full lattice search
2.0.0 for Elasticsearch 7.3.0

このElasticSearchプラグインは、確率的格子構造の形でトランスクリプト全体で検索を可能にします。これらの格子は、自動化された音声認識(ASR)または音声からテキスト(STT)、光学文字認識(OCR)、機械翻訳(MT)、自動画像キャプションなどによる形式の出力です。分析に関係なく、ラティスは有限状態マシン(FST)構造と見なすことができます。 (たとえば、下の最初の場所では、可能な出力は「The」と「A」です)。 STTの場合、場所は時間の範囲です。OCRの場合、場所はXY座標、またはおそらく読み取り注文の場所である可能性があります。可能な各出力には、その場所で発生する可能性が関連する可能性があり、関連性のスコアリングが格子出力の品質の影響を受けることができます。
プラグインは、3つのコンポーネントで構成されています。
格子トークンストリームを処理する型latticeのトークンフィルター。ストリーム内のトークンはトークンの位置を示し、ストリームが上記のような格子構造を表すことができます。ストリーム内のトークンにはスコアもあります。スコアは、スコアリングに影響を与えるために使用できるように、インデックス付けされたときにトークンペイロードに保存されます。
トークンフィルターは、2つの形式のいずれかでトークンを受け入れます。 lattice_formatパラメーターで設定された形式は、 latticeまたはaudioに設定できます。
lattice_format=latticeトークンは形になるはずです
<token:string>|<position:int>|<rank:int>|<score:float>
サンプルストリーム: the|0|0|0.9 、 quick|1|0|0.6 、 brick|1|1|0.2 、 fox|2|0|0.5 、 box|2|1|0.09 、 jumped|3|0|1.0
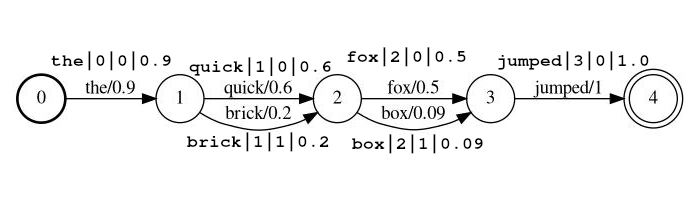
上の例では、トークンのquickとbrick同じ位置でインデックスになります。どちらも1に設定されているためです。
tokenposition 、ソースドキュメント内のトークンのグローバルな位置です(トークンが前のトークンと同じ場所にあるかどうかを判断するために使用されます)rank (0が最も可能性の高いランクです)score 。このトークンがこの位置での確率。注あなたが実際にゼロのスコアを持っている場合、トークンは検索であり、おそらくストリームから省略する必要があります。 lattice_format=audioトークンには、 start_timeとstop_timeが追加されたlattice形式のすべてのフィールドがあります。
トークンは形になるはずです
<token:string>|<position:int>|<rank:int>|<score:float>|<start_time:float>|<stop_time:float>
ストリームの例: the|0|0|0.9|0.15|0.25 、 quick|1|0|0.6|0.25|0.5 、 brick|1|1|0.2|0.25|0.5 、 fox|2|0|0.5|1.0|1.3 、 box|2|1|0.09|1.0|1.3 、 jumped|3|0|1.0|2.0|2.5
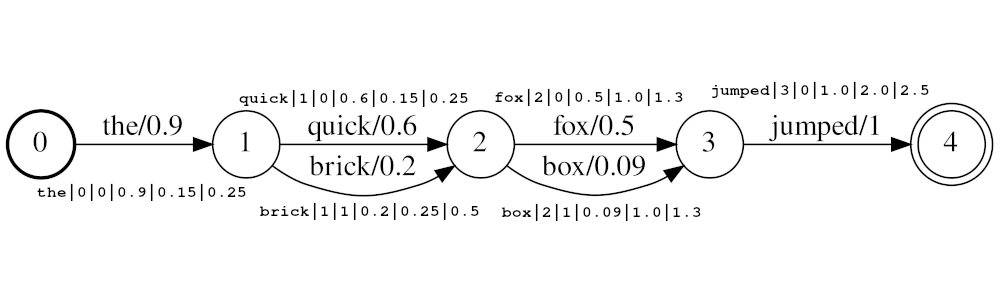
上の例では、トークンのquickとbrickは同じ位置でインデックスになります。どちらも1に設定されているためです。トークンの実際の位置値は、Timesとaudio_position_increment_secondsによって決定されます。現在、フィルターはトークンの開始時間のみに見えます
audio_position_increment_seconds=0.01上の例では、15の位置でtheが付けられます。 quickとbrick 25の位置でインデックス化されます。等
start_timeソースオーディオの開始と比較して、このトークンの秒単位の開始時間stop_timeソースオーディオの開始と比較して、このトークンの秒単位の開始時間パラメーターは次のとおりです。
lattice_format (デフォルトは格子です)audioまたはlatticeいずれかの格子トークンのフィールドを定義しますaudio_position_increment_secondsを参照してくださいscore_buckets (デフォルトは重複していません)[0.9, 10, 0.8, 8, 0.7, 7, 0.2, 1]の値の場合、スコア> = 0.9のトークンは10回複製されます。スコア> = 0.8のトークンは8回複製されます。audio_position_increment_seconds (デフォルトは0.01)lattice=format=audioこれは、オーディオタイムがインデックス内の位置にエンコードされる精度ですfloor(token_start_time / audio_position_increment_seconds)タイプlatticeのフィールドは、検索時に参照のためにLatticetokenFilterのパラメーターを保持します。テキストフィールドとまったく同じ機能。
lattice_format=audioを使用する場合は、matchlatticequeriesにlatticeフィールドタイプを使用して、時間とともに正しく動作する必要があります。
注:これは、現在、クエリ時にアナライザーから必要な(または任意の)情報を取得する方法がないように見えるためにのみ存在します。 AnalysisRegistry内のSynonymGraphTokenFilterFactory.getChainAwareTokenFilterFactory()と同様のAnalysisProvider機能に追加されたgetChainAware()または同様の方法があると思います。 (詳細については、このクラスの上部にあるコメントを参照してください)
パラメーターは次のとおりです。
lattice_format 、このフィールドに設定されたLatticeTokenFilterの構成と一致する必要があります。audio_position_increment_seconds 、このフィールドに設定されたLatticeTokenFilterの構成と一致する必要があります。タイプmatch_latticeのクエリは、 latticeトークンフィルターで構成されたlatticeフィールドをクエリします。
latticepayloadscorequery(payloadscorequeryの拡張)に包まれたスパニアクエリを実行します。これは、各トークンペイロードでエンコードされたスコアを使用してマッチングスパンをスコアスコアリングします。各スパンのスコアを組み合わせてドキュメントスコアを提供します(詳細については、 payload_functionパラメーターを参照してください)。 include_span_scoreが設定されている場合、上記のスコアに構成された類似性スコアを掛けます。
パラメーターは次のとおりです。
sloplattice_format=audioで使用されるslop_seconds 。最大秒試合のスパンが許可されます。in_orderトークンが順番に表示されなければならないかどうか( lattice_format=audioにtrueはずです)include_span_score trueの場合、構成された類似性スコアにペイロードスコアに乗算されます(上記)payload_function sum 、 max 、またはminの1つ(デフォルトはsumです)sumスパンのスコアを合計しますmax 、すべてのマッチングスパンから最大スコアを選択しますmin 、すべてのマッチングスパンから最小スコアを選択しますpayload_length_norm_factor一致スパンの長さを定義するフロートは、スパンスコアを正規化する必要があります。 1つの値は、スコアがスパンの長さで除算されることを意味します(これは、ルーセンの用語のスパンの幅ではないことに注意してください)。 0の値は、長さの正規化がないことを意味します。 payload_function=sumでmatch_latticeクエリを使用する場合、ドキュメントスコアが計算されます(主に)
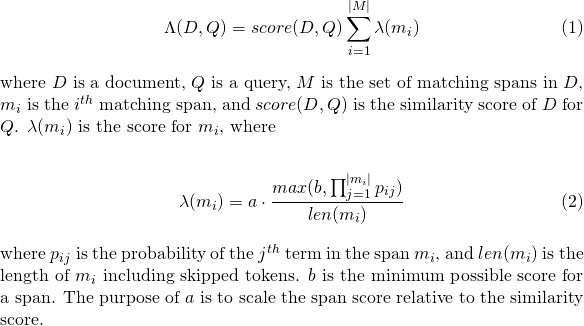
同様に、 payload_function=min
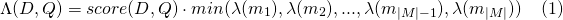
payload_function=maxの場合
開発には、以下のDocker画像を使用できます。これは、公式のElasticSearchイメージから取得し、このプラグインをインストールするだけです。これは、ElasticSearchイメージの使用方法について説明することができます。
docker pull messiaen/full-lattice-search:2.0.0-7.3.0
docker-compose.yaml例:
version : " 2 "
services :
kibana :
image : docker.elastic.co/kibana/kibana:7.3.0
ports :
- 5601:5601
environment :
ELASTICSEARCH_HOSTS : http://es01:9200
es01 :
image : messiaen/full-lattice-search:2.0.0-7.3.0
environment :
- node.name=es01
- discovery.type=single-node
- " ES_JAVA_OPTS=-Xms1024m -Xmx1024m "
ulimits :
memlock :
soft : -1
hard : -1
volumes :
- esdata01:/usr/share/elasticsearch/data
ports :
- 9200:9200
volumes :
esdata01 :
driver : local上記のYAMLをDocker-Compose.yamlという名前のファイルにコピーし、そのディレクトリからdocker-compose up実行します
上記のdocker-compose.yamlを使用していると仮定するとlocalhost:5601に移動し、次の例をKibanaのDev Toolsコンソールに貼り付けます。
PUT audio_lattices
{
"settings": {
"index": {
"number_of_shards": 1,
"number_of_replicas": 0
},
"analysis": {
"analyzer": {
"lattice_analyzer": {
"type": "custom",
"tokenizer": "whitespace",
"filter": ["lattice_filter", "lowercase"]
}
},
"filter": {
"lattice_filter": {
"type": "lattice",
"lattice_format": "audio",
"audio_position_increment_seconds": 0.1
}
}
}
},
"mappings": {
"dynamic": "strict",
"properties": {
"lattices": {
"type": "lattice",
"lattice_format": "audio",
"audio_position_increment_seconds": 0.1,
"analyzer": "lattice_analyzer"
}
}
}
}
POST audio_lattices/_doc/1
{
"lattices": """the|0|0|0.9|0.15|0.25
quick|1|0|0.6|0.25|0.5 brick|1|1|0.2|0.25|0.5
fox|2|0|0.5|1.0|1.3 box|2|1|0.09|1.0|1.3
jumped|3|0|1.0|2.0|2.5"""
}
GET audio_lattices/_search
{
"query": {
"match_lattice": {
"lattices": {
"query": "quick box jumped",
"slop_seconds": 2,
"include_span_score": "true",
"payload_function": "sum",
"in_order": "true"
}
}
}
}
コンソールでの表示
応答を検索します
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 36.987705,
"hits" : [
{
"_index" : "audio_lattices",
"_type" : "_doc",
"_id" : "1",
"_score" : 36.987705,
"_source" : {
"lattices" : """
the|0|0|0.9|0.15|0.25
quick|1|0|0.6|0.25|0.5 brick|1|1|0.2|0.25|0.5
fox|2|0|0.5|1.0|1.3 box|2|1|0.09|1.0|1.3
jumped|3|0|1.0|2.0|2.5
"""
}
}
]
}
}
PUT text_lattices
{
"settings": {
"index": {
"number_of_shards": 1,
"number_of_replicas": 0
},
"analysis": {
"analyzer": {
"lattice_analyzer": {
"type": "custom",
"tokenizer": "whitespace",
"filter": ["lattice_filter", "lowercase"]
}
},
"filter": {
"lattice_filter": {
"type": "lattice",
"lattice_format": "lattice"
}
}
}
},
"mappings": {
"dynamic": "strict",
"properties": {
"lattices": {
"type": "lattice",
"lattice_format": "lattice",
"analyzer": "lattice_analyzer"
}
}
}
}
POST text_lattices/_doc/1
{
"lattices": """the|0|0|0.9
quick|1|0|0.6 brick|1|1|0.2
fox|2|0|0.5 box|2|1|0.09
jumped|3|0|1.0"""
}
GET text_lattices/_search
{
"query": {
"match_lattice": {
"lattices": {
"query": "quick jumped",
"slop": 1,
"include_span_score": "true",
"payload_function": "sum",
"in_order": "true"
}
}
}
}
コンソールでの表示
応答を検索します
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 9041.438,
"hits" : [
{
"_index" : "text_lattices",
"_type" : "_doc",
"_id" : "1",
"_score" : 9041.438,
"_source" : {
"lattices" : """
the|0|0|0.9
quick|1|0|0.6 brick|1|1|0.2
fox|2|0|0.5 box|2|1|0.09
jumped|3|0|1.0
"""
}
}
]
}
}
ルートディレクトリでmakeを実行するだけです
テストを実行せずにプラグインのみを構築したい場合は、実行できます
./gradlew clean assemble
どちらの場合でも、構築されたプラグインはbuild/distributions/full-lattice-search-*.zipになります
make runプラグインを構築し、ElasticSearch(プラグインがインストールされた状態)とDocker-Composeのキバナを立てます
Elasticsearch 7.3.0(他のバージョンのサポート(> = 6.0.0)が近日公開予定 /リクエストに応じて必要です)

このプラグインは、一般化された格子構造で動作するように設計されていませんが、混乱ネットワークまたはソーセージストリングとして知られる圧縮フォームで動作するように設計されています。混乱ネットワークは、固定された位置(時間範囲、画像の場所など)を備えた一般的な格子を表します。
各位置には可能な単語のセットがあり、各単語には発生の可能性が関連付けられています。
たとえば、自動化された音声認識者は、スピーカーが本当に言った場所の下に格子を生成することができます
「各ビデオは10分未満でなければなりません」

上の格子は、以下の混乱ネットワークに圧縮できます。

注<epsilon>トークン(単語の不在を意味する)が挿入されており、「理解」という単語が他のものよりも長い期間を持つことができます。
また、格子を混乱ネットワークに圧縮するプロセスが一般的に損失であることも注目に値します。つまり、混乱ネットワークを通るいくつかのパスはソース格子に存在しないことを意味します。たとえば、 「10分間を理解する」というフレーズは、混乱ネットワークに存在しますが、格子には存在しません。
格子構造が混乱ネットワークにフォーマットされていることを確認する責任があることに注意してください。
使用法の詳細については、LatticetokenFilterドキュメントを参照してください。
LatticetokenFilterドキュメントで述べたように、 score_bucketsパラメーターを使用して、同じ位置で重複トークンをインデックス化するために、スコアに対するこれらのトークンのタークンの項を高めることができます。これには望ましい影響がありますが、考慮事項はほとんどありません。
8x線形複製( score_buckets=[0.9, 72, 0.8, 64, 0.7, 56, 0.6, 48, 0.5, 40, 0.4, 32, 0.2, 16, 0.1, 8, 0.01, 2]複製よりもはるかに優れていることがわかりました。8x重複構成を使用したインデックスのテスト中にステムマートークンフィルターの一部が使用される場合、分析ストリームから音声性トークンフィルターを除去すると、インデックスの5倍の速度が得られました。

