LLM RAG Chatbot With LangChain
1.0.0
데이터 과학자 | Anass Majji
이 프로젝트에서는 CPU 만 사용하여 Llm Rag Chatbot을 Langchain 과 함께 Langchain 과 함께 배포합니다.
LLM 모델은 외부 문서에서 관련 정보를 추출하는 것을 목표로합니다. 우리의 경우, 우리는 GGML 양자화 접근법과 함께 LLAMA-2-7B 의 양자화 된 버전을 사용했으며 CPU 프로세서 만 사용할 수 있습니다.
전통적으로 LLM은 프롬프트와 모델이 훈련 된 교육 데이터에만 의존했습니다. 그러나이 접근법은 특히 토큰 길이 제약을 초과하는 큰 데이터 세트를 처리 할 때 지식 측면에서 한계를 제기했습니다. 이 도전을 해결하기 위해 Rag (검색 증강 생성)는 LLM을 신규 및 외부 데이터 소스로 풍부하게함으로써 개입합니다.
Streamlit Web Application의 데모를 만들기 전에 Rag 접근 방식의 세부 사항을 살펴보고 작동 방식을 이해해 보겠습니다. 리트리버는 내부 검색 엔진처럼 작동합니다. 사용자 쿼리가 주어지면 외부 데이터 소스에서 몇 가지 관련 요소를 반환합니다. 래그 시스템의 주요 단계는 다음과 같습니다.
1- 지식의 각 문서를 덩어리로 나누고 임베딩을 얻습니다. 우리는 문서를 삽입 할 때 특정 최대 시퀀스 길이 max_seq_length를 수용하는 모델을 사용한다는 점을 명심해야합니다.
2- 모든 청크가 포함되면 벡터 데이터베이스에 저장합니다. 사용자가 쿼리를 입력하면 이전에 사용한 동일한 모델에 포함 된 다음 유사성 검색은 벡터 데이터베이스에서 TOP_K 가장 가까운 청크를 반환합니다. 그렇게하려면 1) Emdeddings (유클리드 거리, 코시 누스 유사성, 도트 제품) 사이의 거리를 연락하는 메트릭 및 2) 가장 가까운 요소 (Facebook의 FAISS)를 찾기위한 검색 알고리즘. 우리의 특정 모델은 Cosinus 유사성과 잘 어울립니다.
3- 마지막으로 검색된 문서의 내용은 "컨텍스트"로 함께 집계되며 쿼리와 함께 "프롬프트"로 집계됩니다. 그런 다음 답을 생성하기 위해 LLM에 공급됩니다.
헝겊 단계의 완벽한 그림 아래 :
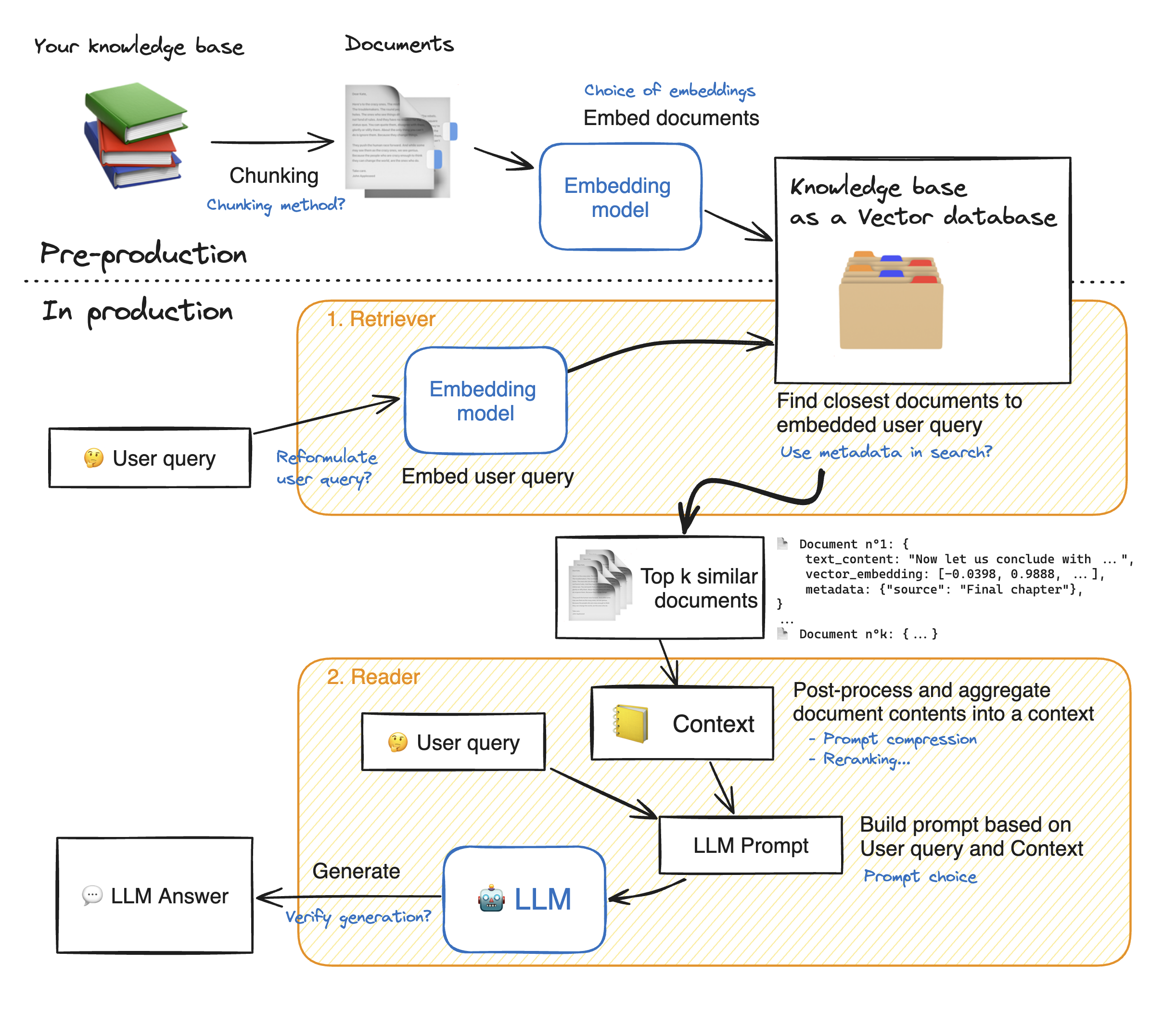
LLMS로 좋은 정확성에 도달하려면 각 과복 동물을 더 잘 이해하고 선택해야합니다. 세부 사항을 심화시키기 전에 LLM의 디코딩 프로세스를 상기시켜 드리겠습니다. 아시 다시피, LLM은 변압기에 의존하며, 각각은 두 개의 주요 블록으로 구성됩니다. 입력 토큰을 임베딩으로 변환하는 인코더 (즉, 흡착 자와의 반대)로부터 토큰을 생성하려고 시도합니다. 디코딩에는 두 가지 주요 유형이 있습니다 : 욕심 과 샘플링 . 탐욕스러운 디코딩을 사용하면이 모델은 추론 중 각 단계에서 가장 높은 확률로 토큰을 선택합니다.
대조적으로 샘플링 디코딩을 통해 모델은 잠재적 출력 토큰의 하위 집합을 선택하고 중 하나를 선택하여 출력 텍스트에 추가합니다. 이것은 더 많은 변동성을 만들고 LLM이 더 창의적 이도록 도와줍니다. 그러나 샘플링 디코더를 선택하면 잘못된 응답의 위험이 높아집니다.
샘플링 디코딩을 선택할 때 모델의 성능에 영향을 미치는 두 개의 추가 하이퍼 파라미터가 있습니다 : TOP_K 및 TOP_P.
TOP_K : TOP_K 하이퍼 파라미터는 1 에서 100 사이의 정수입니다. 확률이 가장 높은 k 토큰을 나타냅니다. 뒤에있는 아이디어를 더 이해하기 위해 예를 들어 보자. 우리는이 문장을 "친구를 만나러 갔다"고 다음 발표를 예측하고 싶다. 이제 "in", "to"및 "on"은 각각 다음 확률을 가지고 있다고 가정하자. [0.23, 0.12, 0.30]. Top_k = 2를 사용하면 우리는 가장 높은 확률을 가진 두 개의 토큰 만 선택할 것입니다 : "in"및 "on". 그런 다음 모델은 그중 하나를 무작위로 선택합니다.
TOP_P : 0.0 에서 1.0 사이의 소수점 기능입니다. 이 모델은 누적 확률을 갖는 토큰의 서브 세트를 TOP_P 값과 같다. 위의 예를 고려할 때, top_p = 0.55 인 유일한 누적 확률을 가진 유일한 토큰은 0.55보다 열등한 토큰은 "in"및 "on"입니다.
온도 : 위의 TOP_K 및 TOP_P 하이퍼 파라미터와 유사한 기능을 수행합니다. 0 에서 2 까지 (최대 창의성) 범위입니다. 뒤에 아이디어는 출력 토큰의 확률 분포를 변경하는 것입니다. 온도 값이 낮 으면 모델은 확률을 증폭시키고 확률이 높은 토큰이 출력 가능성이 훨씬 높아지고 그 반대로 그 반대가됩니다. 예측 가능한 응답을 생성하려는 경우 더 낮은 값이 사용됩니다. 대조적으로, 높은 값은 확률의 수렴을 유발합니다. 서로 가까워집니다. 그것들을 사용하여 LLM을 더 창의적으로 밀어 넣습니다.
우리가 고려해야 할 또 다른 매개 변수는 LLM을 실행하는 데 필요한 메모리입니다. n 매개 변수가있는 모델과 완전 정밀도 (FP32)의 경우 필요한 메모리는 n x 4Bytes입니다. 그러나 양자화를 사용하면 (4 바이트/ 새로운 정밀도)로 나눕니다. FP16의 경우 새 메모리는 4 바이트/ 2 바이트로 나뉩니다.
저장소에는 다음 파일 및 디렉토리가 포함되어 있습니다.
이 섹션에서는 Streamlit WebApp을 시연 할 것입니다. 사용자는 질문을 할 수 있으며 챗봇이 대답합니다.
Docker와 함께 Streamlit 앱의 배포를 시작하려면 다음 명령을 입력하십시오.
Docker Build -t leamlit. : Docker 이미지를 작성합니다
Docker Run -P 8501 : 8501 간소 : 이미지를 기반으로 컨테이너를 시작합니다.
앱을 보려면 사용자는 http://0.0.0:8501 또는 http : // localhost : 8501로 탐색 할 수 있습니다.
모든 정보, 피드백 또는 질문은 저에게 연락하십시오


