gpt all local
1.0.0
이 프로젝트는 LLM (Large Language Model)을 사용하여 개인 데이터에서 정보를 검색하고 모든 작품 (모델 포함)을 로컬로 실행하는 학습 운동입니다. 목표는 컴퓨터에서 LLM을 실행하여 컴퓨터의 파일 세트에 대한 질문을하는 것입니다. 파일은 PDF, Word 또는 텍스트 파일과 같은 모든 유형의 문서 일 수 있습니다.
LLM과 개인 데이터를 결합하는이 방법을 검색-방지 생성 (RAG)이라고합니다. 이 논문에서 소개되었습니다.
크레딧이 마감되는 위치 : 나는이 프로젝트를 원래 PrivateGpt (현재 원시 버전이라고 부르는 것)를 기반으로합니다. 나는 그들이 어떻게 작동하는지 이해하기 위해 조각들을 되풀이했다. 출처 섹션에서 자세한 내용을 참조하십시오.
우리가 달성하려는 것 : 컴퓨터에 파일 세트가 주어지면 (a), 우리는 그 컴퓨터에서 큰 언어 모델 (b)을 실행하여 질문에 대한 질문에 대답하기를 원합니다 (b).
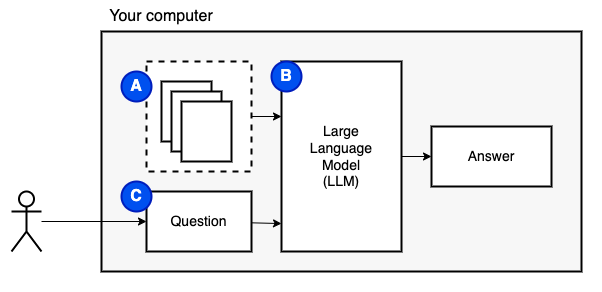
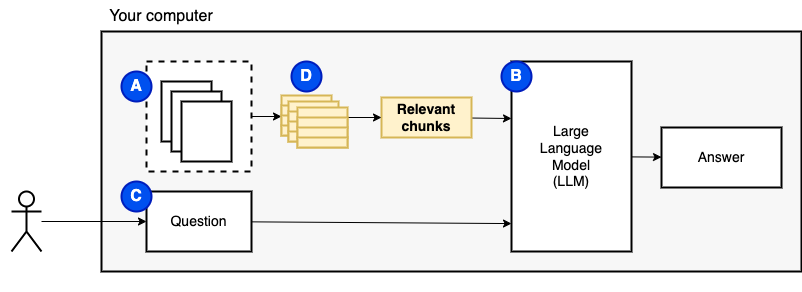
그러나 파일을 모델에 직접 공급할 수는 없습니다. 대형 언어 모델 (LLM)에는 정보를 제공 할 수있는 정보 (작업 메모리)를 제한하는 컨텍스트 창이 있습니다. 이 한계를 극복하기 위해 파일을 청크라고하는 작은 조각 으로 나누고 관련 파일 만 모델 (d)에 공급합니다.
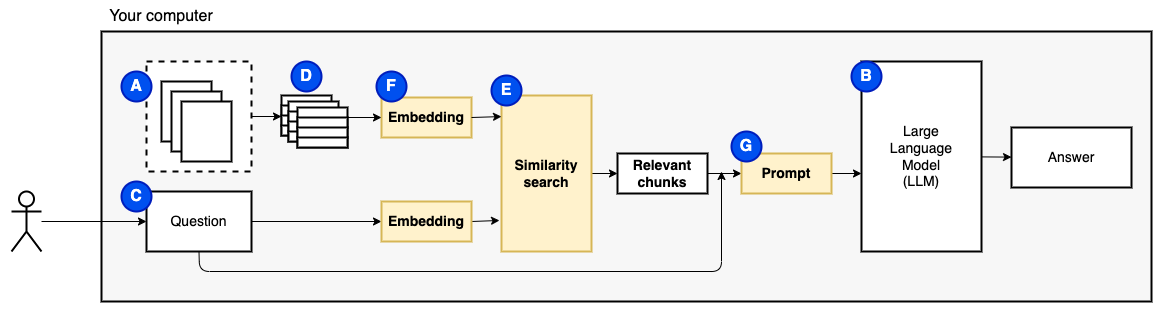
그러나 그 질문은 "관련 덩어리를 어떻게 찾을 수 있습니까?" 가됩니다. . 우리는 유사성 검색 (e)을 사용하여 질문과 청크와 일치합니다. 유사성 검색에는 의미 론적 관계를 인코딩하는 벡터가있는 단어의 표현 인 벡터 임베딩 (F)이 필요합니다 (기술적으로 밀도가 높은 벡터 임베딩,이를 단어의 백 및 TF-IDF와 같은 희소 벡터 표현과 혼동하지 않도록). 관련 덩어리가 있으면 질문과 결합하여 LLM에 질문에 대답하도록 지시하는 프롬프트 (g)를 만듭니다.
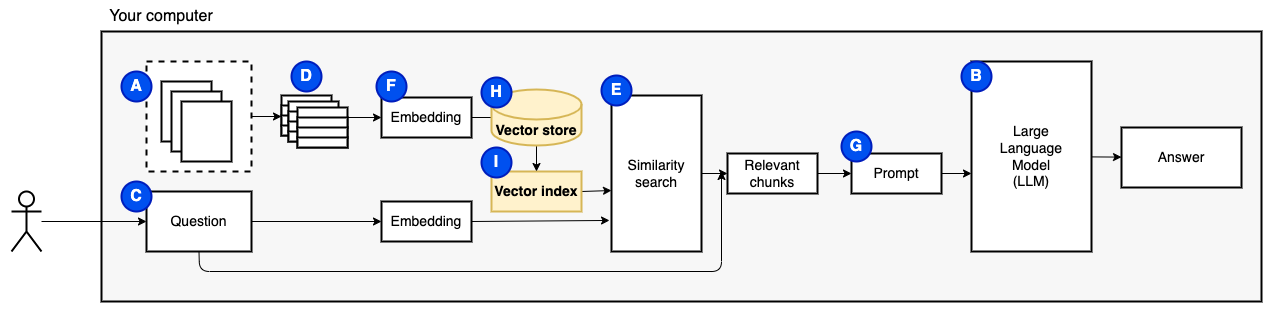
우리는 마지막 조각이 필요합니다 : 영구 스토리지. 청크를위한 임베딩을 만드는 데는 시간이 걸립니다. 우리는 질문을 할 때마다 그렇게하고 싶지 않습니다. 따라서 벡터 스토어 (또는 데이터베이스) (H)에 포함 및 원본 텍스트 (청크)를 저장해야합니다. 벡터 스토어는 원래 텍스트 청크와 벡터 임베딩을 저장하기 때문에 커질 수 있습니다. 우리는 벡터 인덱스 (I)를 사용하여 관련 청크를 효율적으로 찾습니다.
이제 우리는 필요한 모든 조각을 가지고 있습니다.
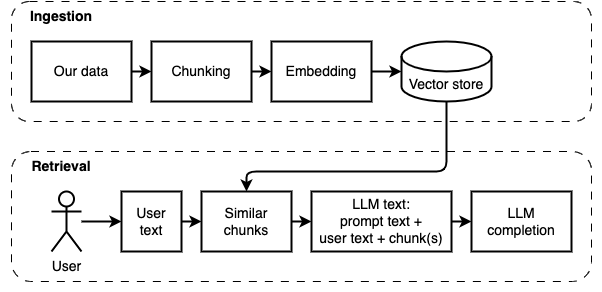
구현을 데이터 수집 및 검색의 두 부분으로 나눌 수 있습니다.
이 두 단계는 다음 다이어그램에 설명되어 있습니다.
아직 그렇게하지 않았다면 환경을 준비하십시오. 이미 환경을 준비한 경우 source venv/bin/activate 로 활성화하십시오.
이 프로젝트를 사용하는 두 가지 방법이 있습니다.
--verbose 보스 플래그 참조).data 폴더에 복사하십시오.python main.py ingest 실행하여 파일을 벡터 저장소에 섭취하십시오.python main.py retrieve 벡터 스토어에서 데이터를 검색하십시오. 그것은 당신에게 질문을 자극 할 것입니다. --verbose 플래그를 사용하여 프로그램이 무대 뒤에서하는 일에 대한 자세한 내용을 얻으십시오.
데이터를 반복하려면 vector_store 폴더를 삭제하고 python main.py ingest 다시 실행하십시오.
streamlit run app.py 실행하십시오. 브라우저 창에서 앱을 엽니 다.
이 명령은 처음 실행할 때 실패 할 수 있습니다. 파이썬 환경이 Pyenv와 함께 어떻게 작동하는지 어딘가에 결함이 있습니다. Streamlit에 "모듈 메시지를 가져올 수 없음"을 표시하면, deactivate 로 파이썬 환경을 비활성화하고 source venv/bin/activate 로 다시 활성화하고 streamlit run app.py 실행하십시오.
아직 그렇게하지 않았다면 환경을 준비하십시오. 이미 환경을 준비한 경우 source venv/bin/activate 로 활성화하십시오.
명령 : python main.py ingest [--verbose]
이 단계의 목표는 데이터를 검색 할 수 있도록하는 것입니다. 그러나 사용자의 질문과 데이터 내용이 정확히 일치하지 않을 수 있습니다. 따라서 간단한 검색 엔진을 사용할 수 없습니다. 벡터 임베딩에서 지원하는 유사성 검색을 수행해야합니다. 벡터 임베딩은이 단계에서 가장 중요한 부분입니다.
데이터 수집에는 다음 단계가 있습니다.
향후 개선 :
NLTKTextSplitter 또는 SpacyTextSplitter )가 답을 향상시키는 지 확인하십시오. 아직 그렇게하지 않았다면 환경을 준비하십시오. 이미 환경을 준비한 경우 source venv/bin/activate 로 활성화하십시오.
명령 : python main.py retrieve [--verbose]
이 단계의 목표는 로컬 데이터에서 정보를 검색하는 것입니다. 우리는 벡터 스토어에서 가장 관련성이 높은 덩어리를 가져 와서 사용자의 질문과 프롬프트와 결합하여 그렇게합니다. 프롬프트는 언어 모델 (LLM)에 질문에 답변하도록 지시합니다.
데이터 검색 데이터에는 다음 단계가 있습니다.
향후 개선 :
우리는 합리적인 시간 안에 로컬 기계에서 실행하기 위해 약간의 타협을해야했습니다.
수집/검색 코드의 대부분은 원래 PrivateGpt 를 기반으로합니다.
다른 점 :
os.path 대신 pathlib 사용하고 인쇄 문 대신 올바른 로깅이 있습니다.--verbose 플래그를 사용하여 세부 사항을보십시오.requirements.txt 채워집니다.이 프로젝트를 개발하는 동안 수집 된 더 많은 메모는이 파일을 참조하십시오.
이것은 일회성 단계입니다. 이미이 작업을 수행 한 경우 source venv/bin/activate 사용하여 가상 환경을 활성화하십시오.
가상 환경을 만들려면 다음 명령을 실행하고 필요한 패키지를 설치하십시오.
python3 -m venv venv
source venv/bin/activate
pip install --upgrade pip
pip install -r requirements.txt unstructured PDF 파서는 실제 파서 패키지 위에있는 레이어입니다. "다음 시스템 의존성 설치"총알에 따라 unstructured readme의 지침을 따르십시오. Poppler 및 Tesseract 패키지가 필요합니다 (다른 것들을 무시하십시오).
CPU에서 실행되는 작은 모델로 시작하는 것이 좋습니다. gpt4all에는 여기에 모델 목록이 있습니다. 나는 Mistral-7B-Openorca Q4로 테스트했습니다. 8GB의 RAM이 필요합니다. 일부 모델에는 제한 라이센스가 있습니다. 상업 프로젝트에서 사용하기 전에 라이센스를 확인하십시오.
models 이라는 폴더를 만듭니다.models 폴더에 복사하십시오.

