LLM RAG Chatbot With LangChain
1.0.0
数据科学家| Anass Majji
在此项目中,我们仅使用CPU在简化的Web应用程序上使用Langchain部署LLM RAG聊天机器人。
LLM模型旨在从外部文档中提取相关信息。在我们的情况下,我们已使用GGML量化方法使用了量化版本的Llama-2-7b ,只能与CPU处理器一起使用。
传统上,LLM仅依赖于提示以及对模型的培训数据进行了培训。但是,这种方法在知识方面构成了限制,尤其是在处理超过令牌长度约束的大型数据集时。为了应对这一挑战,用新的和外部数据源丰富了LLM,将抹布(检索增强生成)介入。
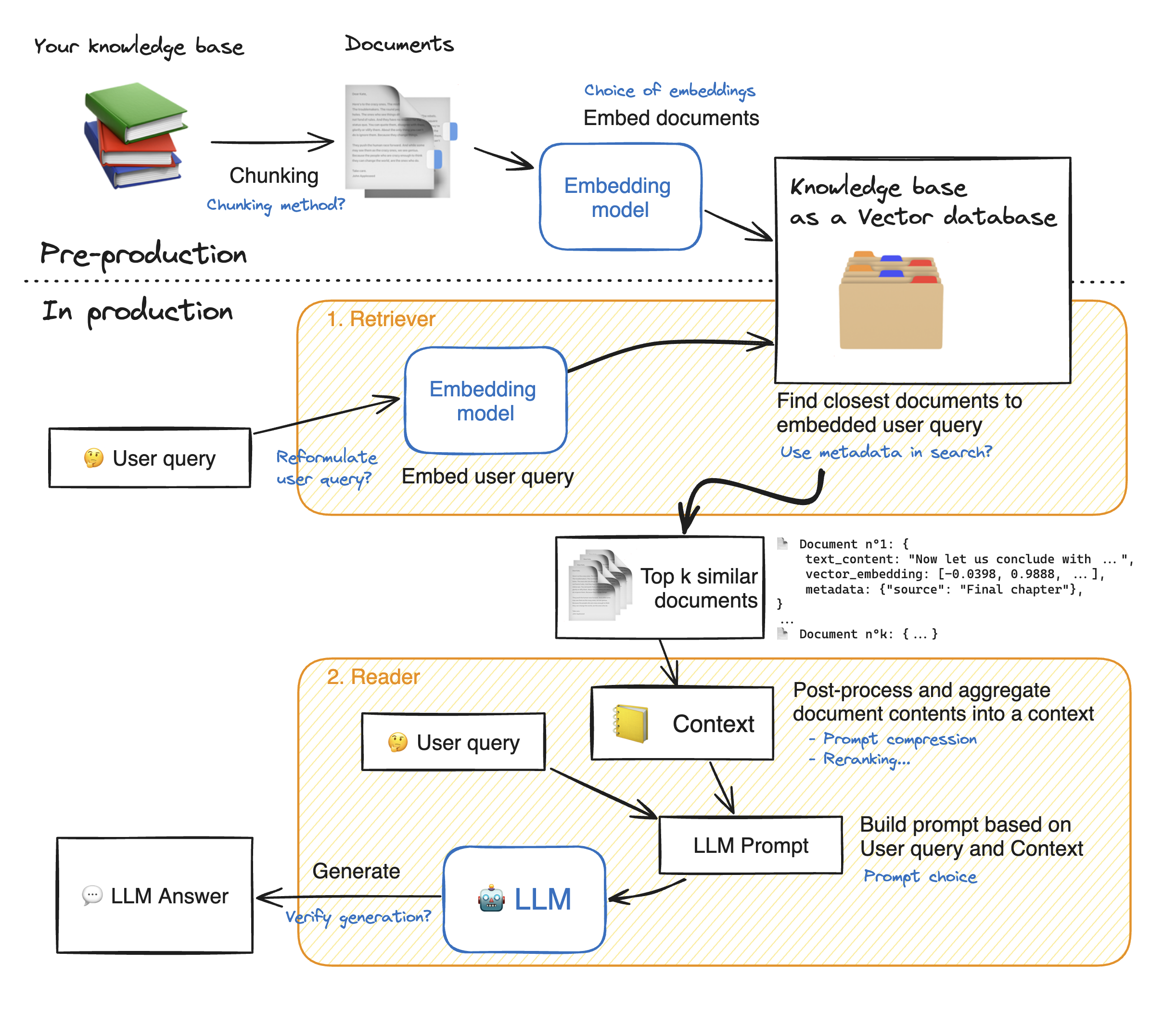
在制作简化Web应用程序的演示之前,让我们浏览抹布方法的详细信息,以了解其工作原理。猎犬的作用就像内部搜索引擎:给定用户查询,它从外部数据源返回了一些相关元素。这是抹布系统的主要步骤:
1-将我们的知识的每个文档分成块并获取它们的嵌入:我们应该记住,嵌入文档时,我们将使用一个接受一定最大序列长度max_seq_length的模型。
2-嵌入所有块后,我们将它们存储在矢量数据库中。当用户键入查询时,它会被先前使用的相同模型嵌入,然后一个相似性搜索将返回矢量数据库最接近的top_k。为此,我们需要两个要素:1)一个指标,以在Emddings(Euclidean距离,Cosinus相似性,DOT产品)和2)搜索算法之间找到距离之间的距离(Facebook's Faiss)。我们的特定模型与Cosinus的相似性很好。
3-最后,检索到的文档的内容共同汇总到“上下文”中,该查询也将查询汇总到“提示”中。然后将其馈送到LLM以生成答案。
在抹布步骤的完美说明下:
为了与LLM达到良好的准确性,我们需要更好地理解和选择每个药物。在深入研究细节之前,让我们想起LLM的解码过程。众所周知,LLMS依靠变压器,每个llms都由两个主要集体组成:编码器,将输入令牌转换为嵌入式IE数值和解码器,该数值和解码器试图从嵌入式(Encoder的对立)中生成令牌。解码有两种主要类型:贪婪和采样。通过贪婪的解码,该模型在推理过程中的每个步骤中都可以选择具有最高概率的令牌。
相比之下,使用采样解码,模型选择了潜在输出令牌的子集,然后选择一个随机的输出令牌以添加到输出文本中。这会产生更多的可变性,并帮助LLM更具创造力。但是,选择采样解码器会增加反应不正确的风险。
选择采样解码时,我们还有两个其他超参数影响模型的性能:top_k和top_p。
TOP_K :TOP_K超参数是一个整数,范围从1到100 。它代表具有最高概率的K令牌。为了更多地了解背后的想法,让我们举个例子:我们有这句话“我去见了一个朋友”,我们想预测下一个令牌,我们有3种可能的可能性1)在城市中心2)2)一起吃3)在城镇的另一端。现在,让我们假设“在”,“”和“上”分别具有以下概率[0.23,0.12,0.30]。使用TOP_K = 2,我们将仅选择两个具有最高概率的令牌:在我们的情况下,“ in”和“ on”。然后该模型随机选择其中之一。
TOP_P :是一个小数点,范围为0.0至1.0 。该模型尝试选择具有其累积概率的子集等于TOP_P值。考虑到上述示例,top_p = 0.55,唯一具有累积概率低于0.55的令牌是“”和“ on”。
温度:执行与上述TOP_K和TOP_P超级参数相似的功能。它的范围从0到2 (最大创造力)。背后的想法是改变输出令牌的概率分布。由于温度值较低,该模型会放大概率,而概率较高的令牌则更有可能是输出,反之亦然。当我们要生成可预测的响应时,使用较低的值。相反,较高的值会导致概率的收敛:它们彼此接近。使用它们推动LLM提高创造力。
我们应该考虑的另一个Paramater是运行LLM所需的内存:对于具有N参数和完整精度(FP32)的模型(FP32)所需的内存是N x 4 Bytes。但是,当我们使用量化时,我们除以(4个字节/新的精度)。使用FP16,新的内存除以4个字节/ 2个字节。
存储库包含以下文件和目录:
在本节中,我们将展示简化的WebApp。用户可以提出任何问题,聊天机器人将回答。
要使用Docker启动简化应用的部署,请键入以下命令:
Docker build -t精简。 :要构建Docker图像
Docker Run -P 8501:8501简化:根据我们的图像启动容器
要查看我们的应用程序,用户可以浏览到http://0.0.0.0:8501或http:// localhost:8501
有关任何信息,反馈或问题,请与我联系


