gpt all local
1.0.0
該項目是使用大型語言模型(LLM)從私人數據中檢索信息,在本地運行所有部分(包括模型)的學習練習。目的是在計算機上運行LLM,以在計算機上的一組文件上提出問題。這些文件可以是任何類型的文檔,例如PDF,Word或文本文件。
這種結合LLM和私人數據的方法稱為檢索增強的生成(RAG)。它是在本文中引入的。
信用額度應得的信用:我基於原始Privategpt(他們稱之為原始版本)。我重新完成了這些作品以了解它們的工作方式。在“來源”部分中查看更多內容。
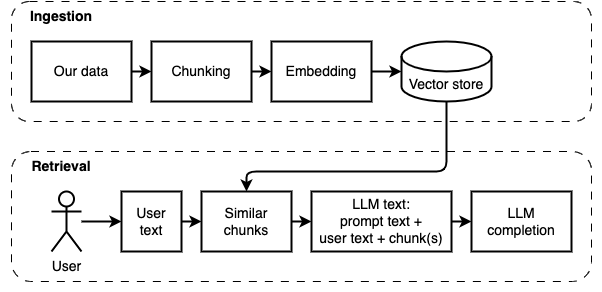
我們要實現的目標:給定計算機上的一組文件(a),我們希望在該計算機上運行的大型語言模型(b)在它們上回答問題(c)。
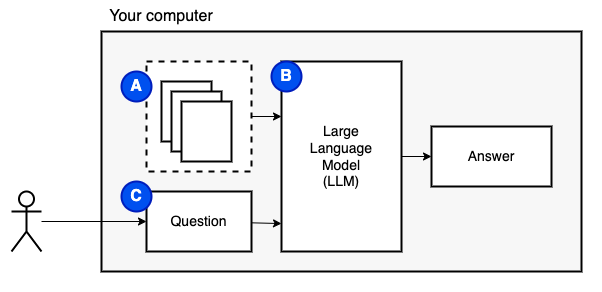
但是,我們無法將文件直接饋送到模型。大型語言模型(LLMS)具有上下文窗口,該窗口限制了我們可以輸入的信息(它們的工作記憶)。為了克服該限制,我們將文件分為較小的零件,稱為塊,僅將相關的文件饋送到模型(D)中。
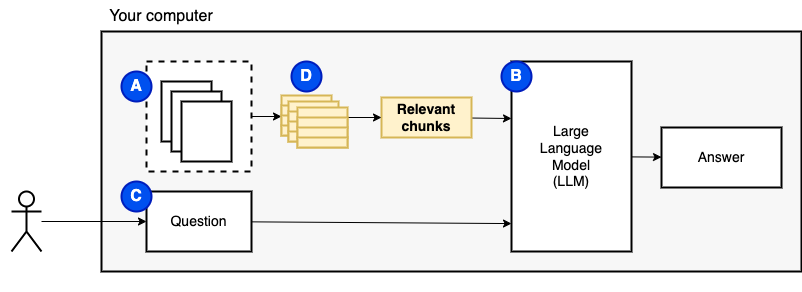
但是,問題變成了“我們如何找到相關的塊?” 。我們使用相似性搜索(e)來匹配問題和塊。相似性搜索反過來需要向量嵌入(F),這是用編碼語義關係的向量的單詞表示(從技術上講,密集的向量嵌入,而不是將其與稀疏的向量表示(例如詞袋和tf-idf)混淆)。一旦有了相關的塊,我們就將它們與問題結合在一起,以創建一個提示(g),該提示(g)指示LLM回答問題。
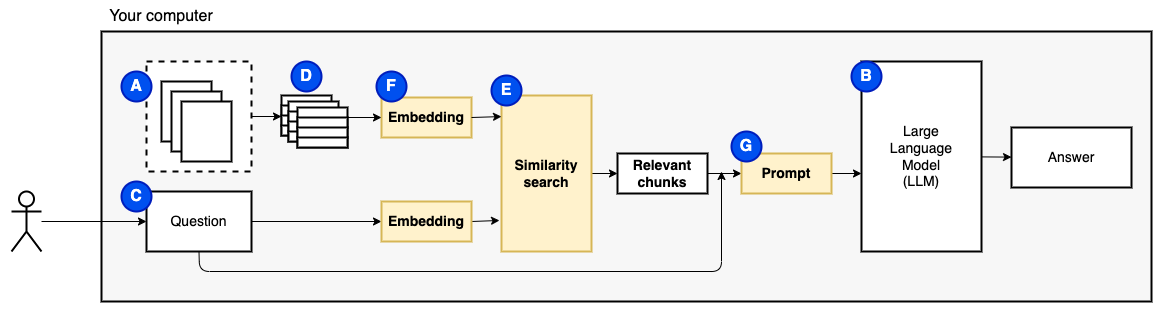
我們需要最後一塊:持續存儲。為塊創建嵌入需要時間。我們不想每次問一個問題。因此,我們需要將嵌入和原始文本(塊)保存在矢量存儲(或數據庫)(h)中。矢量商店可以大大生長,因為它存儲了原始文本塊及其矢量嵌入。我們使用矢量索引(i)有效地找到相關的塊。
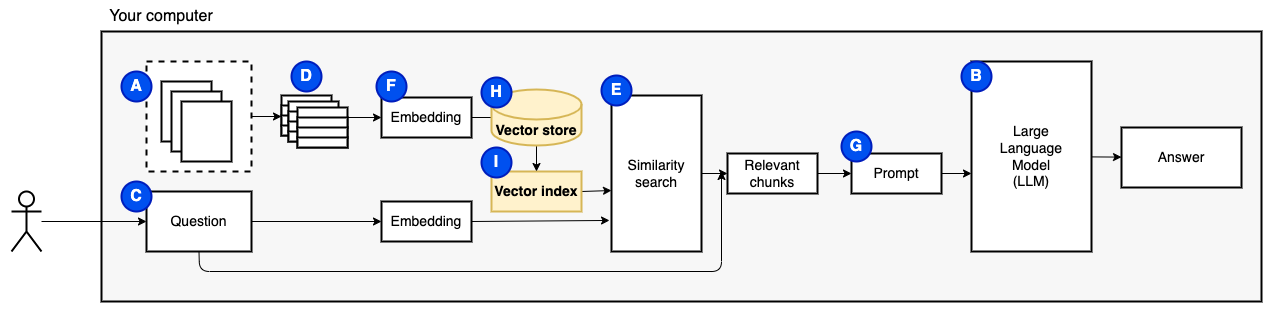
現在我們有了我們需要的所有作品。
我們可以將實現分為兩個部分:攝入和檢索數據。
以下圖中說明了這兩個步驟。
如果您還沒有這樣做,請準備環境。如果您已經準備好環境,請用source venv/bin/activate激活它。
有兩種使用此項目的方法:
--verbose標誌)。data文件夾中。python main.py ingest以將文件攝入矢量存儲。python main.py retrieve以從矢量存儲中檢索數據。這將提示您提出問題。使用--verbose標誌獲取有關該程序在幕後所做的事情的更多詳細信息。
要重新啟動數據,請刪除vector_store文件夾並再次運行python main.py ingest 。
運行streamlit run app.py它將在瀏覽器窗口中打開應用程序。
該命令可能會失敗,第一次運行它。 Python環境與Pyenv一起工作的地方有一個小故障。如果簡化顯示“無法導入模塊消息”,請停用Python環境,然後deactivate其再次激活,並使用source venv/bin/activate激活,然後運行streamlit run app.py
如果您還沒有這樣做,請準備環境。如果您已經準備好環境,請用source venv/bin/activate激活它。
命令: python main.py ingest [--verbose]
此階段的目的是使數據可搜索。但是,用戶的問題和數據內容可能不完全匹配。因此,我們不能使用簡單的搜索引擎。我們需要執行矢量嵌入支持的相似性搜索。向量嵌入是此階段最重要的部分。
攝入數據具有以下步驟:
未來的改進:
NLTKTextSplitter或SpacyTextSplitter )是否會改善答案。 如果您還沒有這樣做,請準備環境。如果您已經準備好環境,請用source venv/bin/activate激活它。
命令: python main.py retrieve [--verbose]
此階段的目的是從本地數據中檢索信息。我們通過獲取矢量商店中最相關的塊並將其與用戶的問題和提示相結合來做到這一點。該提示指示語言模型(LLM)回答問題。
檢索數據具有以下步驟:
未來的改進:
我們必須做出一些妥協才能使其在合理的時間內在本地機器上運行。
大多數攝入/檢索代碼基於原始私人法,他們現在稱為原始代碼。
有什麼不同:
pathlib而不是os.path ,並且具有正確的日誌記錄代替打印語句。--verbose標誌查看詳細信息。requirements.txt 。有關在此項目開發期間收集的更多註釋,請參見此文件。
這是一個一次性步驟。如果您已經這樣做了,只需使用source venv/bin/activate激活虛擬環境。
運行以下命令以創建虛擬環境並安裝所需的軟件包。
python3 -m venv venv
source venv/bin/activate
pip install --upgrade pip
pip install -r requirements.txtunstructured中的PDF解析器是實際解析器軟件包頂部的一層。在“安裝以下系統依賴項”子彈下,按照unstructured讀數中的說明進行操作。需要流行式包裝和Tesseract軟件包(忽略其他軟件包)。
我建議從在CPU上運行的小型型號開始。 GPT4All在這裡有模型列表。我用Mistral-7b-Openorca Q4進行了測試。它需要8 GB的RAM運行。請注意,某些模型具有限制性許可。在商業項目中使用許可之前,請先檢查許可證。
models的文件夾。models文件夾。

