LLM RAG Chatbot With LangChain
1.0.0
Ilmuwan Data | Anass Majji
Dalam proyek ini, kami menggunakan chatbot Rag LLM dengan Langchain pada aplikasi web yang streamlit hanya menggunakan CPU .
Model LLM bertujuan untuk mengekstraksi informasi yang relevan dari dokumen eksternal. Dalam kasus kami, kami telah menggunakan versi kuantisasi LLAMA-2-7B dengan pendekatan kuantisasi GGML , dapat digunakan hanya dengan prosesor CPU .
Secara tradisional, LLM hanya mengandalkan Prompt dan data pelatihan di mana model dilatih. Namun, pendekatan ini menimbulkan keterbatasan dalam hal pengetahuan terutama ketika berhadapan dengan kumpulan data besar yang melebihi batasan panjang token. Untuk mengatasi tantangan ini, RAG (Retrieval Augmented Generation) mengintervensi dengan memperkaya LLM dengan sumber data baru dan eksternal.
Sebelum membuat demo aplikasi Web yang diinuh, mari kita berjalan melalui detail pendekatan RAG untuk memahami cara kerjanya. Retriever bertindak seperti mesin pencari internal: Diberikan kueri pengguna, ia mengembalikan beberapa elemen yang relevan dari sumber data eksternal. Berikut adalah langkah utama dari sistem kain:
1 - Pisahkan setiap dokumen pengetahuan kita menjadi potongan -potongan dan dapatkan embeddings mereka: kita harus ingat bahwa ketika memulai dokumen, kita akan menggunakan model yang menerima panjang urutan maksimum tertentu max_seq_length.
2 - Setelah semua potongan tertanam, kami menyimpannya dalam database vektor. Ketika pengguna mengetikkan kueri, itu akan tertanam oleh model yang sama yang sebelumnya digunakan, kemudian pencarian kesamaan mengembalikan potongan top_k terdekat dari database vektor. Untuk melakukannya, kita membutuhkan dua elemen: 1) Metrik untuk Mesure Jarak antara Emdeddings (jarak Euclidean, kesamaan cosinus, produk titik) dan 2) algoritma pencarian untuk menemukan elemen terdekat (FAIS Facebook). Model khusus kami bekerja dengan baik dengan kesamaan Cosinus.
3 - Akhirnya, isi dokumen yang diambil dikumpulkan bersama menjadi "konteks", yang juga dikumpulkan dengan kueri ke dalam "prompt". Kemudian diumpankan ke LLM untuk menghasilkan jawaban.
Di bawah ilustrasi sempurna dari langkah -langkah kain:
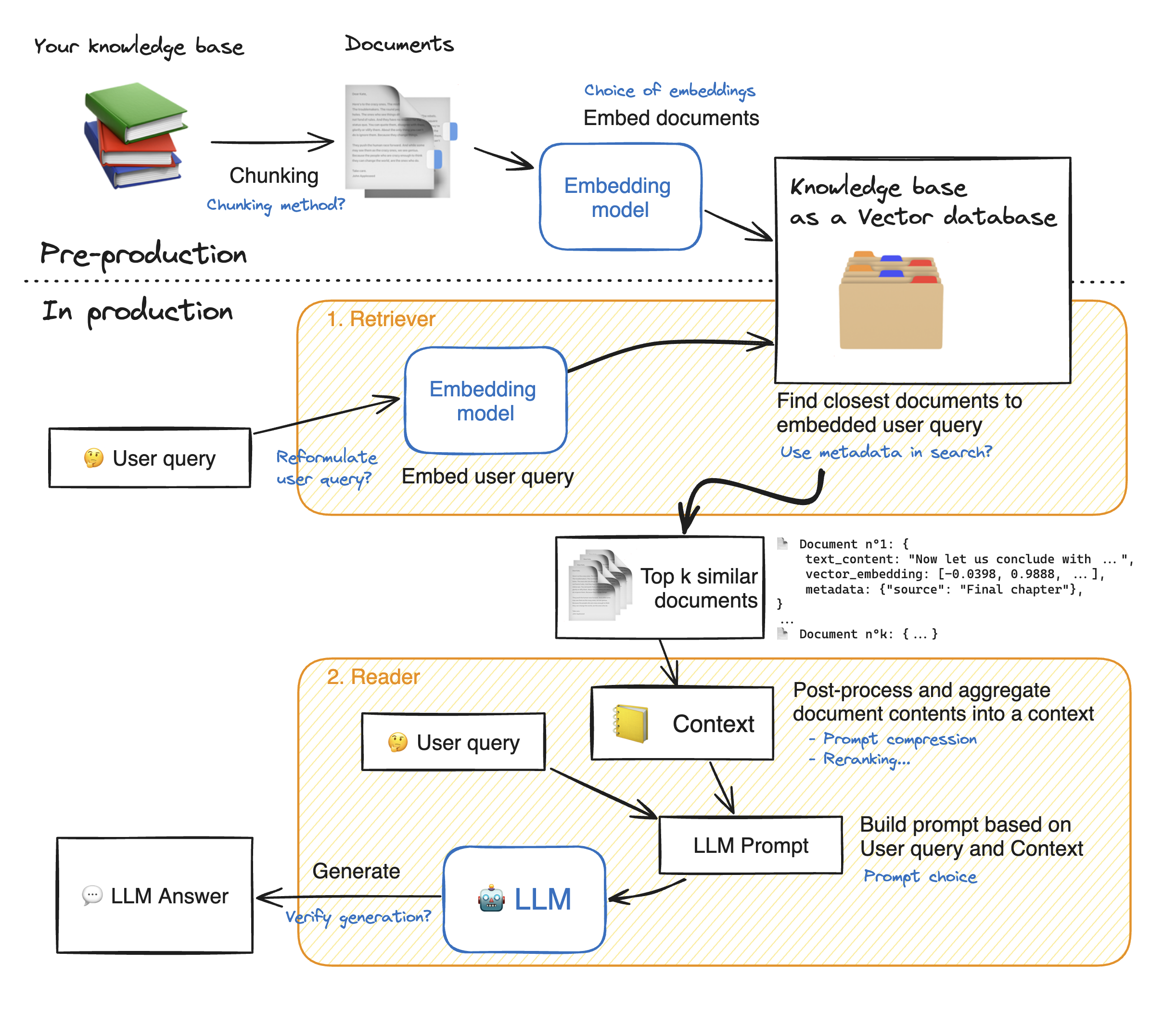
Untuk mencapai akurasi yang baik dengan LLMS, kita perlu lebih memahami dan memilih setiap hiperparameter. Sebelum mendalam menyelam ke detail, mari kita ingatkan proses decoding LLM. Seperti yang kita ketahui, LLM mengandalkan transformator, masing -masing disusun dengan dua blok utama: encoder yang mengubah token input menjadi embeddings yaitu nilai numerik dan decoder yang mencoba menghasilkan token dari embeddings (lawan encoder). Ada dua jenis decoding utama: serakah dan pengambilan sampel . Dengan decoding serakah, model hanya memilih token dengan probabilitas tertinggi pada setiap langkah selama inferensi.
Dengan pengambilan sampel decoding, sebaliknya, model memilih subset token output potensial dan pilih secara acak salah satunya untuk ditambahkan ke teks output. Ini menciptakan lebih banyak variabilitas dan membantu LLM menjadi lebih kreatif. Namun, memilih decoder pengambilan sampel meningkatkan risiko respons yang salah.
Saat memilih pengambilan sampel decoding, kami memiliki dua hyperparameters tambahan yang memengaruhi kinerja model: Top_k dan Top_p.
Top_k : Hyperparameter Top_K adalah bilangan bulat yang berkisar dari 1 hingga 100 . Ini mewakili token K dengan probabilitas tertinggi. Untuk lebih memahami ide di baliknya, mari kita ambil contoh: kita memiliki kalimat ini "Saya pergi untuk bertemu teman" dan kami ingin memprediksi token berikutnya, kami memiliki 3 kemungkinan 1) di pusat kota 2) untuk makan bersama 3) di sisi lain kota. Sekarang, biarkan asumsikan bahwa "dalam", "ke" dan "on" masing -masing memiliki probabilitas berikut [0,23, 0,12, 0,30]. Dengan top_k = 2, kita akan memilih hanya dua token dengan probabilitas tertinggi: "dalam" dan "on" dalam kasus kami. Kemudian model memilih secara acak salah satunya.
Top_p : adalah fitur desimal yang berkisar antara 0,0 hingga 1,0 . Model mencoba memilih subset token dengan probabilitas kumulatifnya sama dengan nilai Top_p. Mempertimbangkan contoh di atas, dengan top_p = 0,55, satu -satunya token dengan probabilitas kumulatifnya lebih rendah dari 0,55 adalah "dalam" dan "on".
Suhu : Melakukan fungsi yang sama dengan Hyperparameters Top_K dan Top_P di atas. Ini berkisar dari 0 hingga 2 (maksimum kreativitas). Gagasan di baliknya adalah untuk mengubah distribusi probabilitas token output. Dengan nilai suhu yang lebih rendah, model memperkuat probabilitas, berarti token dengan probabilitas yang lebih tinggi menjadi lebih mungkin menjadi output dan sebaliknya. Nilai yang lebih rendah digunakan ketika kita ingin menghasilkan respons yang dapat diprediksi. Sebaliknya, nilai yang lebih tinggi menyebabkan konvergensi probabilitas: mereka menjadi dekat satu sama lain. Menggunakan mereka mendorong LLM untuk menjadi lebih kreatif.
Paramater lain yang harus kita pertimbangkan adalah memori yang diperlukan untuk menjalankan LLM: untuk model dengan parameter N dan presisi penuh (FP32) memori yang dibutuhkan adalah N x 4bytes. Namun, ketika kami menggunakan kuantisasi, kami membaginya dengan (4 byte/ presisi baru). Dengan FP16, memori baru dibagi dengan 4 byte/ 2 byte.
Repositori berisi file & direktori berikut:
Di bagian ini, kita akan melakukan demonstrasi Webapp yang diintong. Pengguna dapat mengajukan pertanyaan apa pun dan chatbot akan menjawab.
Untuk meluncurkan penyebaran aplikasi StreamLit dengan Docker, ketik perintah berikut:
Docker Build -t Streamlit. : Untuk membangun gambar Docker
Docker Run -P 8501: 8501 StreamLit: Untuk meluncurkan wadah berdasarkan gambar kami
Untuk melihat aplikasi kami, pengguna dapat menelusuri ke http://0.0.0.0:8501 atau http: // localhost: 8501
Untuk informasi, umpan balik, atau pertanyaan apa pun, silakan hubungi saya


