LLM RAG Chatbot With LangChain
1.0.0
นักวิทยาศาสตร์ข้อมูล Anass Majji
ในโครงการนี้เราปรับใช้ LLM RAG chatbot กับ Langchain บนเว็บแอปพลิเคชัน Streamlit โดยใช้ CPU เท่านั้น
แบบจำลอง LLM มีจุดมุ่งหมายในการแยกข้อมูลที่เกี่ยวข้องจากเอกสารภายนอก ในกรณีของเราเราได้ใช้ LLAMA-2-7B เวอร์ชันเชิงปริมาณด้วยวิธีการหาปริมาณ GGML สามารถใช้กับโปรเซสเซอร์ CPU เท่านั้น
ตามเนื้อผ้า LLM ได้พึ่งพาเฉพาะและข้อมูลการฝึกอบรมที่โมเดลได้รับการฝึกอบรม อย่างไรก็ตามวิธีการนี้มีข้อ จำกัด ในแง่ของความรู้โดยเฉพาะอย่างยิ่งเมื่อจัดการกับชุดข้อมูลขนาดใหญ่ที่เกินข้อจำกัดความยาวโทเค็น เพื่อจัดการกับความท้าทายนี้ RAG (Generation Augmented Retrieval) แทรกแซงโดยเพิ่มประสิทธิภาพ LLM ด้วยแหล่งข้อมูลใหม่และภายนอก
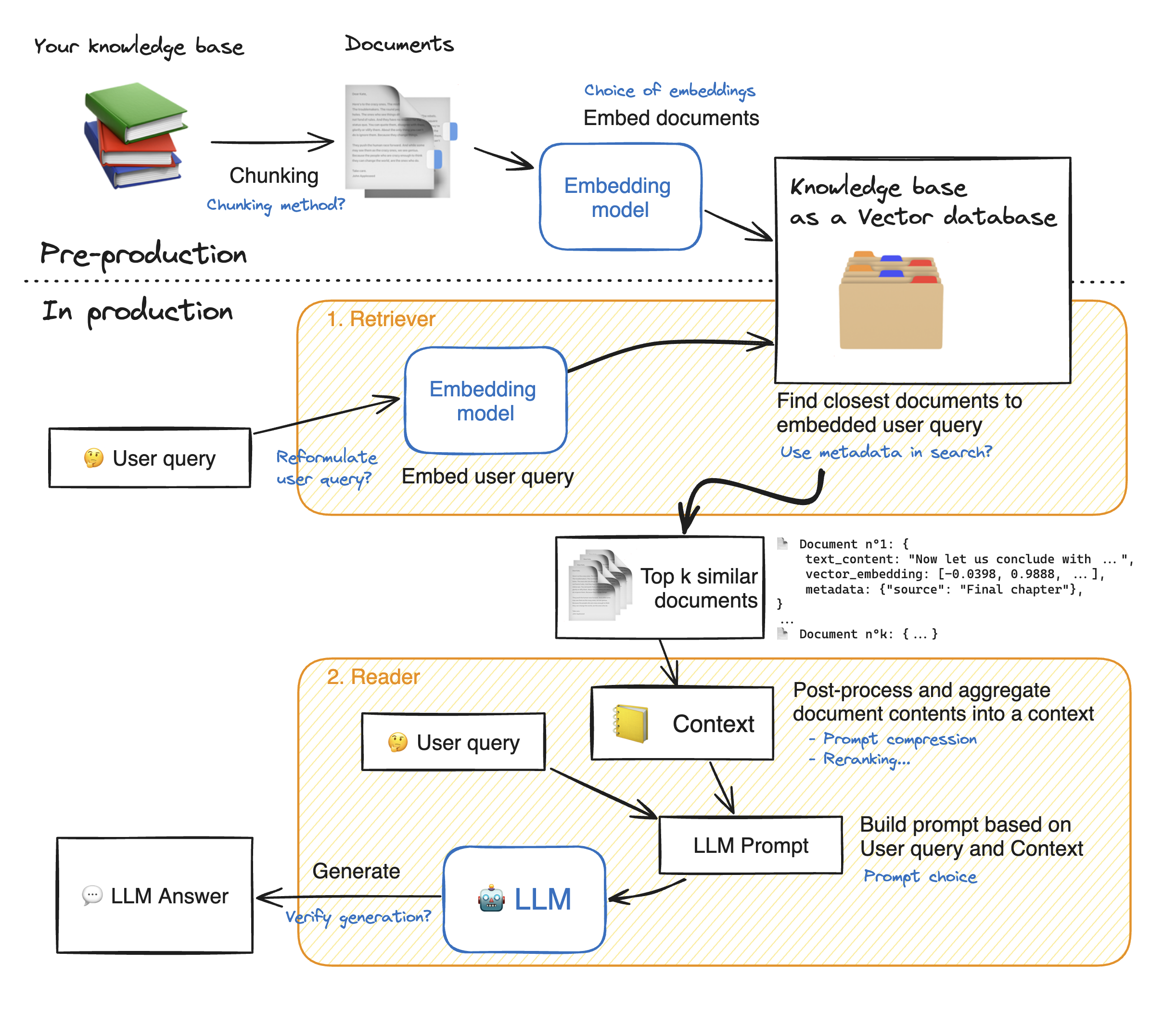
ก่อนที่จะทำการสาธิตเว็บแอปพลิเคชันแบบสตรีมให้เดินผ่านรายละเอียดของวิธี RAG เพื่อทำความเข้าใจวิธีการทำงาน Retriever ทำหน้าที่เหมือนเครื่องมือค้นหาภายใน: ด้วยการสืบค้นผู้ใช้จะส่งคืนองค์ประกอบที่เกี่ยวข้องสองสามอย่างจากแหล่งข้อมูลภายนอก นี่คือขั้นตอนหลักของระบบ RAG:
1 - แบ่งเอกสารแต่ละฉบับของความรู้ของเราเป็นชิ้นและรับการฝังตัวของพวกเขา: เราควรจำไว้ว่าเมื่อเอกสารการฝังตัวเราจะใช้แบบจำลองที่ยอมรับความยาวลำดับสูงสุด Max_seq_Length
2 - เมื่อชิ้นส่วนทั้งหมดถูกฝังเราเก็บไว้ในฐานข้อมูลเวกเตอร์ เมื่อผู้ใช้พิมพ์แบบสอบถามจะถูกฝังโดยรุ่นเดียวกันกับที่ใช้ก่อนหน้านี้การค้นหาที่คล้ายคลึงกันจะส่งคืนชิ้นส่วนที่ใกล้ที่สุด top_k จากฐานข้อมูลเวกเตอร์ ในการทำเช่นนั้นเราจำเป็นต้องมีสององค์ประกอบ: 1) ตัวชี้วัดเพื่อ mesure ระยะห่างระหว่าง Emdeddings (ระยะทางแบบยุคลิด, ความคล้ายคลึงกันของ Cosinus, ผลิตภัณฑ์ DOT) และ 2) อัลกอริทึมการค้นหาเพื่อค้นหาองค์ประกอบที่ใกล้เคียงที่สุด (Faiss ของ Facebook) โมเดลเฉพาะของเราทำงานได้ดีกับความคล้ายคลึงกันของ Cosinus
3 - ในที่สุดเนื้อหาของเอกสารที่ดึงมานั้นรวมเข้าด้วยกันใน "บริบท" ซึ่งรวมเข้ากับการสืบค้นลงใน "พรอมต์" จากนั้นก็ป้อน LLM เพื่อสร้างคำตอบ
ด้านล่างภาพประกอบที่สมบูรณ์แบบของขั้นตอนผ้าขี้ริ้ว:
เพื่อให้ได้ความแม่นยำที่ดีกับ LLMS เราจำเป็นต้องเข้าใจและเลือกพารามิเตอร์ไฮเปอร์แต่ละ ก่อนที่จะดำน้ำลึกลงไปในรายละเอียดเรามาเตือนกระบวนการถอดรหัสของ LLM อย่างที่เราทราบ LLMs พึ่งพาหม้อแปลงแต่ละอันประกอบด้วยสองกลุ่มหลัก: encoder ซึ่งแปลงโทเค็นอินพุตเป็น Embeddings คือค่าตัวเลขและ ตัวถอดรหัส ซึ่งพยายามสร้างโทเค็นจากการฝัง (ฝ่ายตรงข้ามของเข้ารหัส) มีการถอดรหัสหลักสองประเภท: โลภ และ การสุ่มตัวอย่าง ด้วยการถอดรหัสโลภโมเดลก็เลือกโทเค็นที่มีความน่าจะเป็นสูงสุดในแต่ละขั้นตอนในระหว่างการอนุมาน
ด้วยการถอดรหัสการสุ่มตัวอย่างในทางตรงกันข้ามโมเดลเลือกชุดย่อยของโทเค็นเอาต์พุตที่มีศักยภาพและเลือกแบบสุ่มหนึ่งในนั้นเพื่อเพิ่มลงในข้อความเอาต์พุต สิ่งนี้สร้างความแปรปรวนมากขึ้นและช่วยให้ LLM มีความคิดสร้างสรรค์มากขึ้น อย่างไรก็ตามการเลือกใช้ตัวถอดรหัสการสุ่มตัวอย่างเพิ่มความเสี่ยงของการตอบสนองที่ไม่ถูกต้อง
เมื่อเลือกสำหรับการถอดรหัสการสุ่มตัวอย่างเรามีไฮเปอร์พารามิเตอร์เพิ่มเติมสองตัวซึ่งส่งผลกระทบต่อประสิทธิภาพของโมเดล: TOP_K และ TOP_P
top_k : hyperparameter top_k เป็นจำนวนเต็มที่อยู่ในช่วงตั้งแต่ 1 ถึง 100 มันแสดงถึงโทเค็น K ที่มีความน่าจะเป็นสูงสุด เพื่อให้เข้าใจถึงความคิดที่อยู่เบื้องหลังมากขึ้นลองมาเป็นตัวอย่าง: เรามีประโยคนี้ "ฉันไปพบเพื่อน" และเราต้องการทำนายโทเค็นถัดไปเรามี 3 positive 1) ในใจกลางเมือง 2) เพื่อกินด้วยกัน 3) ในอีกด้านหนึ่งของเมือง ตอนนี้สมมติว่า "in", "ถึง" และ "on" มีความน่าจะเป็นต่อไปนี้ตามลำดับ [0.23, 0.12, 0.30] ด้วย top_k = 2 เราจะเลือกเพียงสองโทเค็นที่มีความน่าจะเป็นสูงสุด: "in" และ "on" ในกรณีของเรา จากนั้นโมเดลจะเลือกแบบสุ่มอย่างใดอย่างหนึ่ง
TOP_P : เป็นคุณสมบัติทศนิยมที่อยู่ในช่วงตั้งแต่ 0.0 ถึง 1.0 โมเดลพยายามเลือกชุดย่อยของโทเค็นที่มีความน่าจะเป็นแบบสะสมเท่ากับค่า top_p เมื่อพิจารณาถึงตัวอย่างข้างต้นด้วย top_p = 0.55 โทเค็นเดียวที่มีความน่าจะเป็นสะสมที่ด้อยกว่า 0.55 คือ "ใน" และ "on"
อุณหภูมิ : ทำหน้าที่คล้ายกันกับ top_k และ top_p hyperparameters มันมีตั้งแต่ 0 ถึง 2 (สูงสุดของความคิดสร้างสรรค์) แนวคิดที่อยู่เบื้องหลังคือการเปลี่ยนการกระจายความน่าจะเป็นของโทเค็นเอาต์พุต ด้วยค่าอุณหภูมิที่ต่ำกว่าแบบจำลองจะขยายความน่าจะเป็นหมายถึงโทเค็นที่มีความน่าจะเป็นสูงกว่าจะยิ่งมีแนวโน้มที่จะส่งออกและในทางกลับกัน ค่าที่ต่ำกว่าจะใช้เมื่อเราต้องการสร้างการตอบสนองที่คาดเดาได้ ในทางตรงกันข้ามค่าที่สูงขึ้นทำให้เกิดการลู่เข้าของความน่าจะเป็น: พวกเขาใกล้ชิดกัน การใช้พวกเขาผลักดัน LLM ให้สร้างสรรค์มากขึ้น
พารามิเตอร์อีกประการหนึ่งที่เราควรคำนึงถึงคือหน่วยความจำที่จำเป็นในการเรียกใช้ LLM: สำหรับโมเดลที่มีพารามิเตอร์ N และความแม่นยำเต็มรูปแบบ (FP32) หน่วยความจำที่จำเป็นคือ N X 4BYTES อย่างไรก็ตามเมื่อเราใช้การวัดปริมาณเราจะแบ่งออกเป็น (4 ไบต์/ ความแม่นยำใหม่) ด้วย FP16 หน่วยความจำใหม่จะถูกหารด้วย 4 ไบต์/ 2 ไบต์
ที่เก็บมีไฟล์และไดเรกทอรีต่อไปนี้:
ในส่วนนี้เราจะทำการสาธิต The Streamplit Webapp ผู้ใช้สามารถถามคำถามใด ๆ และ chatbot จะตอบ
ในการเปิดการปรับใช้แอพ StreamLit ด้วย Docker ให้พิมพ์คำสั่งต่อไปนี้:
Docker build -t streamlit : เพื่อสร้างภาพนักเทียบท่า
Docker Run -P 8501: 8501 Streamlit: เพื่อเปิดคอนเทนเนอร์ตามรูปภาพของเรา
ในการดูแอพของเราผู้ใช้สามารถเรียกดู http://0.0.0.0:8501 หรือ http: // localhost: 8501
สำหรับข้อมูลข้อเสนอแนะหรือคำถามใด ๆ โปรดติดต่อฉัน


