LLM RAG Chatbot With LangChain
1.0.0
データサイエンティスト| Anass Majji
このプロジェクトでは、 CPUのみを使用して、 RangchainとLangchainを使用してLLM RAGチャットボットをLangchainと展開します。
LLMモデルは、外部ドキュメントから関連する情報を抽出することを目的としています。私たちの場合、 GGML量子化アプローチでLLAMA-2-7Bの量子化バージョンを使用しました。これは、 CPUプロセッサのみで使用できます。
従来、LLMはプロンプトとモデルがトレーニングされたトレーニングデータにのみ依存していました。ただし、このアプローチは、特にトークンの長さの制約を超える大きなデータセットを扱う場合、知識の観点から制限を提起しました。この課題に対処するために、RAG(検索拡張生成)は、新しい外部データソースをLLMに充実させることで介入します。
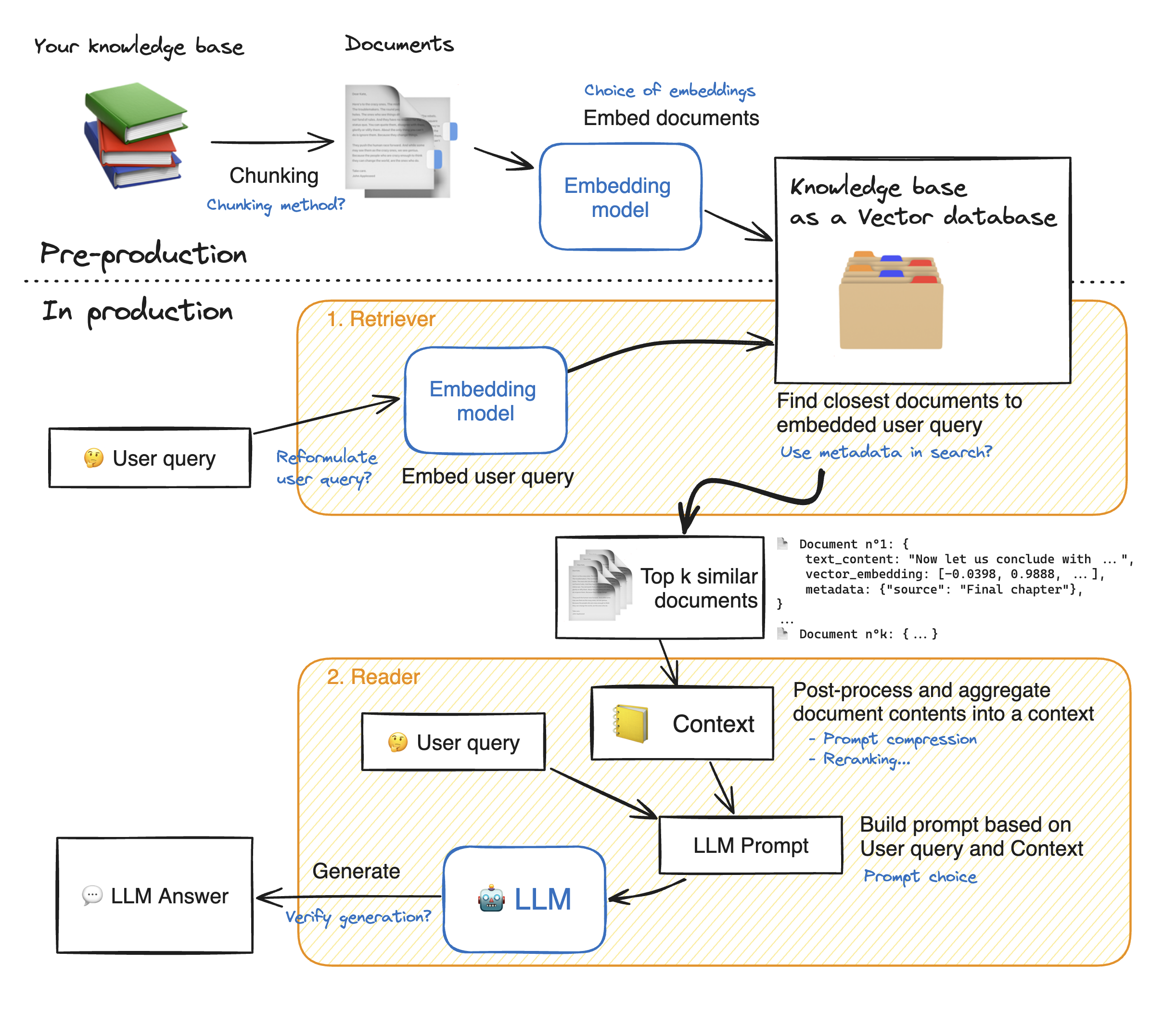
Rimelit Webアプリケーションのデモを作成する前に、RAGアプローチの詳細を説明して、それがどのように機能するかを理解しましょう。レトリバーは内部検索エンジンのように動作します。ユーザークエリを与えられた場合、外部データソースからいくつかの関連要素を返します。これがRAGシステムの主な手順です:
1-知識の各ドキュメントをチャンクに分割し、埋め込みを取得します。ドキュメントを埋め込むときは、特定の最大シーケンス長max_seq_lengthを受け入れるモデルを使用することに留意してください。
2-すべてのチャンクが埋め込まれたら、ベクトルデータベースに保存します。ユーザーがクエリを入力すると、以前に使用された同じモデルに埋め込まれます。その後、類似性検索は、ベクトルデータベースからTOP_Kの最も近いチャンクを返します。そのためには、2つの要素が必要です。1)emdeddings(Euclideanの距離、Cosinusの類似性、DOT製品)の間の距離を抑えるメトリックと2)最も近い要素(FacebookのFAISS)を見つけるための検索アルゴリズム。私たちの特定のモデルは、Cosinusの類似性とうまく機能します。
3-最後に、取得されたドキュメントの内容は「コンテキスト」に集約され、クエリとともに「プロンプト」に集約されます。その後、回答を生成するためにLLMに供給されます。
ぼろきれのステップの完璧な図の下:
LLMSで適切に正確に到達するには、各ハイパーパラメーターをよりよく理解して選択する必要があります。詳細を深める前に、LLMのデコードプロセスを思い出させましょう。私たちが知っているように、LLMは変圧器に依存しています。それぞれが2つの主要なブロックで構成されています。入力トークンを埋め込みに変換するエンコーダー、つまり埋め込みからトークンを生成しようとするデコーダー(エンコーダーの反対)です。デコードには、貪欲とサンプリングの2つの主なタイプがあります。貪欲なデコードを使用すると、モデルは、推論中に各ステップで最高の確率でトークンを選択するだけです。
対照的に、サンプリングデコードを使用すると、モデルは潜在的な出力トークンのサブセットを選択し、そのうちの1つをランダムに選択して出力テキストに追加します。これにより、より多くの変動が生まれ、LLMがより創造的になるのに役立ちます。ただし、デコーダーのサンプリングを選択すると、反応が誤っているリスクが高まります。
サンプリングデコードを選択するとき、モデルのパフォーマンスに影響を与える2つの追加のハイパーパラメーターがあります:TOP_KとTOP_P。
TOP_K :TOP_K HyperParameterは、 1〜100の範囲の整数です。最高の確率を持つKトークンを表します。背後にあるアイデアをより理解するために、例を見てみましょう。「私は友人に会いに行った」というこの文があり、次のトークンを予測したいと思います。3)都市の中心に3)一緒に食事をする3)町の反対側に次に、「in」、「to」、 "on"がそれぞれ次の確率を持っていると仮定します[0.23、0.12、0.30]。 TOP_K = 2では、最高の確率を持つ2つのトークンのみを選択します。次に、モデルはそれらの1つをランダムに選択します。
TOP_P : 0.0〜1.0の範囲の小数の機能です。このモデルは、累積確率でトークンのサブセットを選択しようとします。上記の例を考慮して、TOP_P = 0.55では、0.55に劣る累積確率を持つ唯一のトークンは「in」と「on」です。
温度:上記のTOP_KおよびTOP_Pハイパーパラメーターと同様の関数を実行します。範囲は0〜2です(創造性の最大値)。背後にあるアイデアは、出力トークンの確率分布を変更することです。温度値が低いとモデルは確率を増幅し、確率が高いトークンが出力である可能性がさらに高くなり、逆も同様です。予測可能な応答を生成する場合、低い値が使用されます。対照的に、値が高いと確率が収束します。それらは互いに近づきます。それらを使用して、LLMをより創造的にするようにプッシュします。
考慮すべきもう1つのパラメーターは、LLMを実行するために必要なメモリです。Nパラメーターと完全精度(FP32)を備えたモデルの場合、必要なメモリはN x 4バイトです。ただし、量子化を使用すると、(4バイト/新しい精度)で除算します。 FP16では、新しいメモリは4バイト/ 2バイトで除算されます。
リポジトリには、次のファイルとディレクトリが含まれています。
このセクションでは、Rimelitt WebAppのデモンストレーションを行います。ユーザーは質問をすることができ、チャットボットが回答します。
Dockerを使用してRreamlitアプリの展開を起動するには、次のコマンドを入力してください。
docker build -t streamlit。 :Docker画像を作成します
docker run -p 8501:8501 streamlit:画像に基づいてコンテナを起動する
アプリを表示するには、ユーザーはhttp://0.0.0.0:8501またはhttp:// localhost:8501を閲覧できます。
情報、フィードバック、または質問については、私に連絡してください


