LLM RAG Chatbot With LangChain
1.0.0
عالم البيانات | أنس ماجي
في هذا المشروع ، ننشر LLM RAG chatbot مع Langchain على تطبيق ويب بديل باستخدام وحدة المعالجة المركزية فقط.
يهدف نموذج LLM إلى استخراج المعلومات ذات الصلة من المستندات الخارجية. في حالتنا ، استخدمنا النسخة الكمية من LLAMA-2-7B مع نهج قياس الكميات GGML ، ويمكن استخدامه مع معالجات وحدة المعالجة المركزية فقط.
تقليديا ، اعتمدت LLM فقط على موجه وبيانات التدريب التي تم تدريب النموذج عليها. ومع ذلك ، فإن هذا النهج يطرح قيودًا من حيث المعرفة وخاصة عند التعامل مع مجموعات البيانات الكبيرة التي تتجاوز قيود طول الرمز المميز. لمعالجة هذا التحدي ، يتدخل Rag (الجيل المعزز للاسترجاع) من خلال إثراء LLM بمصادر بيانات جديدة وخارجية.
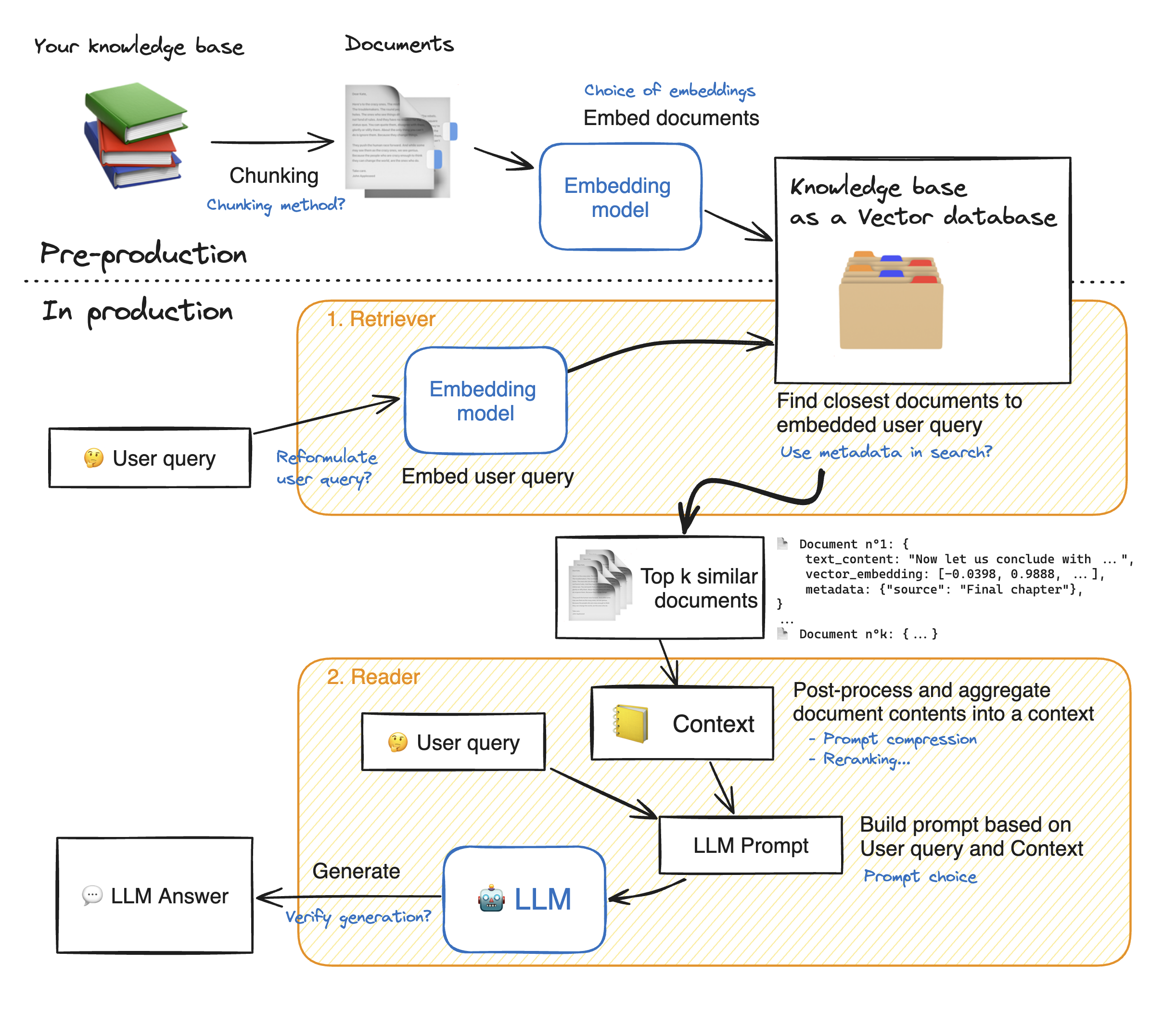
قبل إجراء عرض تجريبي لتطبيق الويب SPEREMLIT ، دعنا نسير عبر تفاصيل نهج الخرقة لفهم كيفية عمله. يتصرف المسترد مثل محرك البحث الداخلي: بالنظر إلى استعلام المستخدم ، فإنه يعيد بعض العناصر ذات الصلة من مصادر البيانات الخارجية. فيما يلي الخطوات الرئيسية لنظام الخرقة:
1 - انقسم كل مستند من معرفتنا إلى أجزاء والحصول على تضميناتها: يجب أن نضع في اعتبارك أنه عند تدمير المستندات ، سنستخدم نموذجًا يقبل الحد الأقصى لطول التسلسل MAX_SEQ_LENGTH.
2 - بمجرد تضمين جميع القطع ، نقوم بتخزينها في قاعدة بيانات المتجهات. عندما يكتب المستخدم استعلامًا ، يتم تضمينه بواسطة نفس النموذج المستخدم مسبقًا ، ثم يقوم بحث التشابه بإرجاع الجزء الأقرب من Top_K من قاعدة بيانات المتجه. للقيام بذلك ، نحتاج إلى عنصرين: 1) مقياس للمسافة بين EMDEDDINGS (المسافة الإقليدية ، تشابه COSINUS ، منتج DOT) و 2) خوارزمية بحث للعثور على أقرب العناصر (Facebook's FAISS). نموذجنا الخاص يعمل بشكل جيد مع تشابه COSINUS.
3 - أخيرًا ، يتم تجميع محتوى المستندات التي تم استردادها معًا في "السياق" ، والذي يتم تجميعه أيضًا مع الاستعلام في "موجه". ثم يتم تغذية LLM لإنشاء إجابات.
أسفل توضيح مثالي لخطوات الخرقة:
من أجل الوصول إلى دقة جيدة مع LLMS ، نحتاج إلى فهم واختيار كل فرط البارامير بشكل أفضل. قبل تعميق الغوص في التفاصيل ، دعونا نذكر عملية فك تشفير LLM. كما نعلم ، تعتمد LLMS على المحولات ، كل منها يتكون من الكتلتين الرئيسيتين: المشفر الذي يحول الرموز المميزة إلى التضمينات ، أي القيم العددية ودلو المدافع الذي يحاول توليد الرموز من التضمين (معارضة الترميز). هناك نوعان رئيسيان من فك التشفير: الجشع وأخذ العينات . مع فك تشفير الجشع ، يختار النموذج ببساطة الرمز المميز بأعلى احتمال في كل خطوة أثناء الاستدلال.
مع فك تشفير أخذ العينات ، على النقيض من ذلك ، يحدد النموذج مجموعة فرعية من الرموز المميزة للإخراج المحتملة واختيار واحد منهم بشكل عشوائي لإضافته إلى نص الإخراج. هذا يخلق المزيد من التباين ويساعد LLM على أن تكون أكثر إبداعًا. ومع ذلك ، فإن اختيار أخذ عينات أخذ العينات يزيد من خطر الاستجابات غير الصحيحة.
عند اختيار فك التشفير لأخذ العينات ، لدينا اثنين من المقاييس الإضافية التي تؤثر على أداء النموذج: TOP_K و TOP_P.
TOP_K : TOP_K Hyperparameter هو عدد صحيح يتراوح من 1 إلى 100 . إنه يمثل الرموز K مع أعلى الاحتمالات. لفهم الفكرة وراءها ، دعونا نأخذ مثالاً: لدينا هذه الجملة "ذهبت لمقابلة صديق" ونريد التنبؤ بالرمز التالي ، لدينا 3 إمكانات 1) في وسط المدينة 2) لتناول الطعام معًا 3) على الجانب الآخر من المدينة. الآن ، دعنا نفترض أن "في" ، "إلى" و "ON" لديهم الاحتمالات التالية على التوالي [0.23 ، 0.12 ، 0.30]. مع TOP_K = 2 ، سنختار فقط اثنين من الرموز مع أعلى الاحتمالات: "في" و "ON" في حالتنا. ثم يختار النموذج بشكل عشوائي واحد منهم.
TOP_P : هي ميزة عشرية تتراوح من 0.0 إلى 1.0 . يحاول النموذج اختيار مجموعة فرعية من الرموز مع احتمالاتها التراكمية تساوي قيمة TOP_P. بالنظر إلى المثال أعلاه ، مع TOP_P = 0.55 ، فإن الرموز المميزة الوحيدة مع احتمالاتها التراكمية أدنى من 0.55 "في" و "ON".
درجة الحرارة : تؤدي وظيفة مماثلة مثل المقاطع الزائدة TOP_K و TOP_P أعلاه. يتراوح من 0 إلى 2 (الحد الأقصى للإبداع). الفكرة وراءها هي تغيير توزيع احتمال الرموز المميزة. مع انخفاض قيمة درجة الحرارة ، يزداد النموذج الاحتمالات ، يعني أن الرموز ذات الاحتمالات العالية تصبح أكثر عرضة للإخراج والعكس بالعكس. يتم استخدام القيم المنخفضة عندما نريد إنشاء استجابات يمكن التنبؤ بها. في المقابل ، تسبب القيم الأعلى تقارب الاحتمالات: تصبح قريبة من بعضها البعض. استخدامهم دفع LLM لتكون أكثر إبداعا.
هناك paramater آخر يجب أن نأخذه في الاعتبار هو الذاكرة اللازمة لتشغيل LLM: بالنسبة لنموذج مع معلمة n ودقة كاملة (FP32) الذاكرة المطلوبة هي n x 4bytes. ومع ذلك ، عندما نستخدم القياس الكمي ، نقسم على (4 بايت/ دقة جديدة). مع FP16 ، يتم تقسيم الذاكرة الجديدة على 4 بايت/ 2 بايت.
يحتوي المستودع على الملفات والدلائل التالية:
في هذا القسم ، سنقوم بإعداد عرض لبرنامج WebApp SPERTELIT. يمكن للمستخدم طرح أي سؤال وسيجيب chatbot.
لبدء نشر تطبيق STREMELIT مع Docker ، اكتب الأوامر التالية:
Docker Build -T Streamlit. : لبناء صورة Docker
Docker Run -P 8501: 8501 SPEMATLIT: لبدء الحاوية بناءً على صورتنا
لعرض تطبيقنا ، يمكن للمستخدمين التصفح إلى http://0.0.0.0:8501 أو http: // localhost: 8501
للحصول على أي معلومات أو ملاحظات أو أسئلة ، يرجى الاتصال بي


