LLM RAG Chatbot With LangChain
1.0.0
Datenwissenschaftler | Anass Majji
In diesem Projekt stellen wir mit Langchain einen LLM -RAG -Chatbot in einer streamliten Webanwendung mit nur CPU ein.
Das LLM -Modell zielt darauf ab, relevante Informationen aus externen Dokumenten zu extrahieren. In unserem Fall haben wir die quantisierte Version von LLAMA-2-7B mit GGML- Quantisierungsansatz verwendet. Sie kann nur mit CPU- Prozessoren verwendet werden.
Traditionell hat sich die LLM nur auf die Eingabeaufforderung und die Trainingsdaten verlassen, auf denen das Modell geschult wurde. Dieser Ansatz stellte jedoch Einschränkungen hinsichtlich des Wissens vor, insbesondere wenn es sich um große Datensätze handelt, die die Einschränkungen der Token -Länge überschreiten. Um diese Herausforderung zu befriedigen, greift Rag (Abruf Augmented Generation) ein, indem er das LLM mit neuen und externen Datenquellen anreichert.
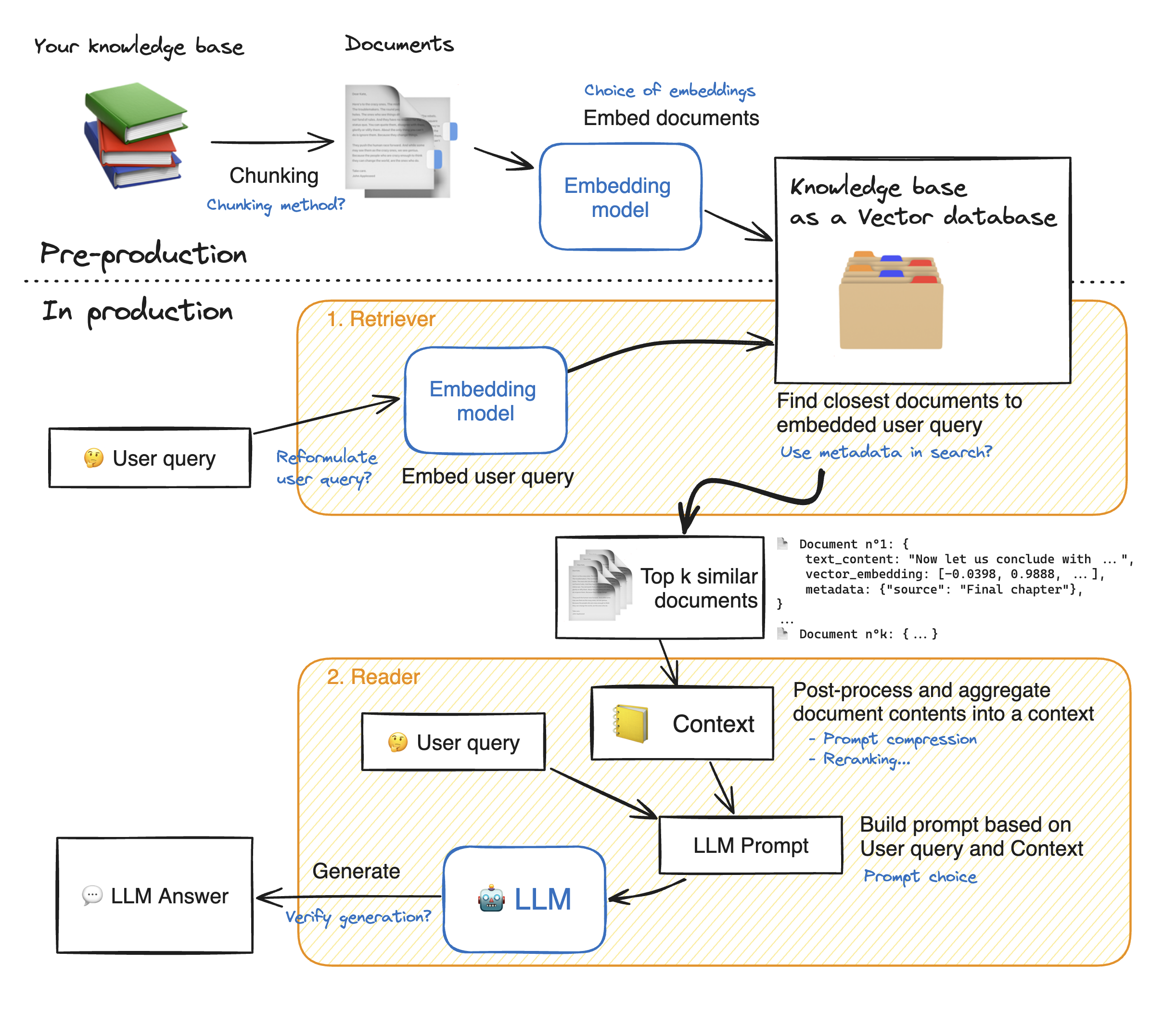
Bevor wir eine Demo der streamlosen Webanwendung machen, gehen wir die Details des Lag -Ansatzes durch, um zu verstehen, wie sie funktioniert. Der Retriever wirkt wie eine interne Suchmaschine: Bei einer Benutzerabfrage wird einige relevante Elemente aus den externen Datenquellen zurückgegeben. Hier sind die Hauptschritte des Lappensystems:
1 - Teilen Sie jedes Dokument unseres Wissens in Stücke auf und erhalten Sie ihre Einbettungen: Wir sollten bedenken, dass wir beim Einbettungsdokumenten ein Modell verwenden, das eine bestimmte maximale Sequenzlänge max_seq_length akzeptiert.
2 - Sobald alle Stücke eingebettet sind, speichern wir sie in einer Vektor -Datenbank. Wenn der Benutzer eine Abfrage eingibt, wird sie durch das gleiche Modell eingebettet, dann gibt eine Ähnlichkeitssuche die Top_k -Top -Stücke aus der Vektor -Datenbank zurück. Dazu benötigen wir zwei Elemente: 1) eine Metrik, um den Abstand zwischen EMDDDings (euklidischer Abstand, Cosinus -Ähnlichkeit, DOT -Produkt) und 2) einen Suchalgorithmus zu finden, um die nächsten Elemente (Facebooks FAISS) zu finden. Unser spezielles Modell funktioniert gut zur Ähnlichkeit von Cosinus.
3 - Schließlich wird der Inhalt der abgerufenen Dokumente zusammen in den "Kontext" zusammengefasst, der auch mit der Abfrage in die "Eingabeaufforderung" zusammengefasst ist. Es wird dann an die LLM weitergeleitet, um Antworten zu generieren.
Unterhalb einer perfekten Abbildung der Rag -Schritte:
Um eine gute Genauigkeit mit den LLMs zu erreichen, müssen wir jeden Hyperparameter besser verstehen und auswählen. Bevor wir uns mit den Details eintauchen, erinnern wir den Dekodierungsprozess des LLM. Wie wir wissen, stützen sich LLMs auf Transformatoren, jeweils besteht mit zwei Hauptblöcken: Encoder , die die Eingangs -Token in Einbettungen umwandeln, dh numerische Werte und Decoder , die versucht, Token aus Einbettungen (der Opposit des Encoders) zu erzeugen. Es gibt zwei Haupttypen von Dekodierung: gierig und probiert . Bei gieriger Dekodierung wählt das Modell das Token einfach mit der höchsten Wahrscheinlichkeit bei jedem Schritt während der Inferenz aus.
Im Gegensatz dazu wählt das Modell eine Teilmenge potenzieller Ausgangs -Token aus und wählt im Gegensatz dazu zufällig einen von ihnen aus, um den Ausgangstext hinzuzufügen. Dies schafft mehr Variabilität und hilft dem LLM, kreativer zu sein. Die Entscheidung für die Probenahme -Decoder erhöht jedoch das Risiko falscher Antworten.
Bei der Entscheidung für die Probenahmedekodierung haben wir zwei zusätzliche Hyperparameter, die die Leistung des Modells beeinflussen: top_k und top_p.
TOP_K : Der TOP_K -Hyperparameter ist eine Ganzzahl, die von 1 bis 100 liegt. Es repräsentiert die K -Token mit den höchsten Wahrscheinlichkeiten. Um die Idee dahinter besser zu verstehen, nehmen wir ein Beispiel: Wir haben diesen Satz "Ich ging zu einem Freund" und wir wollen das nächste Token vorhersagen, wir haben 3 Möglichkeiten 1) im Zentrum der Stadt 2) zusammen zu essen 3) auf der anderen Seite der Stadt. Nehmen Sie nun an, dass "in", ", zu" und "on" die folgenden Wahrscheinlichkeiten haben [0,23, 0,12, 0,30]. Mit top_k = 2 wählen wir nur zwei Token mit den höchsten Wahrscheinlichkeiten aus: "in" und "on" in unserem Fall. Dann wählt das Modell zufällig einen von ihnen.
TOP_P : Ist ein Dezimalmerkmal, das zwischen 0,0 und 1,0 liegt. Das Modell versucht, eine Teilmenge von Token mit ihren kumulativen Wahrscheinlichkeiten zu wählen, die dem Wert top_p entsprechen. In Anbetracht des obigen Beispiels mit einem TOP_P = 0,55 sind die einzigen Token mit ihren kumulativen Wahrscheinlichkeiten, die 0,55 unter "in" und "on" sind.
Temperatur : führt eine ähnliche Funktion wie die oben genannten Top_k- und top_p -Hyperparameter aus. Es reicht von 0 bis 2 (Maximum der Kreativität). Die Idee dahinter ist, die Wahrscheinlichkeitsverteilung der Ausgangs -Token zu ändern. Mit einem niedrigeren Temperaturwert verstärkt das Modell die Wahrscheinlichkeiten, bedeutet, dass Token mit höheren Wahrscheinlichkeiten noch höher ausgegeben werden und umgekehrt. Die niedrigeren Werte werden verwendet, wenn wir vorhersehbare Antworten generieren möchten. Im Gegensatz dazu führen höhere Werte eine Konvergenz der Wahrscheinlichkeiten: Sie kommen sich nahe beieinander. Mit der Verwendung der LLM werden kreativer.
Ein weiterer Paramater, den wir berücksichtigen sollten, ist der Speicher, der zum Ausführen des LLM erforderlich ist: Für ein Modell mit N -Parameter und eine vollständige Genauigkeit (FP32) ist das benötigte Speicher N x 4Bytes. Wenn wir die Quantisierung jedoch verwenden, teilen wir uns jedoch durch (4 Bytes/ neue Präzision). Mit FP16 wird das neue Speicher durch 4 Bytes/ 2 Bytes geteilt.
Das Repository enthält die folgenden Dateien und Verzeichnisse:
In diesem Abschnitt werden wir die nachweisliche WebApp demonstrieren. Der Benutzer kann jede Frage stellen und der Chatbot wird beantwortet.
Geben Sie die folgenden Befehle ein, um die Bereitstellung der Streamlit -App mit Docker zu starten:
Docker Build -t -Strom. : Um das Docker -Bild zu erstellen
Docker Run -P 8501: 8501 Streamlit: Um den Container basierend auf unserem Bild zu starten
Um unsere App anzuzeigen, können Benutzer nach http://0.0.0.0:8501 oder http: // localhost: 8501 suchen
Für Informationen, Feedback oder Fragen kontaktieren Sie mich bitte


