LLM RAG Chatbot With LangChain
1.0.0
Ученый данных | Анасс Маджи
В этом проекте мы развертываем чат -бот LLM Rag с Langchain в веб -приложении Streamlit , используя только процессор .
Модель LLM направлена на извлечение соответствующей информации из внешних документов. В нашем случае мы использовали квантовую версию Llama-2-7B с подходом квантования GGML , ее можно использовать только с процессорами процессора .
Традиционно, LLM полагался только на быстрые и учебные данные, на которые была обучена модель. Тем не менее, этот подход создавал ограничения с точки зрения знаний, особенно при работе с большими наборами данных, которые превышают ограничения длины токена. Чтобы решить эту проблему, Rag (извлеченное дополненное поколение) вмешивается, обогащая LLM с помощью новых и внешних источников данных.
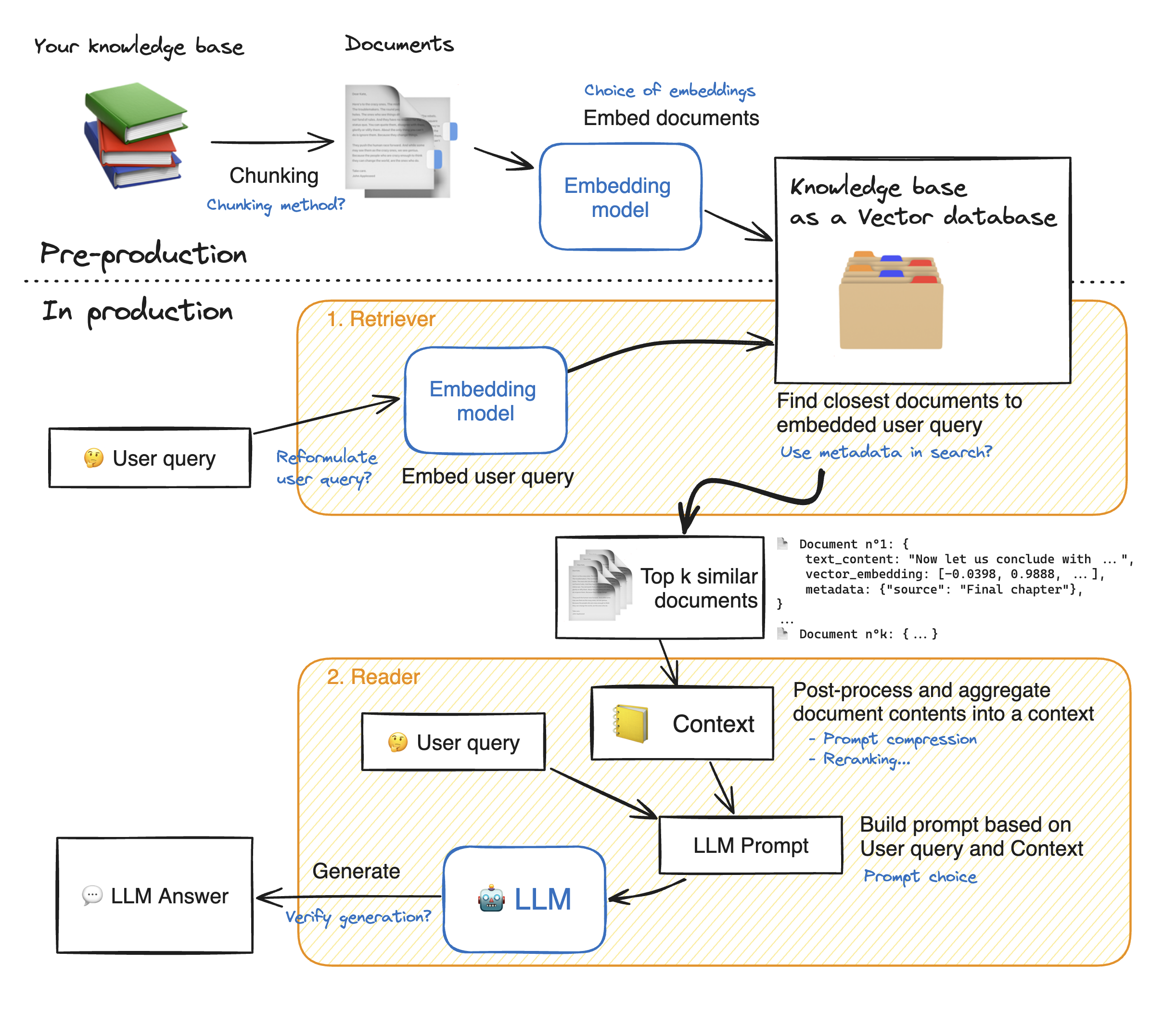
Прежде чем сделать демонстрацию веб -приложения Streathlit, давайте пройдемся подробности подхода Rag, чтобы понять, как оно работает. Ретривер действует как внутренняя поисковая система: с учетом запроса пользователя, он возвращает несколько соответствующих элементов из внешних источников данных. Вот основные этапы системы RAG:
1 - Разделите каждый документ нашего знания на куски и получите их встраивание: мы должны иметь в виду, что при смеси документов мы будем использовать модель, которая принимает определенную максимальную длину последовательности max_seq_length.
2 - Как только все кусочки встроены, мы храним их в векторной базе данных. Когда пользователь набирает запрос, он внедряется той же ранее использованной моделью, а поиск сходства возвращает ближайшие куски TOP_K из векторной базы данных. Для этого нам нужны два элемента: 1) метрика, чтобы засорить расстояние между эмпдингами (евклидовое расстояние, сходство Cosinus, точечный продукт) и 2) алгоритм поиска, чтобы найти ближайшие элементы (Faceis Faiss). Наша конкретная модель хорошо работает с сходством Cosinus.
3 - Наконец, содержание извлеченных документов объединяется вместе в «контекст», который также агрегируется с запросом в «подсказку». Затем его подают в LLM, чтобы генерировать ответы.
Ниже идеальная иллюстрация тряпичных шагов:
Чтобы достичь хорошей точности с LLMS, нам нужно лучше понять и выбрать каждый гиперпараметр. Прежде чем углубиться в детали, давайте напомним процесс декодирования LLM. Как мы знаем, LLM полагаются на трансформаторы, каждый из них состоит из двух основных блоков: энкодер , который преобразует входные токены в встраиваемые значения, то есть численные значения и декодер , который пытается генерировать токены из встраивания (противоположность энкодера). Есть два основных типа декодирования: жадный и отбор проб . При жадном декодировании модель просто выбирает токен с самой высокой вероятностью на каждом этапе во время вывода.
С помощью декодирования выборки, напротив, модель выбирает подмножество потенциальных выходных токенов и выбирает один из них, чтобы добавить к выходному тексту. Это создает большую изменчивость и помогает LLM быть более креативным. Тем не менее, выбор для отбора проб декодера увеличивает риск неверных ответов.
При выборе декодирования выборки у нас есть два дополнительных гиперпараметров, которые влияют на производительность модели: top_k и top_p.
TOP_K : Гиперпараметр TOP_K - это целое число, которое варьируется от 1 до 100 . Он представляет токены K с самыми высокими вероятностями. Чтобы получить более того, чтобы понять идею, давайте приведем пример: у нас есть это предложение «Я пошел на встречу с другом», и мы хотим предсказать следующий токен, у нас есть 3 возможностей 1) в центре города 2), чтобы поесть вместе 3) на другой части города. Теперь, давайте предположим, что «в», «до» и «на» имеют соответственно следующие вероятности [0,23, 0,12, 0,30]. С Top_k = 2 мы собираемся выбрать только два токена с самыми высокими вероятностями: «в» и «on» в нашем случае. Затем модель выбирает случайным образом один из них.
TOP_P : это десятичная особенность, которая варьируется от 0,0 до 1,0 . Модель пытается выбрать подмножество токенов с их кумулятивными вероятностями, равным значению TOP_P. Учитывая приведенный выше пример, с TOP_P = 0,55, единственные токены с их кумулятивными вероятностями, уступающими 0,55, являются «в» и «ON».
Температура : выполняет аналогичную функцию, что и вышеуказанная гиперпараметры Top_K и TOP_P. Он колеблется от 0 до 2 (максимум творчества). Идея состоит в том, чтобы изменить вероятность распределения выходных токенов. С более низким значением температуры модель усиливает вероятности, токены с более высокой вероятностью становятся еще более вероятностью, и наоборот. Более низкие значения используются, когда мы хотим генерировать предсказуемые ответы. Напротив, более высокие значения вызывают сходимость вероятностей: они приближаются друг к другу. Использование их толкайте LLM, чтобы быть более креативным.
Другим параматером, который мы должны принять во внимание, является память, необходимая для запуска LLM: для модели с параметром n и полной точностью (FP32) необходимой памяти является n x 4bytes. Однако, когда мы используем квантование, мы делимся на (4 байта/ новую точность). С FP16 новая память делится на 4 байта/ 2 байта.
Репозиторий содержит следующие файлы и каталоги:
В этом разделе мы собираемся сделать демонстрацию потокового веб -приложения. Пользователь может задать любой вопрос, и чатбот ответит.
Чтобы запустить развертывание приложения Streamlit с Docker, введите следующие команды:
Docker Build -t -стрижка. : Чтобы построить изображение Docker
Docker Run -p 8501: 8501 Streamlit: чтобы запустить контейнер на основе нашего изображения
Чтобы просмотреть наше приложение, пользователи могут перейти на http://0.0.0.0:8501 или http: // localhost: 8501
Для получения информации, обратной связи или вопросов, пожалуйста, свяжитесь со мной


