full lattice search
2.0.0 for Elasticsearch 7.3.0

Este plug -in ElasticSearch permite a pesquisa entre as transcrições na forma de estruturas probabilísticas de treliça. These lattices are in the form output by Automated Speech Recognition (ASR) or Speech-to-text (STT), Optical Character recognition (OCR), Machine Translation (MT), Automated Image Captioning, etc. The lattices, regardless of the analytic, can be viewed as the Finite State Machine (FST) structure below, where each set of arcs (transitioning from one state to another) represents a set of possible outputs at some location in the source Documento (por exemplo, no primeiro local abaixo, as saídas possíveis são 'The' e 'A'). No caso do STT, os locais seriam intervalos de tempo, no caso do OCR, os locais poderiam ser coordenadas XY, ou talvez um local de ordem de leitura. Cada saída possível tem uma probabilidade associada de ocorrência naquele local, permitindo que a pontuação de relevância seja afetada pela qualidade da saída da rede.
O plug -in consiste em três componentes:
Um filtro simbólico da lattice de tipo que processa um fluxo de token da rede. Os tokens no fluxo indicam a posição do token, permitindo que o fluxo represente uma estrutura de treliça como a acima. Os tokens no fluxo também têm uma pontuação, que é armazenada na carga útil do token quando indexada, de modo que isso pode ser usado para afetar a pontuação.
O filtro token aceita tokens em um dos dois formatos. O formato definido com o parâmetro lattice_format , que pode ser definido como lattice ou audio .
lattice_format=latticeTokens devem estar na forma
<token:string>|<position:int>|<rank:int>|<score:float>
Exemplo de fluxo: the|0|0|0.9 , quick|1|0|0.6 , brick|1|1|0.2 , fox|2|0|0.5 , box|2|1|0.09 , jumped|3|0|1.0
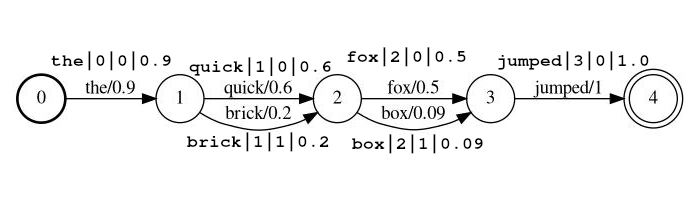
No exemplo acima, os tokens quick e brick serão índices na mesma posição, porque ambos têm posição definida como 1.
token O token de string real para ser pesquisado e processado por filtros subsequentesposition é a posição global do token no documento de origem (usado para determinar se o token deve ser lugar no mesmo local do token anterior)rank a classificação do token em relação aos outros tokens possíveis nesta posição (0 é a classificação mais provável)score um flutuador entre 0,0 e 1,0 (inclusive). A probabilidade de um token nesta posição. Nota Se você realmente tiver uma pontuação de zero, o token não retornará é uma pesquisa e provavelmente deve ser omitido do fluxo. lattice_format=audio Os tokens têm todos os campos do formato lattice com a adição de start_time e stop_time .
Tokens devem estar na forma
<token:string>|<position:int>|<rank:int>|<score:float>|<start_time:float>|<stop_time:float>
Exemplo de fluxo: the|0|0|0.9|0.15|0.25 , quick|1|0|0.6|0.25|0.5 , brick|1|1|0.2|0.25|0.5 , fox|2|0|0.5|1.0|1.3 , box|2|1|0.09|1.0|1.3 jumped|3|0|1.0|2.0|2.5
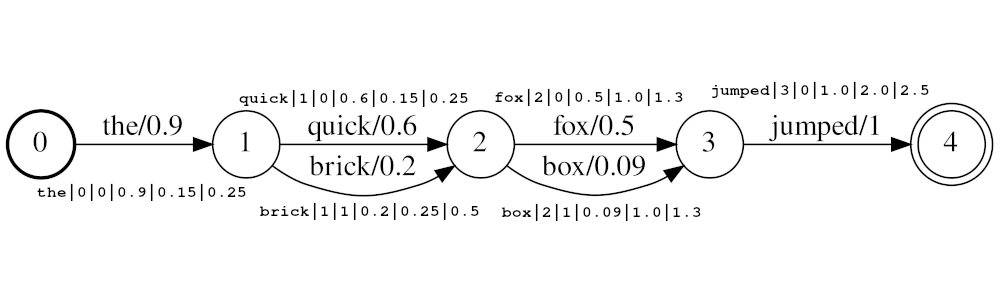
No exemplo acima, os tokens quick e brick serão índices na mesma posição, porque ambos têm posição definida como 1. O valor real da posição dos tokens é determinado pelo Times e audio_position_increment_seconds . Atualmente, o filtro parece apenas um horário de início do token
Se audio_position_increment_seconds=0.01 no exemplo acima the Indexado com uma posição de 15; quick e brick seriam indexados em uma posição de 25; etc.
start_time na hora de início em segundos deste token em relação ao início do áudio de origemstop_time na hora de início em segundos deste token em relação ao início do áudio de origemOs parâmetros incluem:
lattice_format (o padrão é treliça)audio ou latticeaudio_position_increment_secondsscore_buckets (o padrão não é duplicação)[0.9, 10, 0.8, 8, 0.7, 7, 0.2, 1] , os tokens com uma pontuação> = 0,9 serão duplicados 10 vezes; Os tokens com uma pontuação> = 0,8 serão duplicados 8 vezes, etc.audio_position_increment_seconds (o padrão é 0,01)lattice=format=audio este é a precisão na qual os horários de áudio são codificados em posição no índicefloor(token_start_time / audio_position_increment_seconds) Um campo da lattice de tipo mantém os parâmetros do LattiquetekenFilter para referência no horário da pesquisa. Funciona exatamente como um campo de texto.
Se você usar lattice_format=audio precisará usar um tipo de campo lattice para que o MatchlatticeQueries funcione corretamente com os horários.
Nota: Isso só existe porque atualmente não parece haver uma maneira de obter as informações necessárias (ou qualquer) do analisador no horário da consulta. Eu acho que poderia haver um método getChainAware() ou similar adicionado ao funcionamento AnalysisProvider semelhante a SynonymGraphTokenFilterFactory.getChainAwareTokenFilterFactory() dentro AnalysisRegistry . (Para mais detalhes, consulte o comentário no topo desta aula)
Os parâmetros incluem:
lattice_format deve corresponder à configuração do LatticeTokenFilter definido neste campo.audio_position_increment_seconds deve corresponder à configuração do LatticeTokenFilter definido neste campo. Uma consulta do tipo match_lattice consulta um campo lattice configurado com um filtro de token lattice .
Executa um SpannearQuery embrulhado em um LatticePayLoadScoreQuery (Extensão do PayloadScoreQuery), que usa as pontuações codificadas em cada carga útil de token para marcar vãos correspondentes. A pontuação de cada intervalo é combinada para fornecer a pontuação do documento (consulte o parâmetro payload_function para obter detalhes). Se include_span_score estiver definido, a pontuação acima é multiplicada pela pontuação de similaridade configurada.
Os parâmetros incluem:
slop de tokens ignorados permitidos na partidaslop_seconds usados quando lattice_format=audio . Segundos máximos, a partida pode abranger.in_order se o token deve aparecer em ordem (deve ser true para lattice_format=audio )include_span_score Se true A pontuação de similaridade configurada será multiplicada com a pontuação da carga útil (descrita acima)payload_function Um de sum , max ou min (padrão é sum )sum resume as pontuações de vãos correspondentesmax seleciona a pontuação máxima de todos os vãos correspondentesmin seleciona a pontuação min de todos os vãos correspondentespayload_length_norm_factor Um flutuador definindo quanto o comprimento da extensão correspondente deve normalizar a pontuação do span. Um valor de um significa que a pontuação é dividida pelo comprimento do período (observe isso não na largura do período em termos de Lucene). Um valor de 0 significa que não há normalização de comprimento. Ao usar uma consulta match_lattice com payload_function=sum uma pontuação de documento é calculada (em principal) como
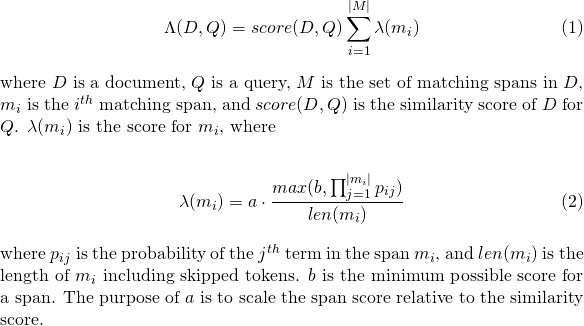
Da mesma forma, para payload_function=min
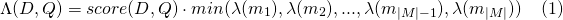
E para payload_function=max
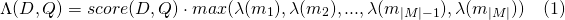
Para o desenvolvimento, você pode usar a imagem do Docker abaixo, que simplesmente retira a imagem oficial do Elasticsearch e instala este plug -in. Você pode ler isso para obter instruções sobre como usar as imagens do Elasticsearch.
docker pull messiaen/full-lattice-search:2.0.0-7.3.0
Exemplo docker-compose.yaml :
version : " 2 "
services :
kibana :
image : docker.elastic.co/kibana/kibana:7.3.0
ports :
- 5601:5601
environment :
ELASTICSEARCH_HOSTS : http://es01:9200
es01 :
image : messiaen/full-lattice-search:2.0.0-7.3.0
environment :
- node.name=es01
- discovery.type=single-node
- " ES_JAVA_OPTS=-Xms1024m -Xmx1024m "
ulimits :
memlock :
soft : -1
hard : -1
volumes :
- esdata01:/usr/share/elasticsearch/data
ports :
- 9200:9200
volumes :
esdata01 :
driver : local Basta copiar o YAML acima em um arquivo chamado Docker-compose.yaml, e a partir desse diretório executar docker-compose up
Supondo que você esteja usando o docker-compose.yaml acima Navegue até localhost:5601 no seu navegador e cole os seguintes exemplos no console de ferramentas de desenvolvimento da Kibana.
PUT audio_lattices
{
"settings": {
"index": {
"number_of_shards": 1,
"number_of_replicas": 0
},
"analysis": {
"analyzer": {
"lattice_analyzer": {
"type": "custom",
"tokenizer": "whitespace",
"filter": ["lattice_filter", "lowercase"]
}
},
"filter": {
"lattice_filter": {
"type": "lattice",
"lattice_format": "audio",
"audio_position_increment_seconds": 0.1
}
}
}
},
"mappings": {
"dynamic": "strict",
"properties": {
"lattices": {
"type": "lattice",
"lattice_format": "audio",
"audio_position_increment_seconds": 0.1,
"analyzer": "lattice_analyzer"
}
}
}
}
POST audio_lattices/_doc/1
{
"lattices": """the|0|0|0.9|0.15|0.25
quick|1|0|0.6|0.25|0.5 brick|1|1|0.2|0.25|0.5
fox|2|0|0.5|1.0|1.3 box|2|1|0.09|1.0|1.3
jumped|3|0|1.0|2.0|2.5"""
}
GET audio_lattices/_search
{
"query": {
"match_lattice": {
"lattices": {
"query": "quick box jumped",
"slop_seconds": 2,
"include_span_score": "true",
"payload_function": "sum",
"in_order": "true"
}
}
}
}
Ver no console
Resposta de pesquisa
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 36.987705,
"hits" : [
{
"_index" : "audio_lattices",
"_type" : "_doc",
"_id" : "1",
"_score" : 36.987705,
"_source" : {
"lattices" : """
the|0|0|0.9|0.15|0.25
quick|1|0|0.6|0.25|0.5 brick|1|1|0.2|0.25|0.5
fox|2|0|0.5|1.0|1.3 box|2|1|0.09|1.0|1.3
jumped|3|0|1.0|2.0|2.5
"""
}
}
]
}
}
PUT text_lattices
{
"settings": {
"index": {
"number_of_shards": 1,
"number_of_replicas": 0
},
"analysis": {
"analyzer": {
"lattice_analyzer": {
"type": "custom",
"tokenizer": "whitespace",
"filter": ["lattice_filter", "lowercase"]
}
},
"filter": {
"lattice_filter": {
"type": "lattice",
"lattice_format": "lattice"
}
}
}
},
"mappings": {
"dynamic": "strict",
"properties": {
"lattices": {
"type": "lattice",
"lattice_format": "lattice",
"analyzer": "lattice_analyzer"
}
}
}
}
POST text_lattices/_doc/1
{
"lattices": """the|0|0|0.9
quick|1|0|0.6 brick|1|1|0.2
fox|2|0|0.5 box|2|1|0.09
jumped|3|0|1.0"""
}
GET text_lattices/_search
{
"query": {
"match_lattice": {
"lattices": {
"query": "quick jumped",
"slop": 1,
"include_span_score": "true",
"payload_function": "sum",
"in_order": "true"
}
}
}
}
Ver no console
Resposta de pesquisa
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 9041.438,
"hits" : [
{
"_index" : "text_lattices",
"_type" : "_doc",
"_id" : "1",
"_score" : 9041.438,
"_source" : {
"lattices" : """
the|0|0|0.9
quick|1|0|0.6 brick|1|1|0.2
fox|2|0|0.5 box|2|1|0.09
jumped|3|0|1.0
"""
}
}
]
}
}
Simplesmente execute make in the Root Directory
Se você deseja construir apenas o plug -in sem testes que você pode executar
./gradlew clean assemble
Em ambos os casos, o plug-in construído será build/distributions/full-lattice-search-*.zip
make run construirá o plug-in e resistirá a um Elasticsearch (com o plug-in instalado) e um Kibana com Docker-Compose
Requer elasticsearch 7.3.0 (suporte para outras versões (> = 6.0.0) em breve / mediante solicitação)

Este plug -in não foi projetado para funcionar com estruturas generalizadas de treliça, mas para trabalhar com uma forma compactada conhecida como rede de confusão ou string de salsichas . Uma rede de confusão representa uma rede generalizada com um conjunto fixo de posições (intervalos de tempo, locais de imagem etc.).
Cada posição tem um conjunto de palavras possíveis e cada palavra tem uma probabilidade de ocorrência associada.
Por exemplo, um reconhecedor de fala automatizado poderia gerar a treliça abaixo, onde o falante realmente disse
"Cada vídeo deve ter menos de dez minutos"

A rede acima pode ser compactada na rede de confusão abaixo.

Observe que os tokens <epsilon> (o que significa a ausência de uma palavra) foram inseridos para permitir que a palavra "entenda" tenha uma duração mais longa do que outros.
Também vale a pena notar que o processo de comprimir uma treliça em uma rede de confusão é geralmente com perdas, o que significa que alguns caminhos através de uma rede de confusão não estão presentes na treliça de origem. Por exemplo, a frase "Be Entender dez minutos" está presente na rede de confusão, mas não na treliça.
Observe que você é responsável por garantir que suas estruturas de treliça sejam formatadas em redes de confusão.
Consulte LattiquetekenFilter Docs para obter detalhes de uso.
Conforme mencionado nos documentos LattiquetekenFilter, o parâmetro score_buckets pode ser usado para indexar tokens duplicados na mesma posição, a fim de aumentar o termo frequência desses tokens em relação à pontuação. Embora isso tenha o efeito desejado, poucas considerações.
8x de tokens ( score_buckets=[0.9, 72, 0.8, 64, 0.7, 56, 0.6, 48, 0.5, 40, 0.4, 32, 0.2, 16, 0.1, 8, 0.01, 2] , muito melhor que o desempenho.8x em 1 speed em 1, na velocidade de speasup.

