LLM RAG Chatbot With LangChain
1.0.0
Data Scientist | Anass Majji
Dans ce projet, nous déployons un chatbot LLM RAG avec Langchain sur une application Web Streamlit en utilisant uniquement CPU .
Le modèle LLM vise à extraire les informations pertinentes des documents externes. Dans notre cas, nous avons utilisé la version quantifiée de LLAMA-2-7B avec une approche de quantification GGML , elle peut être utilisée avec uniquement des processeurs CPU .
Traditionnellement, le LLM ne s'est appuyé que sur des données d'invite et de formation sur lesquelles le modèle a été formé. Cependant, cette approche a posé des limitations en termes de connaissances, en particulier lorsqu'ils traitent de grands ensembles de données qui dépassent les contraintes de longueur de jetons. Pour relever ce défi, RAG (récupération augmentée de génération) intervient en enrichissant le LLM avec des sources de données nouvelles et externes.
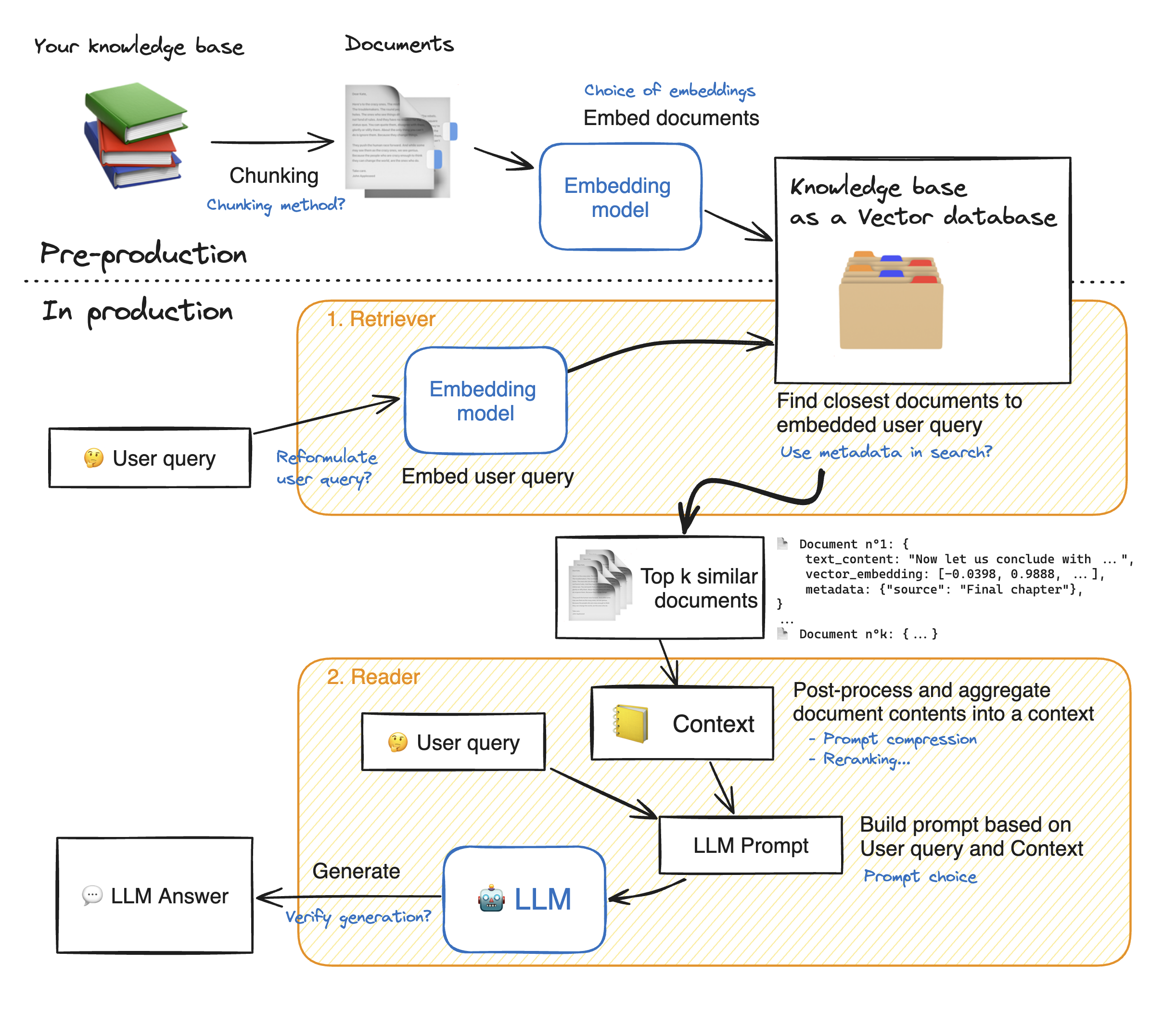
Avant de faire une démo de l'application Web Streamlit, passons les détails de l'approche RAG pour comprendre comment cela fonctionne. Le retriever agit comme un moteur de recherche interne: étant donné une requête utilisateur, il renvoie quelques éléments pertinents à partir des sources de données externes. Voici les principales étapes du système de chiffon:
1 - Divisez chaque document de nos connaissances en morceaux et obtenez leurs incorporations: nous devons garder à l'esprit que lorsque vous incorporerons des documents, nous utiliserons un modèle qui accepterons une certaine longueur de séquence maximale max_seq_length.
2 - Une fois que tous les morceaux sont intégrés, nous les stockons dans une base de données vectorielle. Lorsque l'utilisateur tape une requête, il est intégré par le même modèle précédemment utilisé, une recherche de similitude renvoie les morceaux les plus proches de la base de données vectorielle TOP_K de la base de données vectorielle. Pour ce faire, nous avons besoin de deux éléments: 1) une métrique pour mesurer la distance entre EMDEDDINGS (distance euclidienne, similitude cosinus, produit DOT) et 2) un algorithme de recherche pour trouver les éléments les plus proches (FACSE de Facebook). Notre modèle particulier fonctionne bien avec la similitude des cosinus.
3 - Enfin, le contenu des documents récupérés est agrégé ensemble dans le "contexte", qui est également agrégé avec la requête dans "l'invite". Il est ensuite alimenté au LLM de générer des réponses.
En dessous d'une illustration parfaite des étapes de chiffon:
Afin d'atteindre une bonne précision avec les LLM, nous devons mieux comprendre et choisir chaque hyperparamètre. Avant de plonger dans les détails, rappelons le processus de décodage de la LLM. Comme nous le savons, les LLM s'appuient sur les transformateurs, chacun est composé de deux blocs principaux: l'encodeur qui convertit les jetons d'entrée en intégres, c'est-à-dire des valeurs numériques et un décodeur qui essaie de générer des jetons à partir d'incorporation (l'opposition de l'encodeur). Il existe deux principaux types de décodage: gourmand et échantillonnage . Avec le décodage gourmand, le modèle choisit simplement le jeton avec la probabilité la plus élevée à chaque étape pendant l'inférence.
Avec le décodage d'échantillonnage, en revanche, le modèle sélectionne un sous-ensemble de jetons de sortie potentiels et sélectionnez au hasard l'un d'eux pour ajouter au texte de sortie. Cela crée plus de variabilité et aide le LLM à être plus créatif. Cependant, opter pour le décodeur d'échantillonnage augmente le risque de réponses incorrectes.
Lorsque vous optez pour le décodage d'échantillonnage, nous avons deux hyperparamètres supplémentaires qui ont un impact sur les performances du modèle: top_k et top_p.
top_k : l'hyperparamètre TOP_K est un entier qui va de 1 à 100 . Il représente les jetons K avec les probabilités les plus élevées. Pour mieux comprendre l'idée, prenons un exemple: nous avons cette phrase "Je suis allé rencontrer un ami" et nous voulons prédire le token suivant, nous avons 3 possibilités 1) au centre de la ville 2) pour manger ensemble 3) de l'autre côté de la ville. Maintenant, supposons que "en", "à" et "sur" ont respectivement les probabilités suivantes [0,23, 0,12, 0,30]. Avec top_k = 2, nous allons sélectionner seulement deux jetons avec les probabilités les plus élevées: "in" et "on" dans notre cas. Ensuite, le modèle choisit au hasard l'un d'eux.
TOP_P : est une caractéristique décimale qui varie de 0,0 à 1,0 . Le modèle essaie de choisir un sous-ensemble de jetons avec leurs probabilités cumulatives équivaut à la valeur top_p. Compte tenu de l'exemple ci-dessus, avec un top_p = 0,55, les seuls jetons avec leurs probabilités cumulatives inférieures à 0,55 sont "in" et "on".
Température : remplit une fonction similaire à celle des hyperparamètres top_k et top_p ci-dessus. Il varie de 0 à 2 (maximum de créativité). L'idée derrière est de modifier la distribution de probabilité des jetons de sortie. Avec une valeur de température plus faible, le modèle amplifie les probabilités, les jetons avec des probabilités plus élevées deviennent encore plus susceptibles d'être sortis et vice-versa. Les valeurs plus faibles sont utilisées lorsque nous voulons générer des réponses prévisibles. En revanche, des valeurs plus élevées provoquent une convergence des probabilités: elles se rapprochent les unes des autres. Les utiliser poussez le LLM pour être plus créatif.
Un autre paramater que nous devons prendre en considération est la mémoire nécessaire pour exécuter le LLM: pour un modèle avec un paramètre n et une précision complète (FP32) La mémoire nécessaire est n x 4bytes. Cependant, lorsque nous utilisons la quantification, nous divisons par (4 octets / nouvelle précision). Avec FP16, la nouvelle mémoire est divisée par 4 octets / 2 octets.
Le référentiel contient les fichiers et répertoires suivants:
Dans cette section, nous allons faire une démonstration du webApp rationalisé. L'utilisateur peut poser n'importe quelle question et le chatbot répondra.
Pour lancer le déploiement de l'application Streamlit avec Docker, saisissez les commandes suivantes:
docker build -t streamlit. : Pour construire l'image Docker
Docker Run -P 8501: 8501 Streamlit: Pour lancer le conteneur en fonction de notre image
Pour voir notre application, les utilisateurs peuvent parcourir http://0.0.0.0:8501 ou http: // localhost: 8501
Pour toute information, commentaires ou questions, veuillez me contacter


