LLM RAG Chatbot With LangChain
1.0.0
Cientista de dados | ANASS Majji
Neste projeto, implantamos um LLM Rag Chatbot com o Langchain em um aplicativo Web StreamLit usando apenas a CPU .
O modelo LLM visa extrair informações relevantes de documentos externos. No nosso caso, usamos a versão quantizada do LLAMA-2-7B com abordagem de quantização GGML , ela pode ser usada apenas com processadores CPU .
Tradicionalmente, o LLM se baseia apenas em prompt e nos dados de treinamento nos quais o modelo foi treinado. No entanto, essa abordagem representava limitações em termos de conhecimento, especialmente ao lidar com grandes conjuntos de dados que excedem as restrições de comprimento do token. Para enfrentar esse desafio, o RAG (geração aumentada de recuperação) intervém enriquecendo o LLM com fontes de dados novas e externas.
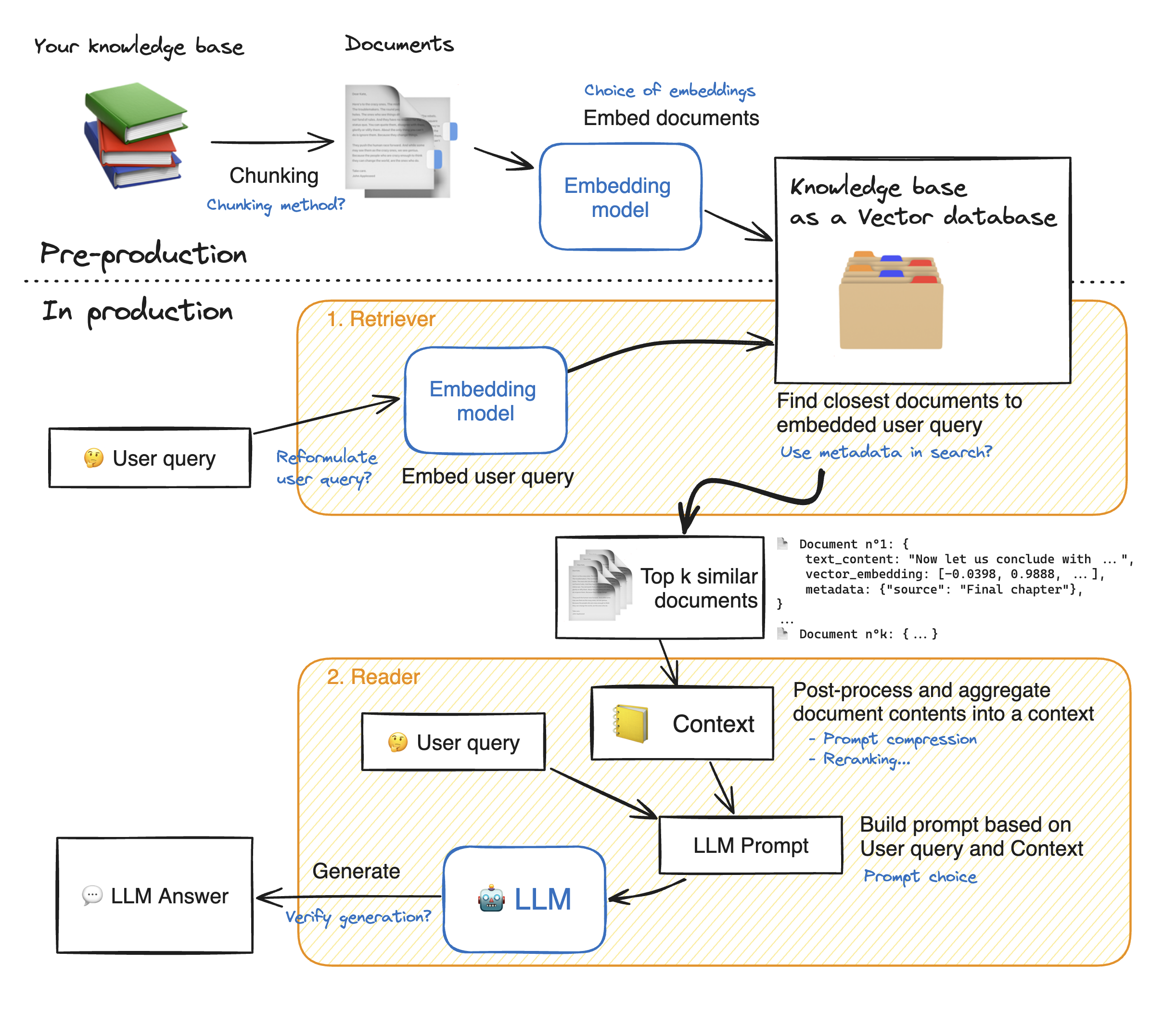
Antes de fazer uma demonstração do aplicativo da Web Streamlit, vamos percorrer os detalhes da abordagem RAG para entender como ele funciona. O Retriever age como um mecanismo de pesquisa interna: dada a consulta de um usuário, ele retorna alguns elementos relevantes das fontes de dados externas. Aqui estão as principais etapas do sistema de pano:
1 - Divida cada documento de nosso conhecimento em pedaços e obtenha suas incorporações: devemos ter em mente que, ao embater em documentos, usaremos um modelo que aceite um certo comprimento máximo de sequência max_seq_length.
2 - Depois que todos os pedaços estiverem incorporados, os armazenamos em um banco de dados vetorial. Quando o usuário digita uma consulta, ele é incorporado pelo mesmo modelo usado anteriormente, uma pesquisa de similaridade retorna os pedaços mais próximos do banco de dados Vector. Para fazer isso, precisamos de dois elementos: 1) uma métrica para mesclar a distância entre os emeddings (distância euclidiana, similaridade de Cosinus, produto DOT) e 2) um algoritmo de pesquisa para encontrar os elementos mais próximos (FAISS do Facebook). Nosso modelo particular funciona bem com a similaridade de Cosinus.
3 - Finalmente, o conteúdo dos documentos recuperados é agregado juntos no "contexto", que também é agregado com a consulta no "prompt". Em seguida, é alimentado ao LLM para gerar respostas.
Abaixo de uma ilustração perfeita dos passos do trapo:
Para alcançar uma boa precisão com o LLMS, precisamos entender e escolher melhor cada hiperparâmetro. Antes de aprofundar os detalhes, vamos lembrar o processo de decodificação do LLM. Como sabemos, os LLMs dependem de transformadores, cada um é composto com dois blocos principais: codificador que converte os tokens de entrada em incorporação, ou seja, valores numéricos e decodificadores que tenta gerar tokens a partir de incorporações (o oposto do codificador). Existem dois tipos principais de decodificação: ganancioso e amostragem . Com decodificação gananciosa, o modelo simplesmente escolhe o token com a maior probabilidade em cada etapa durante a inferência.
Com a decodificação de amostragem, por outro lado, o modelo seleciona um subconjunto de tokens de saída em potencial e selecione aleatoriamente um deles para adicionar ao texto de saída. Isso cria mais variabilidade e ajuda o LLM a ser mais criativo. No entanto, a opção de decodificador de amostragem aumenta o risco de respostas incorretas.
Ao optar por decodificar a amostragem, temos dois hiperparâmetros adicionais que afetam o desempenho do modelo: TOP_K e TOP_P.
TOP_K : O Hyperparameter TOP_K é um número inteiro que varia de 1 a 100 . Representa os K tokens com as mais altas probabilidades. Para entender mais a idéia por trás, vamos dar um exemplo: temos essa frase "Fui encontrar um amigo" e queremos prever o próximo token, temos 3 possibilidades 1) no centro da cidade 2) comer juntos 3) do outro lado da cidade. Agora, vamos supor que "em", "para" e "on" possui respectivamente as seguintes probabilidades [0,23, 0,12, 0,30]. Com TOP_K = 2, selecionaremos apenas dois tokens com as mais altas probabilidades: "in" e "on" no nosso caso. Então o modelo escolhe aleatoriamente um deles.
TOP_P : é um recurso decimal que varia de 0,0 a 1,0 . O modelo tenta escolher um subconjunto de tokens com suas probabilidades cumulativas iguais ao valor TOP_P. Considerando o exemplo acima, com um top_p = 0,55, os únicos tokens com suas probabilidades cumulativas inferiores a 0,55 estão "em" e "on".
Temperatura : desempenha uma função semelhante à dos hiperparâmetros TOP_K e TOP_P acima. Varia de 0 a 2 (máximo de criatividade). A idéia por trás é alterar a distribuição de probabilidade dos tokens de saída. Com um valor de temperatura mais baixo, o modelo amplifica as probabilidades, significa que os tokens com mais probabilidades se tornam ainda mais propensos a ser produzidos e vice-versa. Os valores mais baixos são usados quando queremos gerar respostas previsíveis. Por outro lado, valores mais altos causam convergência das probabilidades: eles se tornam próximos um do outro. Usá -los pressionando o LLM para ser mais criativo.
Outro paramater que devemos levar em consideração é a memória necessária para executar o LLM: para um modelo com o parâmetro n e uma precisão completa (fp32), a memória necessária é n x 4bytes. No entanto, quando usamos quantização, dividimos por (4 bytes/ nova precisão). Com FP16, a nova memória é dividida por 4 bytes/ 2 bytes.
O repositório contém os seguintes arquivos e diretórios:
Nesta seção, faremos uma demonstração do WebApp de streamlit. O usuário pode fazer qualquer pergunta e o chatbot responderá.
Para iniciar a implantação do aplicativo Streamlit com o Docker, digite os seguintes comandos:
Docker Build -T Streamlit. : Para construir a imagem do Docker
Docker Run -P 8501: 8501 StreamLit: Para iniciar o contêiner com base em nossa imagem
Para visualizar nosso aplicativo, os usuários podem navegar para http://0.0.0.0:8501 ou http: // localhost: 8501
Para qualquer informação, feedback ou perguntas, entre em contato comigo


