full lattice search
2.0.0 for Elasticsearch 7.3.0

ปลั๊กอิน ElasticSearch นี้ช่วยให้สามารถค้นหาการถอดเสียงในรูปแบบของโครงสร้างขัดแตะที่น่าจะเป็น lattices เหล่านี้อยู่ในรูปแบบเอาต์พุตโดยการรู้จำเสียงพูดอัตโนมัติ (ASR) หรือคำพูดเป็นข้อความ (STT), การจดจำอักขระแบบออพติคอล (OCR), การแปลด้วยเครื่อง (MT), ภาพคำบรรยายภาพอัตโนมัติ ฯลฯ lattices โดยไม่คำนึงถึงการวิเคราะห์ที่เป็นไปได้ (เช่นที่ตำแหน่งแรกด้านล่างเอาต์พุตที่เป็นไปได้คือ 'และ' A ') ในกรณีของ STT สถานที่จะมีช่วงเวลาในกรณีของ OCR สถานที่อาจเป็นพิกัด XY หรืออาจเป็นตำแหน่งการอ่าน เอาต์พุตที่เป็นไปได้แต่ละรายการมีความน่าจะเป็นที่เกี่ยวข้องกับการเกิดขึ้นที่ตำแหน่งนั้นช่วยให้การให้คะแนนความเกี่ยวข้องจะได้รับผลกระทบจากคุณภาพของเอาต์พุตตาข่าย
ปลั๊กอินประกอบด้วยสามองค์ประกอบ:
ตัวกรองโทเค็นของ Type lattice ที่ประมวลผลสตรีมโทเค็น Lattice โทเค็นในสตรีมบ่งบอกถึงตำแหน่งโทเค็นทำให้สตรีมเป็นตัวแทนของโครงสร้างตาข่ายเหมือนที่ด้านบน โทเค็นในสตรีมยังมีคะแนนซึ่งเก็บไว้ในโทเค็นเพย์โหลดเมื่อจัดทำดัชนีเพื่อให้สามารถใช้ส่งผลกระทบต่อการให้คะแนน
ตัวกรองโทเค็นยอมรับโทเค็นในหนึ่งในสองรูปแบบ รูปแบบตั้งค่าด้วยพารามิเตอร์ lattice_format ซึ่งสามารถตั้งค่าเป็น lattice หรือ audio
lattice_format=latticeโทเค็นควรอยู่ในรูปแบบ
<token:string>|<position:int>|<rank:int>|<score:float>
ตัวอย่างสตรีม: the|0|0|0.9 , quick|1|0|0.6 , brick|1|1|0.2 , fox|2|0|0.5 , box|2|1|0.09 , jumped|3|0|1.0
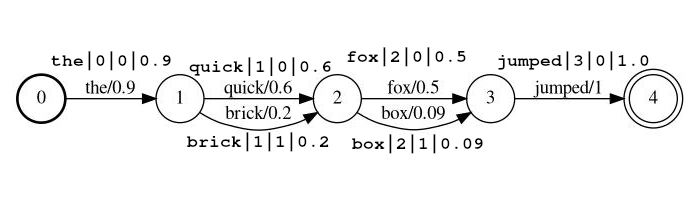
ในตัวอย่างด้านบนโทเค็น quick และ brick จะเป็นดัชนีที่ตำแหน่งเดียวกันเพราะทั้งคู่มีตำแหน่งตั้งไว้ที่ 1
token โทเค็นสตริงจริงที่จะค้นหาและประมวลผลโดยตัวกรองติดตามposition คือตำแหน่งระดับโลกของโทเค็นในเอกสารต้นฉบับ (ใช้เพื่อตรวจสอบว่าโทเค็นควรเป็นสถานที่ในตำแหน่งเดียวกันกับโทเค็นก่อนหน้า)rank อันดับของโทเค็นเมื่อเทียบกับโทเค็นอื่น ๆ ที่เป็นไปได้ที่ตำแหน่งนี้ (0 เป็นอันดับที่น่าจะเป็นไปได้มากที่สุด)score ลอยระหว่าง 0.0 ถึง 1.0 (รวม) ความน่าจะเป็นของโทเค็นนี้ที่ตำแหน่งนี้ หมายเหตุหากคุณมีคะแนนเป็นศูนย์โทเค็นจะไม่กลับมาเป็นการค้นหาและควรละเว้นจากสตรีม lattice_format=audio โทเค็นมีฟิลด์ทั้งหมดจากรูปแบบ lattice ด้วยการเพิ่ม start_time และ stop_time
โทเค็นควรอยู่ในรูปแบบ
<token:string>|<position:int>|<rank:int>|<score:float>|<start_time:float>|<stop_time:float>
ตัวอย่างสตรีม: the|0|0|0.9|0.15|0.25 , quick|1|0|0.6|0.25|0.5 , brick|1|1|0.2|0.25|0.5 , fox|2|0|0.5|1.0|1.3 box|2|1|0.09|1.0|1.3 jumped|3|0|1.0|2.0|2.5
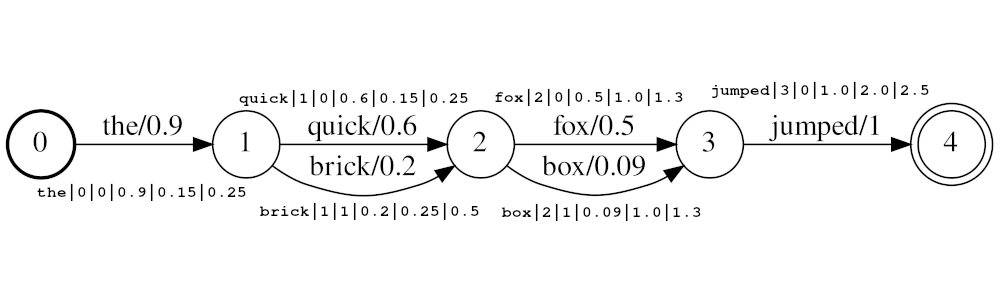
ในตัวอย่างด้านบนโทเค็น quick และ brick จะเป็นดัชนีที่ตำแหน่งเดียวกันเนื่องจากทั้งคู่มีตำแหน่งตั้งไว้ที่ 1 ค่าตำแหน่งจริงของโทเค็นจะถูกกำหนดโดย Times และ audio_position_increment_seconds ขณะนี้ตัวกรองจะดูเป็นเวลาเริ่มต้นโทเค็นเท่านั้น
ถ้า audio_position_increment_seconds=0.01 ในตัวอย่างด้านบน the ถูกจัดทำดัชนีด้วยตำแหน่ง 15; quick และ brick จะถูกจัดทำดัชนีที่ตำแหน่ง 25; เป็นต้น
start_time เวลาเริ่มต้นในไม่กี่วินาทีของโทเค็นนี้เมื่อเทียบกับจุดเริ่มต้นของเสียงต้นฉบับstop_time เวลาเริ่มต้นในไม่กี่วินาทีของโทเค็นนี้เมื่อเทียบกับจุดเริ่มต้นของเสียงต้นฉบับพารามิเตอร์รวมถึง:
lattice_format (ค่าเริ่มต้นคือ Lattice)audio หรือ latticeaudio_position_increment_secondsscore_buckets (ค่าเริ่มต้นไม่มีการทำซ้ำ)[0.9, 10, 0.8, 8, 0.7, 7, 0.2, 1] , โทเค็นที่มีคะแนน> = 0.9 จะทำซ้ำ 10 ครั้ง; โทเค็นที่มีคะแนน> = 0.8 จะทำซ้ำ 8 ครั้ง ฯลฯaudio_position_increment_seconds (ค่าเริ่มต้นคือ 0.01)lattice=format=audio นี่คือความแม่นยำที่เวลาเสียงถูกเข้ารหัสเข้าสู่ตำแหน่งในดัชนีfloor(token_start_time / audio_position_increment_seconds) ฟิลด์ประเภท lattice มีพารามิเตอร์ของ LatticetokenFilter สำหรับการอ้างอิง ณ เวลาค้นหา ฟังก์ชั่นเหมือนฟิลด์ข้อความ
หากคุณใช้ lattice_format=audio คุณต้องใช้ประเภทฟิลด์ lattice สำหรับ matchlatticequeries ทำงานอย่างถูกต้องกับเวลา
หมายเหตุ: สิ่งนี้มีอยู่เพียงเพราะปัจจุบันดูเหมือนจะไม่มีวิธีที่จะได้รับข้อมูลที่จำเป็น (หรือใด ๆ ) จากเครื่องวิเคราะห์ในเวลาสอบถาม ฉันคิดว่าอาจมี getChainAware() หรือวิธีการที่คล้ายกันที่เพิ่มเข้ามาใน AnalysisProvider การทำงานคล้ายกับ SynonymGraphTokenFilterFactory.getChainAwareTokenFilterFactory() ภายใน AnalysisRegistry (สำหรับรายละเอียดเพิ่มเติมดูความคิดเห็นที่ด้านบนของชั้นเรียนนี้)
พารามิเตอร์รวมถึง:
lattice_format ต้องตรงกับการกำหนดค่าของชุด LatticeTokenFilter ในฟิลด์นี้audio_position_increment_seconds จะต้องตรงกับการกำหนดค่าของชุด LatticeTokenFilter ในฟิลด์นี้ แบบสอบถามประเภท match_lattice แบบสอบถามฟิลด์ lattice ที่กำหนดค่าด้วยตัวกรองโทเค็น lattice
ดำเนินการ SpannearQuery ที่ห่อด้วย latticePayloadScoreQuery (ส่วนขยายของ PayloadScoreQuery) ซึ่งใช้คะแนนที่เข้ารหัสในแต่ละน้ำหนักโทเค็นเพื่อให้คะแนนช่วงการจับคู่ คะแนนจากแต่ละช่วงจะถูกรวมเข้าด้วยกันเพื่อให้คะแนนเอกสาร (ดูพารามิเตอร์ payload_function สำหรับรายละเอียด) หากมีการตั้งค่า include_span_score คะแนนด้านบนจะคูณด้วยคะแนนความคล้ายคลึงกันที่กำหนดค่า
พารามิเตอร์รวมถึง:
slop ที่อนุญาตในการจับคู่slop_seconds ใช้เมื่อ lattice_format=audio วินาทีสูงสุดการแข่งขันจะได้รับอนุญาตให้ขยายin_order order ว่าโทเค็นจะต้องปรากฏตามลำดับ (ควรเป็น true สำหรับ lattice_format=audio )include_span_score ถ้า true คะแนนความคล้ายคลึงกันที่กำหนดค่าจะคูณด้วยคะแนนน้ำหนักบรรทุก (อธิบายไว้ข้างต้น)payload_function หนึ่งใน sum max หรือ min (ค่าเริ่มต้นคือ sum )sum ผลรวมคะแนนของช่วงการจับคู่max เลือกคะแนนสูงสุดจากช่วงการจับคู่ทั้งหมดmin เลือกคะแนนขั้นต่ำจากช่วงการจับคู่ทั้งหมดpayload_length_norm_factor การลอยตัวกำหนดความยาวของช่วงการจับคู่ควรทำให้คะแนน Span เป็นปกติ ค่าหนึ่งหมายความว่าคะแนนจะถูกหารด้วยความยาวของช่วง (หมายเหตุสิ่งนี้ในความกว้างของช่วงในแง่ของลูซีน) ค่า 0 หมายความว่าไม่มีการทำให้เป็นมาตรฐานความยาว เมื่อใช้แบบสอบถาม match_lattice กับ payload_function=sum จะมีการคำนวณคะแนนเอกสาร (เป็นเงินต้น) เป็น
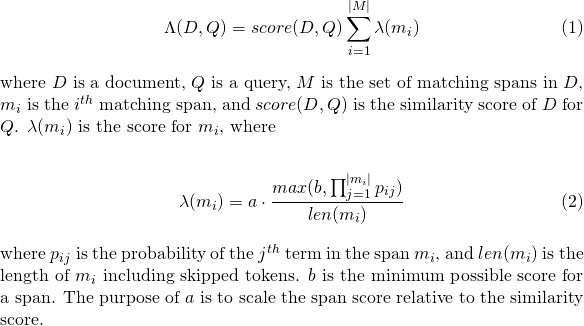
ในทำนองเดียวกันสำหรับ payload_function=min
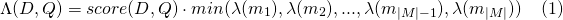
และสำหรับ payload_function=max
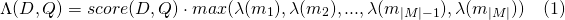
สำหรับการพัฒนาคุณสามารถใช้อิมเมจ Docker ด้านล่างซึ่งใช้เวลาจาก Image Elasticsearch อย่างเป็นทางการและติดตั้งปลั๊กอินนี้ คุณสามารถอ่านสิ่งนี้สำหรับคำแนะนำเกี่ยวกับวิธีการใช้ภาพ Elasticsearch
docker pull messiaen/full-lattice-search:2.0.0-7.3.0
docker-compose.yaml ตัวอย่าง:
version : " 2 "
services :
kibana :
image : docker.elastic.co/kibana/kibana:7.3.0
ports :
- 5601:5601
environment :
ELASTICSEARCH_HOSTS : http://es01:9200
es01 :
image : messiaen/full-lattice-search:2.0.0-7.3.0
environment :
- node.name=es01
- discovery.type=single-node
- " ES_JAVA_OPTS=-Xms1024m -Xmx1024m "
ulimits :
memlock :
soft : -1
hard : -1
volumes :
- esdata01:/usr/share/elasticsearch/data
ports :
- 9200:9200
volumes :
esdata01 :
driver : local เพียงคัดลอก Yaml ด้านบนลงในไฟล์ชื่อ Docker-compose.yaml และจากไดเรกทอรีนั้นเรียกใช้ docker-compose up
สมมติว่าคุณกำลังใช้ docker-compose.yaml ด้านบนนำทางไปยัง localhost:5601 ในเบราว์เซอร์ของคุณและวางตัวอย่างต่อไปนี้ลงในคอนโซลเครื่องมือ Dev ของ Kibana
PUT audio_lattices
{
"settings": {
"index": {
"number_of_shards": 1,
"number_of_replicas": 0
},
"analysis": {
"analyzer": {
"lattice_analyzer": {
"type": "custom",
"tokenizer": "whitespace",
"filter": ["lattice_filter", "lowercase"]
}
},
"filter": {
"lattice_filter": {
"type": "lattice",
"lattice_format": "audio",
"audio_position_increment_seconds": 0.1
}
}
}
},
"mappings": {
"dynamic": "strict",
"properties": {
"lattices": {
"type": "lattice",
"lattice_format": "audio",
"audio_position_increment_seconds": 0.1,
"analyzer": "lattice_analyzer"
}
}
}
}
POST audio_lattices/_doc/1
{
"lattices": """the|0|0|0.9|0.15|0.25
quick|1|0|0.6|0.25|0.5 brick|1|1|0.2|0.25|0.5
fox|2|0|0.5|1.0|1.3 box|2|1|0.09|1.0|1.3
jumped|3|0|1.0|2.0|2.5"""
}
GET audio_lattices/_search
{
"query": {
"match_lattice": {
"lattices": {
"query": "quick box jumped",
"slop_seconds": 2,
"include_span_score": "true",
"payload_function": "sum",
"in_order": "true"
}
}
}
}
ดูในคอนโซล
การตอบสนองการค้นหา
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 36.987705,
"hits" : [
{
"_index" : "audio_lattices",
"_type" : "_doc",
"_id" : "1",
"_score" : 36.987705,
"_source" : {
"lattices" : """
the|0|0|0.9|0.15|0.25
quick|1|0|0.6|0.25|0.5 brick|1|1|0.2|0.25|0.5
fox|2|0|0.5|1.0|1.3 box|2|1|0.09|1.0|1.3
jumped|3|0|1.0|2.0|2.5
"""
}
}
]
}
}
PUT text_lattices
{
"settings": {
"index": {
"number_of_shards": 1,
"number_of_replicas": 0
},
"analysis": {
"analyzer": {
"lattice_analyzer": {
"type": "custom",
"tokenizer": "whitespace",
"filter": ["lattice_filter", "lowercase"]
}
},
"filter": {
"lattice_filter": {
"type": "lattice",
"lattice_format": "lattice"
}
}
}
},
"mappings": {
"dynamic": "strict",
"properties": {
"lattices": {
"type": "lattice",
"lattice_format": "lattice",
"analyzer": "lattice_analyzer"
}
}
}
}
POST text_lattices/_doc/1
{
"lattices": """the|0|0|0.9
quick|1|0|0.6 brick|1|1|0.2
fox|2|0|0.5 box|2|1|0.09
jumped|3|0|1.0"""
}
GET text_lattices/_search
{
"query": {
"match_lattice": {
"lattices": {
"query": "quick jumped",
"slop": 1,
"include_span_score": "true",
"payload_function": "sum",
"in_order": "true"
}
}
}
}
ดูในคอนโซล
การตอบสนองการค้นหา
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 9041.438,
"hits" : [
{
"_index" : "text_lattices",
"_type" : "_doc",
"_id" : "1",
"_score" : 9041.438,
"_source" : {
"lattices" : """
the|0|0|0.9
quick|1|0|0.6 brick|1|1|0.2
fox|2|0|0.5 box|2|1|0.09
jumped|3|0|1.0
"""
}
}
]
}
}
เพียงเรียก make ในไดเรกทอรีราก
หากคุณต้องการสร้างปลั๊กอินโดยไม่ต้องทดสอบคุณสามารถรันได้
./gradlew clean assemble
ไม่ว่าในกรณีใดปลั๊กอินที่สร้างขึ้นจะเป็น build/distributions/full-lattice-search-*.zip
make run จะสร้างปลั๊กอินและยืนขึ้น ElasticSearch (ติดตั้งปลั๊กอิน) และ Kibana ที่มีนักเทียบท่า
ต้องใช้ ElasticSearch 7.3.0 (สนับสนุนเวอร์ชันอื่น (> = 6.0.0) เร็ว ๆ นี้ / ตามคำขอ)

ปลั๊กอินนี้ไม่ได้ออกแบบมาเพื่อทำงานกับโครงสร้างตาข่ายทั่วไป แต่ทำงานกับรูปแบบบีบอัดที่รู้จักกันในชื่อเครือข่ายความสับสนหรือ สตริงไส้กรอก เครือข่ายความสับสนแสดงถึงโครงตาข่ายทั่วไปที่มีชุดตำแหน่งคงที่ (ช่วงเวลาตำแหน่งของภาพ ฯลฯ )
แต่ละตำแหน่งมีชุดของคำที่เป็นไปได้และแต่ละคำมีโอกาสเกิดขึ้นที่เกี่ยวข้อง
ตัวอย่างเช่นการจำแนกคำพูดอัตโนมัติสามารถสร้างตาข่ายด้านล่างซึ่งผู้พูดพูดจริงๆ
"วิดีโอแต่ละรายการควรไม่ถึงสิบนาที"

ตาข่ายด้านบนสามารถบีบอัดลงในเครือข่ายความสับสนด้านล่าง

หมายเหตุโทเค็น <epsilon> (หมายถึงการขาดคำ) ได้รับการแทรกเพื่อให้คำว่า "เข้าใจ 'มีระยะเวลานานกว่าคนอื่น
นอกจากนี้ยังเป็นที่น่าสังเกตว่ากระบวนการบีบอัดตาข่ายลงในเครือข่ายความสับสนโดยทั่วไปจะสูญเสียไปซึ่งหมายความว่าเส้นทางบางเส้นทางผ่านเครือข่ายความสับสนไม่ได้อยู่ในเครือข่ายแหล่งกำเนิด ตัวอย่างเช่นวลี "เข้าใจสิบนาที" มีอยู่ในเครือข่ายความสับสน แต่ไม่ได้อยู่ในตาข่าย
หมายเหตุคุณมีความรับผิดชอบในการสร้างความมั่นใจว่าโครงสร้างขัดแตะของคุณจะถูกจัดรูปแบบเครือข่ายความสับสน
ดูเอกสาร LatticetokenFilter สำหรับรายละเอียดการใช้งาน
ดังที่ได้กล่าวไว้ในเอกสาร LatticetokenFilter พารามิเตอร์ score_buckets อาจใช้ในการจัดทำดัชนีโทเค็นซ้ำที่ตำแหน่งเดียวกันเพื่อเพิ่มความถี่คำศัพท์ของโทเค็นเหล่านั้นเมื่อเทียบกับคะแนน แม้ว่าสิ่งนี้จะมีผลกระทบที่ต้องการ แต่ก็มีการพิจารณาเล็กน้อย
8x ของโทเค็น ( score_buckets=[0.9, 72, 0.8, 64, 0.7, 56, 0.6, 48, 0.5, 40, 0.4, 32, 0.2, 16, 0.1, 8, 0.01, 2]8x ใน 1

