gpt all local
1.0.0
Este proyecto es un ejercicio de aprendizaje sobre el uso de modelos de idiomas grandes (LLM) para recuperar información de datos privados, ejecutando todas las piezas (incluido el modelo) localmente. El objetivo es ejecutar un LLM en su computadora para hacer preguntas en un conjunto de archivos también en su computadora. Los archivos pueden ser cualquier tipo de documento, como PDF, Word o archivos de texto.
Este método de combinación de LLM y datos privados se conoce como generación de recuperación acuática (RAG). Fue introducido en este documento.
Crédito donde se debe el crédito: basé este proyecto en el PRIVEDGPT original (lo que ahora llaman la versión primordial ). Reimplementé las piezas para comprender cómo funcionan. Ver más en la sección de fuentes.
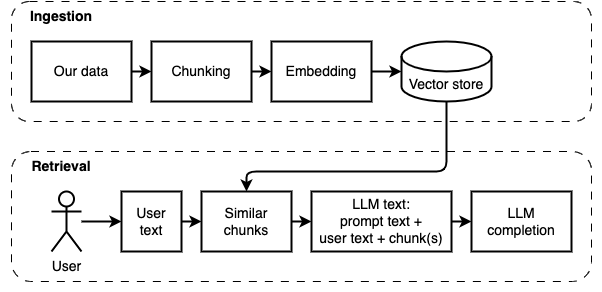
Lo que estamos tratando de lograr: dado un conjunto de archivos en una computadora (a), queremos un modelo de idioma grande (b) que se ejecuta en esa computadora para responder preguntas (c) sobre ellas.
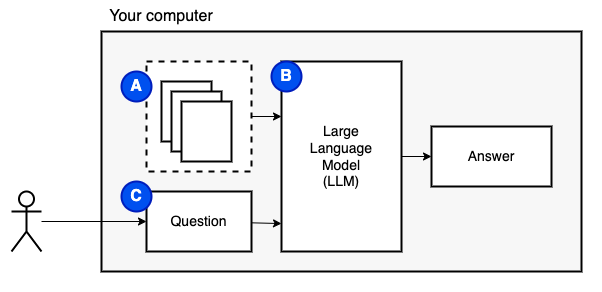
Sin embargo, no podemos alimentar los archivos directamente al modelo. Los modelos de lenguaje grande (LLM) tienen una ventana de contexto que limita cuánta información podemos alimentarlos (su memoria de trabajo). Para superar esa limitación, dividimos los archivos en piezas más pequeñas, llamados trozos y alimentamos solo los relevantes para el modelo (D).
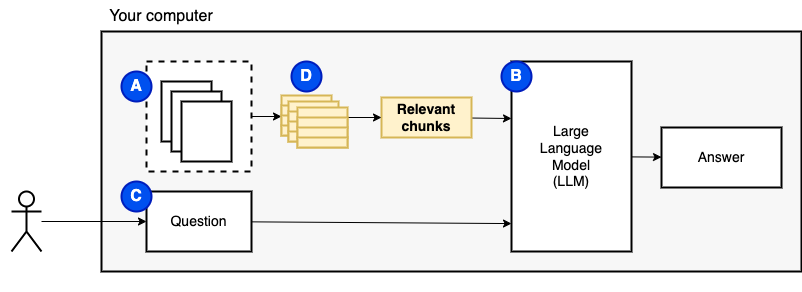
Pero entonces, la pregunta es "¿Cómo encontramos los trozos relevantes?" . Utilizamos la búsqueda de similitud (e) para que coincida con la pregunta y los fragmentos. La búsqueda de similitud, a su vez, requiere incrustaciones de vectores (F), una representación de palabras con vectores que codifican relaciones semánticas (técnicamente, una incrustación de vectores denso , no para confundirlo con representaciones vectoriales dispersas como la bolsa de palabras y TF-IDF). Una vez que tenemos los fragmentos relevantes, los combinamos con la pregunta para crear un aviso (g) que le indique a la LLM a responder la pregunta.
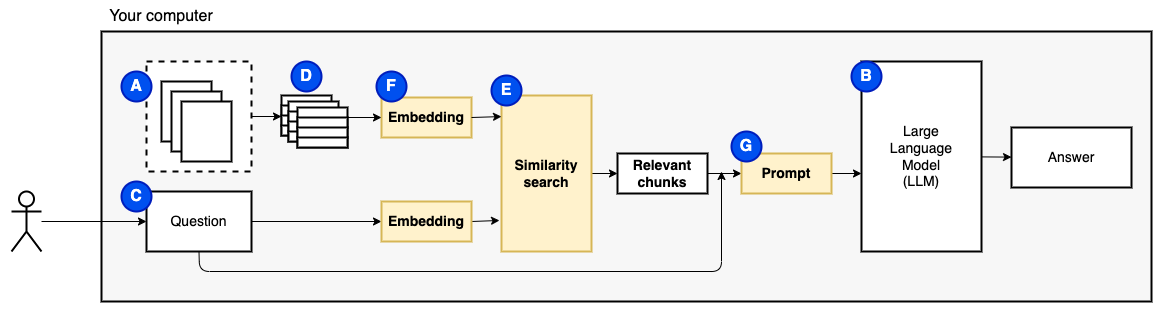
Necesitamos una última pieza: almacenamiento persistente. Crear incrustaciones para los trozos lleva tiempo. No queremos hacer eso cada vez que hacemos una pregunta. Por lo tanto, necesitamos guardar los incrustaciones y el texto original (los fragmentos) en una tienda vectorial (o base de datos) (H). La tienda vectorial puede crecer a lo grande porque almacena los trozos de texto originales y sus incrustaciones vectoriales. Utilizamos un índice vectorial (i) para encontrar fragmentos relevantes de manera eficiente.
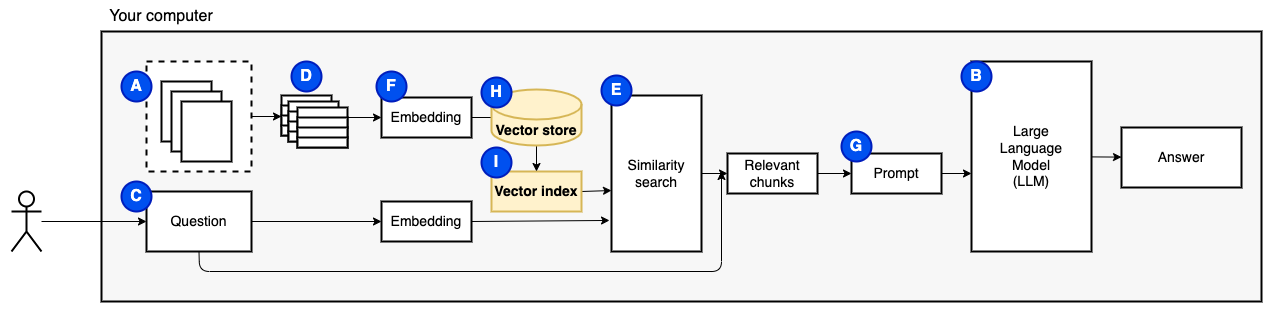
Ahora tenemos todas las piezas que necesitamos.
Podemos dividir la implementación en dos partes: ingerir y recuperar datos.
Estos dos pasos se ilustran en el siguiente diagrama.
Si aún no lo ha hecho, prepare el medio ambiente. Si ya ha preparado el entorno, active con source venv/bin/activate .
Hay dos formas de usar este proyecto:
--verbose a continuación).data .python main.py ingest para ingerir los archivos en la tienda Vector.python main.py retrieve para recuperar datos del almacén Vector. Te solicitará una pregunta. Use la bandera --verbose para obtener más detalles sobre lo que el programa está haciendo detrás de escena.
Para volver a realizar los datos, elimine la carpeta vector_store y ejecute python main.py ingest nuevamente.
Ejecute streamlit run app.py Abrirá la aplicación en una ventana del navegador.
Este comando puede fallar el primero que lo ejecuta. Hay una falla en algún lugar en la forma en que el entorno de Python funciona junto con Pyenv. Si Streamlit muestra un "mensaje del módulo no importar", desactive el entorno de Python con deactivate , activelo nuevamente con source venv/bin/activate , y ejecute streamlit run app.py
Si aún no lo ha hecho, prepare el medio ambiente. Si ya ha preparado el entorno, active con source venv/bin/activate .
Comando: python main.py ingest [--verbose]
El objetivo de esta etapa es hacer que los datos se puedan buscar. Sin embargo, la pregunta del usuario y el contenido de los datos pueden no coincidir exactamente. Por lo tanto, no podemos usar un motor de búsqueda simple. Necesitamos realizar una búsqueda de similitud respaldada por Vector Incrustaciones. La incrustación vectorial es la parte más importante de esta etapa.
La ingestión de datos tiene los siguientes pasos:
Mejoras futuras:
NLTKTextSplitter o SpacyTextSplitter ) mejoran las respuestas. Si aún no lo ha hecho, prepare el medio ambiente. Si ya ha preparado el entorno, active con source venv/bin/activate .
Comando: python main.py retrieve [--verbose]
El objetivo de esta etapa es recuperar información de los datos locales. Lo hacemos obteniendo los trozos más relevantes de la tienda Vector y combinándolos con la pregunta del usuario y un aviso. El aviso instruye al modelo de idioma (LLM) que responda la pregunta.
La recuperación de datos tiene los siguientes pasos:
Mejoras futuras:
Tuvimos que hacer algunos compromisos para que se ejecute en una máquina local en una cantidad razonable de tiempo.
La mayor parte del código de ingesta/recuperación se basa en el PRIVEDGPT original, el que llaman ahora primordial .
Qué es diferente:
pathlib en lugar de os.path y tiene un registro adecuado en lugar de declaraciones de impresión.--verbose para ver los detalles.requirements.txt con las dependencias indirectas, por ejemplo, para los transformadores de la cara de abrazo y los cargadores de documentos Langchain.Consulte este archivo para obtener más notas recopiladas durante el desarrollo de este proyecto.
Este es un paso único. Si ya ha hecho esto, simplemente active el entorno virtual con source venv/bin/activate .
Ejecute los siguientes comandos para crear un entorno virtual e instalar los paquetes requeridos.
python3 -m venv venv
source venv/bin/activate
pip install --upgrade pip
pip install -r requirements.txt El analizador PDF en unstructured es una capa encima de los paquetes de analizador reales. Siga las instrucciones en el ReadMe unstructured , debajo de las balas "Instale las siguientes dependencias del sistema". Se requieren los paquetes Poppler y Tesseract (ignorar los otros).
Sugiero comenzar con un pequeño modelo que se ejecute en CPU. GPT4All tiene una lista de modelos aquí. Probé con Mistral-7B-Openorca Q4. Requiere 8 GB de RAM para ejecutar. Tenga en cuenta que algunos de los modelos tienen licencias restrictivas. Consulte la licencia antes de usarlos en proyectos comerciales.
models .models .

