LLM RAG Chatbot With LangChain
1.0.0
數據科學家| Anass Majji
在此項目中,我們僅使用CPU在簡化的Web應用程序上使用Langchain部署LLM RAG聊天機器人。
LLM模型旨在從外部文檔中提取相關信息。在我們的情況下,我們已使用GGML量化方法使用了量化版本的Llama-2-7b ,只能與CPU處理器一起使用。
傳統上,LLM僅依賴於提示以及對模型的培訓數據進行了培訓。但是,這種方法在知識方面構成了限制,尤其是在處理超過令牌長度約束的大型數據集時。為了應對這一挑戰,用新的和外部數據源豐富了LLM,將抹布(檢索增強生成)介入。
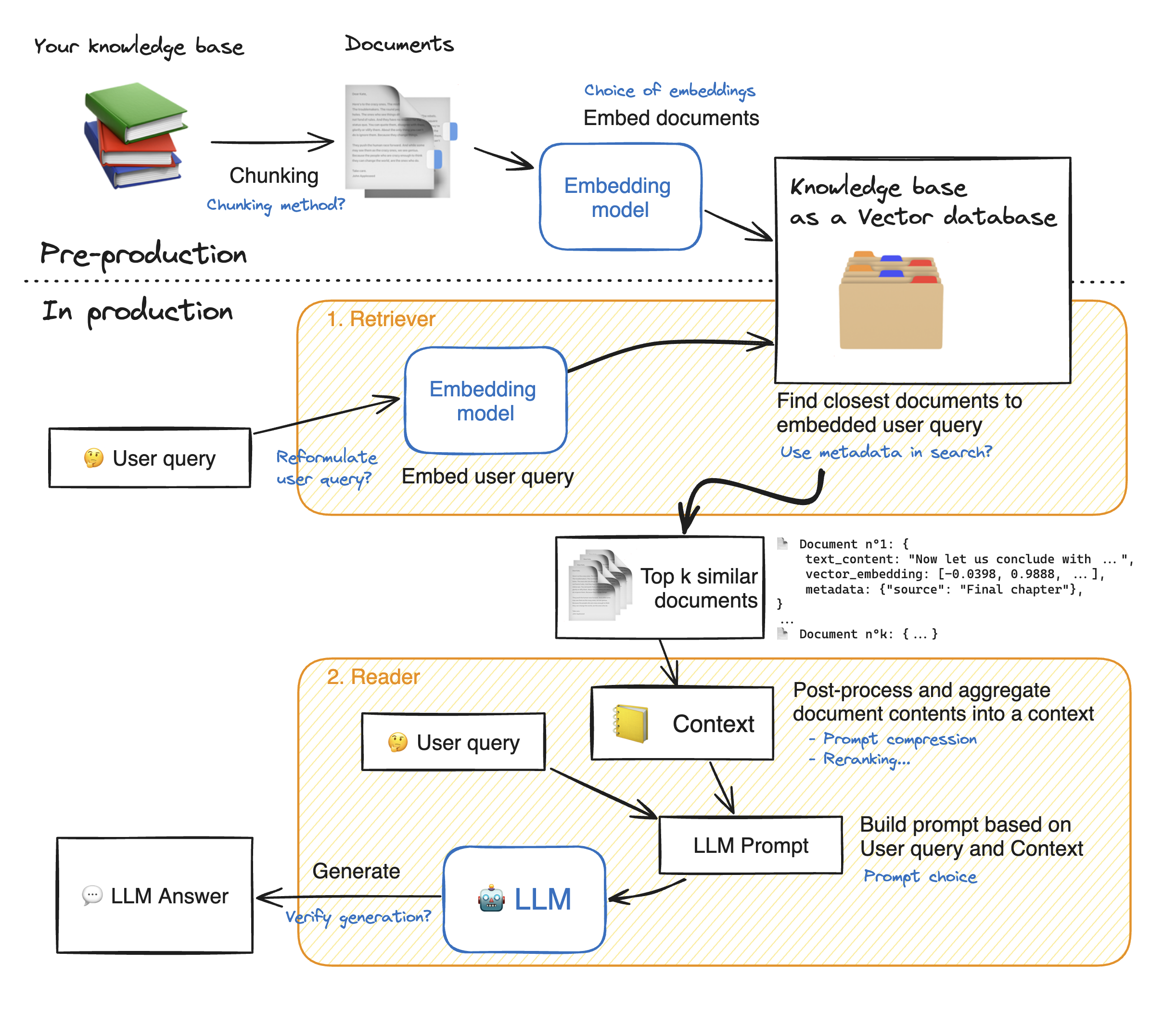
在製作簡化Web應用程序的演示之前,讓我們瀏覽抹布方法的詳細信息,以了解其工作原理。獵犬的作用就像內部搜索引擎:給定用戶查詢,它從外部數據源返回了一些相關元素。這是抹布系統的主要步驟:
1-將我們的知識的每個文檔分成塊並獲取它們的嵌入:我們應該記住,嵌入文檔時,我們將使用一個接受一定最大序列長度max_seq_length的模型。
2-嵌入所有塊後,我們將它們存儲在矢量數據庫中。當用戶鍵入查詢時,它會被先前使用的相同模型嵌入,然後一個相似性搜索將返回矢量數據庫最接近的top_k。為此,我們需要兩個要素:1)一個指標,以在Emddings(Euclidean距離,Cosinus相似性,DOT產品)和2)搜索算法之間找到距離之間的距離(Facebook's Faiss)。我們的特定模型與Cosinus的相似性很好。
3-最後,檢索到的文檔的內容共同匯總到“上下文”中,該查詢也將查詢匯總到“提示”中。然後將其饋送到LLM以生成答案。
在抹布步驟的完美說明下:
為了與LLM達到良好的準確性,我們需要更好地理解和選擇每個藥物。在深入研究細節之前,讓我們想起LLM的解碼過程。眾所周知,LLMS依靠變壓器,每個llms都由兩個主要集體組成:編碼器,將輸入令牌轉換為嵌入式IE數值和解碼器,該數值和解碼器試圖從嵌入式(Encoder的對立)中生成令牌。解碼有兩種主要類型:貪婪和採樣。通過貪婪的解碼,該模型在推理過程中的每個步驟中都可以選擇具有最高概率的令牌。
相比之下,使用採樣解碼,模型選擇了潛在輸出令牌的子集,然後選擇一個隨機的輸出令牌以添加到輸出文本中。這會產生更多的可變性,並幫助LLM更具創造力。但是,選擇採樣解碼器會增加反應不正確的風險。
選擇採樣解碼時,我們還有兩個其他超參數影響模型的性能:top_k和top_p。
TOP_K :TOP_K超參數是一個整數,範圍從1到100 。它代表具有最高概率的K令牌。為了更多地了解背後的想法,讓我們舉個例子:我們有這句話“我去見了一個朋友”,我們想預測下一個令牌,我們有3種可能的可能性1)在城市中心2)2)一起吃3)在城鎮的另一端。現在,讓我們假設“在”,“”和“上”分別具有以下概率[0.23,0.12,0.30]。使用TOP_K = 2,我們將僅選擇兩個具有最高概率的令牌:在我們的情況下,“ in”和“ on”。然後該模型隨機選擇其中之一。
TOP_P :是一個小數點,範圍為0.0至1.0 。該模型嘗試選擇具有其累積概率的子集等於TOP_P值。考慮到上述示例,top_p = 0.55,唯一具有累積概率低於0.55的令牌是“”和“ on”。
溫度:執行與上述TOP_K和TOP_P超級參數相似的功能。它的範圍從0到2 (最大創造力)。背後的想法是改變輸出令牌的概率分佈。由於溫度值較低,該模型會放大概率,而概率較高的令牌則更有可能是輸出,反之亦然。當我們要生成可預測的響應時,使用較低的值。相反,較高的值會導致概率的收斂:它們彼此接近。使用它們推動LLM提高創造力。
我們應該考慮的另一個Paramater是運行LLM所需的內存:對於具有N參數和完整精度(FP32)的模型(FP32)所需的內存是N x 4 Bytes。但是,當我們使用量化時,我們除以(4個字節/新的精度)。使用FP16,新的內存除以4個字節/ 2個字節。
存儲庫包含以下文件和目錄:
在本節中,我們將展示簡化的WebApp。用戶可以提出任何問題,聊天機器人將回答。
要使用Docker啟動簡化應用的部署,請鍵入以下命令:
Docker build -t精簡。 :要構建Docker圖像
Docker Run -P 8501:8501簡化:根據我們的圖像啟動容器
要查看我們的應用程序,用戶可以瀏覽到http://0.0.0.0:8501或http:// localhost:8501
有關任何信息,反饋或問題,請與我聯繫


