gpt all local
1.0.0
هذا المشروع هو تمرين تعليمي حول استخدام نماذج اللغة الكبيرة (LLMS) لاسترداد المعلومات من البيانات الخاصة ، وتشغيل جميع القطع (بما في ذلك النموذج) محليًا. الهدف هو تشغيل LLM على جهاز الكمبيوتر الخاص بك لطرح أسئلة على مجموعة من الملفات أيضًا على جهاز الكمبيوتر الخاص بك. يمكن أن تكون الملفات أي نوع من المستندات ، مثل ملفات PDF أو Word أو Text Files.
تُعرف طريقة الجمع بين LLMs والبيانات الخاصة باسم الجيل المتمثل في الاسترجاع (RAG). تم تقديمه في هذه الورقة.
الائتمان عند مستحقه: لقد استندت إلى هذا المشروع على الخصوصية الأصلية (ما يسمونه الآن النسخة البدائية ). لقد قمت بإعداد القطع لفهم كيفية عملها. انظر المزيد في قسم المصادر.
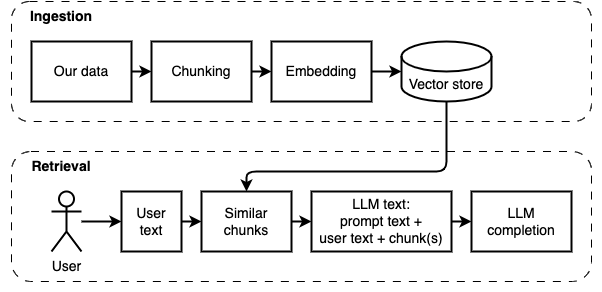
ما نحاول تحقيقه: بالنظر إلى مجموعة من الملفات على جهاز كمبيوتر (أ) ، نريد نموذج لغة كبير (ب) يعمل على هذا الكمبيوتر للإجابة على الأسئلة (ج) عليها.
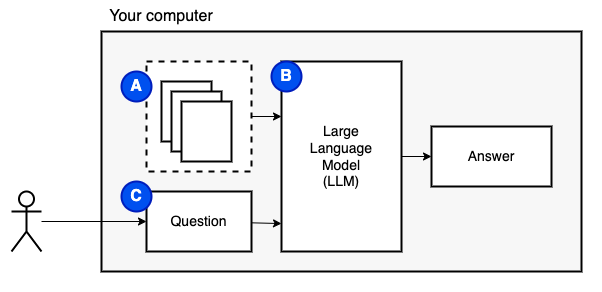
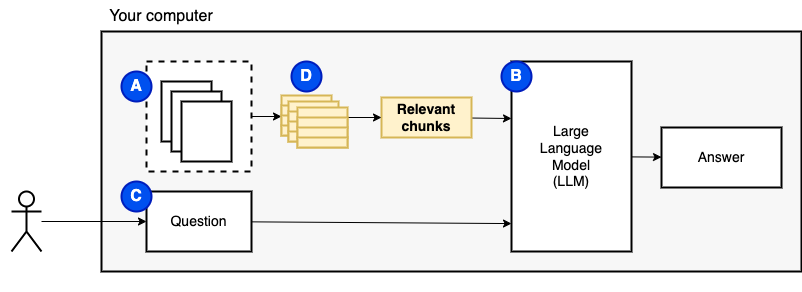
ومع ذلك ، لا يمكننا إطعام الملفات مباشرة إلى النموذج. تحتوي نماذج اللغة الكبيرة (LLMS) على نافذة سياق يحد من مقدار المعلومات التي يمكننا إطعامها (ذاكرتها العاملة). للتغلب على هذا القيد ، نقوم بتقسيم الملفات إلى قطع أصغر ، تسمى القطع ، ونغذي فقط تلك ذات الصلة بالنموذج (D).
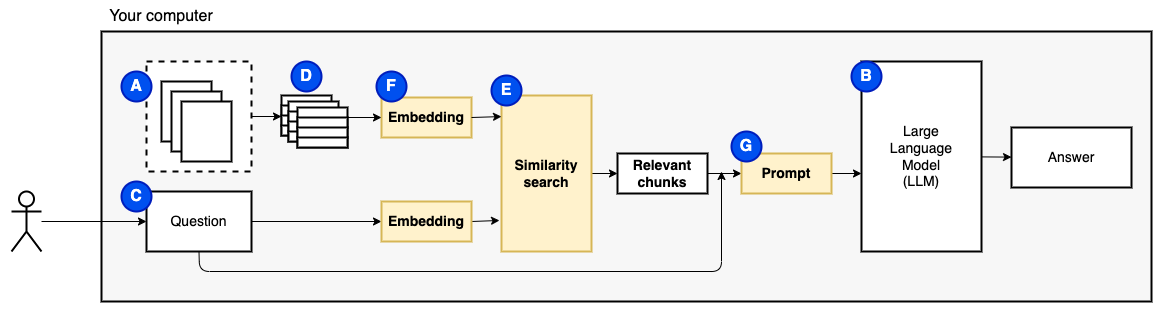
ولكن بعد ذلك ، يصبح السؤال "كيف نجد القطع ذات الصلة؟" . نستخدم البحث عن التشابه (E) لمطابقة السؤال والقطع. يتطلب البحث عن التشابه ، بدوره ، تضمينات متجه (F) ، وهو تمثيل للكلمات ذات المتجهات التي تشفر العلاقات الدلالية (من الناحية الفنية ، تضمّن المتجه الكثيف ، وليس الخلط بينه وبين تمثيلات المتجهات المتفرقة مثل حقيبة الكلمات و TF-IDF). بمجرد أن يكون لدينا القطع ذات الصلة ، فإننا نجمعها مع السؤال لإنشاء موجه (ز) يرشد LLM للإجابة على السؤال.
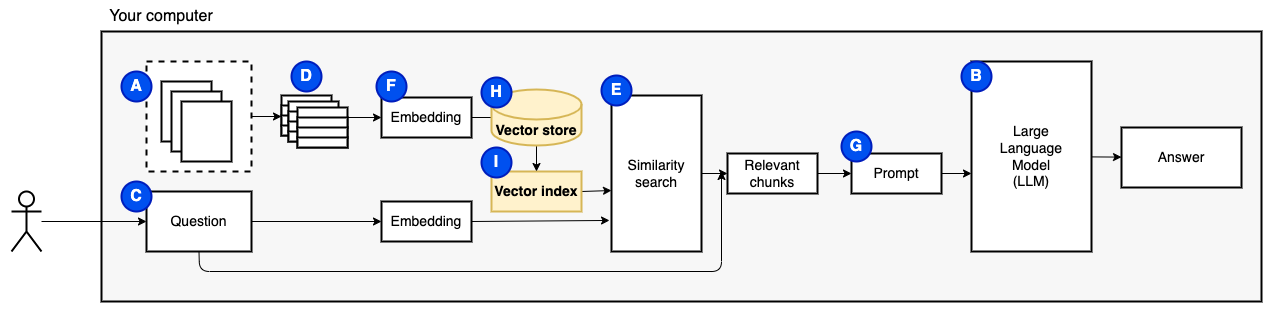
نحن بحاجة إلى قطعة أخيرة: التخزين المستمر. إنشاء التضمينات للقطع يستغرق وقتًا. لا نريد أن نفعل ذلك في كل مرة نطرح فيها سؤالاً. لذلك ، نحتاج إلى حفظ التضمينات والنص الأصلي (القطع) في متجر متجه (أو قاعدة بيانات) (H). يمكن أن ينمو متجر Vector بشكل كبير لأنه يخزن قطع النص الأصلية وتضمينات المتجهات. نستخدم فهرس المتجه (1) للعثور على القطع ذات الصلة بكفاءة.
الآن لدينا كل القطع التي نحتاجها.
يمكننا تقسيم التنفيذ إلى جزأين: تناول البيانات واستردادها.
يتم توضيح هاتين الخطوتين في الرسم البياني التالي.
إذا لم تكن قد فعلت ذلك بعد ، فقم بإعداد البيئة. إذا كنت قد قمت بالفعل بإعداد البيئة ، فقم بتنشيطها باستخدام source venv/bin/activate .
هناك طريقتان لاستخدام هذا المشروع:
--verbose أدناه).data .python main.py ingest الملفات في متجر Vector.python main.py retrieve لاسترداد البيانات من متجر المتجهات. سوف يطالبك على سؤال. استخدم علامة --verbose للحصول على مزيد من التفاصيل حول ما يفعله البرنامج وراء الكواليس.
لإعادة تأجيل البيانات ، قم بحذف مجلد vector_store وتشغيل python main.py ingest مرة أخرى.
قم بتشغيل streamlit run app.py سيفتح التطبيق في نافذة المتصفح.
قد يفشل هذا الأمر في أول قيام بتشغيله. هناك خلل في مكان ما في كيفية عمل بيئة Python مع Pyenv. إذا تُظهر SPERAMELIT "لا يمكن استيراد رسالة الوحدة النمطية" ، فقم بإلغاء تنشيط بيئة Python مع deactivate ، وتفعيلها مرة أخرى باستخدام source venv/bin/activate ، streamlit run app.py
إذا لم تكن قد فعلت ذلك بعد ، فقم بإعداد البيئة. إذا كنت قد قمت بالفعل بإعداد البيئة ، فقم بتنشيطها باستخدام source venv/bin/activate .
الأمر: python main.py ingest [--verbose]
الهدف من هذه المرحلة هو جعل البيانات قابلة للبحث. ومع ذلك ، قد لا يتطابق سؤال المستخدم ومحتويات البيانات تمامًا. لذلك ، لا يمكننا استخدام محرك بحث بسيط. نحتاج إلى إجراء بحث عن التشابه بدعم من التضمينات المتجهات. التضمين المتجه هو الجزء الأكثر أهمية في هذه المرحلة.
إن تناول البيانات له الخطوات التالية:
التحسينات المستقبلية:
NLTKTextSplitter أو SpacyTextSplitter ) تحسين الإجابات. إذا لم تكن قد فعلت ذلك بعد ، فقم بإعداد البيئة. إذا كنت قد قمت بالفعل بإعداد البيئة ، فقم بتنشيطها باستخدام source venv/bin/activate .
الأمر: python main.py retrieve [--verbose]
الهدف من هذه المرحلة هو استرداد المعلومات من البيانات المحلية. نحن نفعل ذلك عن طريق جلب أكثر القطع ذات الصلة من متجر المتجهات ودمجها مع سؤال المستخدم ومطالبة. يرشد المطالبة نموذج اللغة (LLM) للإجابة على السؤال.
استرداد البيانات له الخطوات التالية:
التحسينات المستقبلية:
اضطررنا إلى تقديم بعض التسويات لجعله يعمل على جهاز محلي في فترة زمنية معقولة.
يعتمد معظم رمز الاستعداد/الاسترداد على الخصوصية الأصلية ، الرمز الذي يسمونه الآن البدائية .
ما هو مختلف:
pathlib بدلاً من os.path وله تسجيل مناسب بدلاً من عبارات الطباعة.--verbose لمعرفة التفاصيل.requirements.txt مع التبعيات غير المباشرة ، على سبيل المثال ، لمحولات Luggingface ووادر مستند Langchain.راجع هذا الملف لمزيد من الملاحظات التي تم جمعها أثناء تطوير هذا المشروع.
هذه خطوة لمرة واحدة. إذا كنت قد قمت بذلك بالفعل ، فما عليك سوى تنشيط البيئة الافتراضية باستخدام source venv/bin/activate .
قم بتشغيل الأوامر التالية لإنشاء بيئة افتراضية وتثبيت الحزم المطلوبة.
python3 -m venv venv
source venv/bin/activate
pip install --upgrade pip
pip install -r requirements.txt محلل PDF في unstructured هو طبقة أعلى حزم المحلل الفعلي. اتبع الإرشادات الواردة في readme unstructured ، تحت الرصاص "تثبيت تبعيات النظام التالية". حزم poppler و tesseract مطلوبة (تجاهل الآخرين).
أقترح البدء بنموذج صغير يعمل على وحدة المعالجة المركزية. GPT4ALL لديه قائمة من النماذج هنا. لقد اختبرت مع MISTRAL-7B-Openorca Q4. يتطلب 8 غيغابايت من ذاكرة الوصول العشوائي للركض. لاحظ أن بعض النماذج لديها تراخيص تقييدية. تحقق من الترخيص قبل استخدامها في المشاريع التجارية.
models .models .

