0.7, 56, 0.6, 48, 0.5, 40, 0.4, 32, 0.2, 16, 0.1, 8, 0.01, 2] ) أداء أفضل بكثير من التكوين.8x في 1 ، وإزالة مرشح الرمز المميز الصوتي من تدفق التحليل الناتج عن سرعة 5x في الفهرس.

