LLM RAG Chatbot With LangChain
1.0.0
Científico de datos | Anass Majji
En este proyecto, implementamos un chatbot de trapo LLM con Langchain en una aplicación web a paso a otro utilizando solo CPU .
El modelo LLM tiene como objetivo extraer información relevante de documentos externos. En nuestro caso, hemos utilizado la versión cuantificada de LLAMA-2-7B con un enfoque de cuantización GGML , se puede usar solo con procesadores de CPU .
Tradicionalmente, la LLM solo se ha basado en los datos de capacitación y los datos de capacitación sobre los cuales se capacitó el modelo. Sin embargo, este enfoque planteó limitaciones en términos de conocimiento, especialmente cuando se trata de grandes conjuntos de datos que exceden las limitaciones de longitud del token. Para abordar este desafío, RAG (generación de recuperación aumentada) interviene enriqueciendo la LLM con fuentes de datos nuevas y externas.
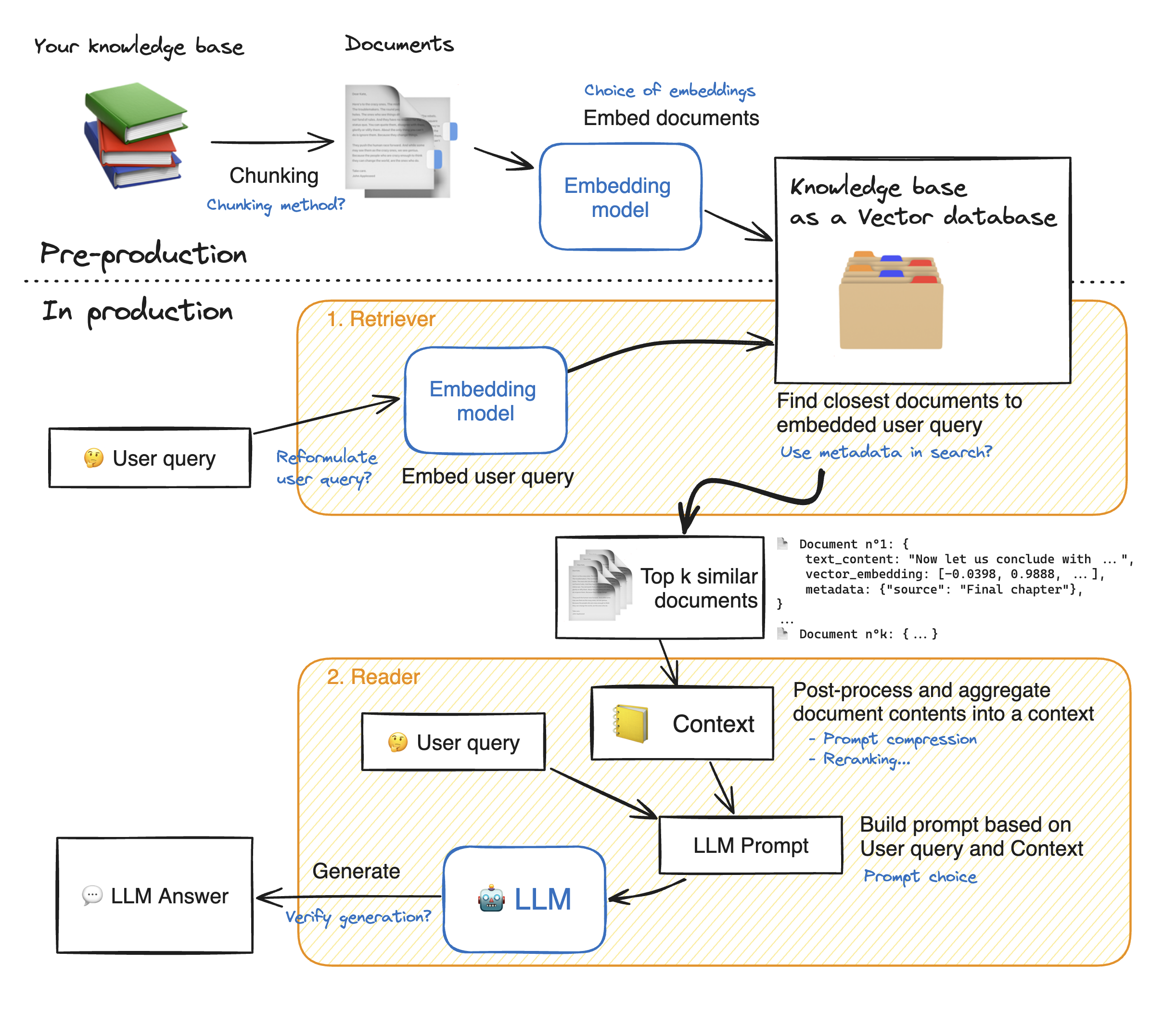
Antes de hacer una demostración de la aplicación web aerodinámica, caminemos a través de los detalles del enfoque RAG para comprender cómo funciona. El Retriever actúa como un motor de búsqueda interno: dada una consulta de usuario, devuelve algunos elementos relevantes de las fuentes de datos externas. Estos son los pasos principales del sistema RAG:
1 - Divida cada documento de nuestro conocimiento en trozos y obtenga sus incrustaciones: debemos tener en cuenta que al embeber los documentos, utilizaremos un modelo que acepte una cierta longitud de secuencia máxima max_seq_length.
2 - Una vez que todos los trozos están integrados, los almacenamos en una base de datos vectorial. Cuando el usuario escribe una consulta, se incrusta por el mismo modelo utilizado anteriormente, entonces una búsqueda de similitud devuelve los fragmentos más cercanos de la base de datos Vector. Para hacerlo, necesitamos dos elementos: 1) una métrica para calmar la distancia entre emdeddings (distancia euclidiana, similitud de cosinal, producto de puntos) y 2) un algoritmo de búsqueda para encontrar los elementos más cercanos (FAISS de Facebook). Nuestro modelo particular funciona bien con la similitud de Cosinus.
3 - Finalmente, el contenido de los documentos recuperados se agrega juntos en el "contexto", que también se agrega con la consulta en el "aviso". Luego se alimenta al LLM para generar respuestas.
Debajo de una ilustración perfecta de los pasos de trapo:
Para alcanzar una buena precisión con los LLM, necesitamos comprender mejor y elegir cada hiperparámetro. Antes de profundizar en los detalles, recordemos el proceso de decodificación de la LLM. Como sabemos, los LLM se basan en transformadores, cada uno está compuesto con dos bloques principales: codificador que convierte los tokens de entrada en incrustaciones, es decir, valores numéricos y decodificadores que intenta generar tokens a partir de incrustaciones (el opuesto del codificador). Hay dos tipos principales de decodificación: codicioso y muestreo . Con una decodificación codiciosa, el modelo simplemente elige el token con la mayor probabilidad en cada paso durante la inferencia.
Con la decodificación de muestreo, en contraste, el modelo selecciona un subconjunto de tokens de salida potenciales y selecciona aleatoriamente uno de ellos para agregar al texto de salida. Esto crea más variabilidad y ayuda a la LLM a ser más creativo. Sin embargo, optar por el decodificador de muestreo aumenta el riesgo de respuestas incorrectas.
Al optar por la decodificación de muestreo, tenemos dos hiperparámetros adicionales que afectan el rendimiento del modelo: TOP_K y TOP_P.
TOP_K : El hiperparámetro TOP_K es un entero que varía de 1 a 100 . Representa las tokens K con las probabilidades más altas. Para comprender más la idea, tomemos un ejemplo: tenemos esta oración "Fui a conocer a un amigo" y queremos predecir la siguiente token, tenemos 3 posibles 1) en el centro de la ciudad 2) para comer juntos 3) al otro lado de la ciudad. Ahora, suponga que "en", "a" y "en" tienen respectivamente las siguientes probabilidades [0.23, 0.12, 0.30]. Con top_k = 2, vamos a seleccionar solo dos tokens con las probabilidades más altas: "in" y "on" en nuestro caso. Entonces el modelo elige al azar uno de ellos.
TOP_P : es una característica decimal que varía de 0.0 a 1.0 . El modelo intenta elegir un subconjunto de tokens con sus probabilidades acumulativas es igual al valor TOP_P. Teniendo en cuenta el ejemplo anterior, con un top_p = 0.55, las únicas tokens con sus probabilidades acumulativas inferiores a 0.55 son "in" y "encendido".
Temperatura : realiza una función similar a los hiperparametros Top_K y TOP_P anteriores. Varía de 0 a 2 (máximo de creatividad). La idea detrás es cambiar la distribución de probabilidad de los tokens de salida. Con un valor de temperatura más bajo, el modelo amplifica las probabilidades, los tokens con probabilidades más altas se vuelven aún más propensas a ser salidas y viceversa. Los valores más bajos se usan cuando queremos generar respuestas predecibles. Por el contrario, los valores más altos causan convergencia de las probabilidades: se vuelven cercanos entre sí. Usarlos empuja a la LLM para que sea más creativo.
Otro parámetro que debemos tener en cuenta es la memoria necesaria para ejecutar el LLM: para un modelo con N de parámetro y una precisión completa (FP32), la memoria necesaria es N x 4bytes. Sin embargo, cuando usamos cuantización, nos dividimos por (4 bytes/ nueva precisión). Con FP16, la nueva memoria se divide por 4 bytes/ 2 bytes.
El repositorio contiene los siguientes archivos y directorios:
En esta sección, vamos a hacer una demostración de la aplicación web aerodinámica. El usuario puede hacer cualquier pregunta y el chatbot responderá.
Para iniciar la implementación de la aplicación Streamlit con Docker, escriba los siguientes comandos:
Docker Build -T Streamlit. : para construir la imagen de Docker
Docker Run -P 8501: 8501 Streamlit: para iniciar el contenedor basado en nuestra imagen
Para ver nuestra aplicación, los usuarios pueden navegar a http://0.0.0.0:8501 o http: // localhost: 8501
Para obtener información, comentarios o preguntas, contácteme


