gpt all local
1.0.0
Este projeto é um exercício de aprendizado sobre o uso de grandes modelos de idiomas (LLMS) para recuperar informações de dados privados, executando todas as peças (incluindo o modelo) localmente. O objetivo é executar um LLM no seu computador para fazer perguntas em um conjunto de arquivos também no seu computador. Os arquivos podem ser qualquer tipo de documento, como arquivos de PDF, Word ou Text.
Este método de combinação de LLMs e dados privados é conhecido como geração de recuperação upmentada por recuperação (RAG). Foi introduzido neste artigo.
Crédito onde o crédito é devido: baseei este projeto no privateGPT original (o que eles chamam de versão primordial ). Reimplei as peças para entender como elas funcionam. Veja mais na seção de fontes.
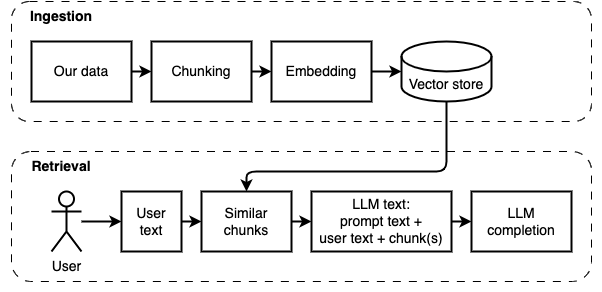
O que estamos tentando alcançar: dado um conjunto de arquivos em um computador (a), queremos um grande modelo de idioma (b) em execução nesse computador para responder às perguntas (c) nelas.
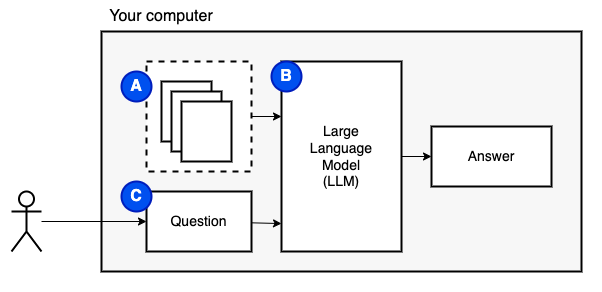
No entanto, não podemos alimentar os arquivos diretamente ao modelo. Os grandes modelos de idiomas (LLMs) têm uma janela de contexto que limita a quantidade de informações que podemos alimentar neles (sua memória de trabalho). Para superar essa limitação, dividimos os arquivos em peças menores, chamadas pedaços e alimentamos apenas os relevantes ao modelo (d).
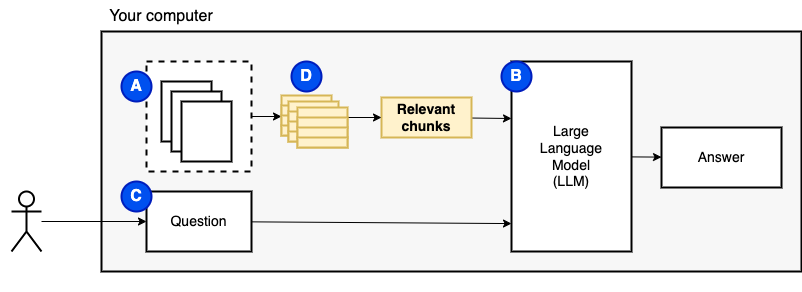
Mas então, a pergunta se torna "como encontramos os pedaços relevantes?" . Usamos a pesquisa de similaridade (e) para corresponder à pergunta e aos pedaços. A pesquisa de similaridade, por sua vez, requer incorporações vetoriais (F), uma representação de palavras com vetores que codificam relacionamentos semânticos (tecnicamente, uma incorporação dense de vetor, para não confundi-lo com representações vetoriais esparsas, como saco de palavras e TF-IDF). Depois de termos os pedaços relevantes, combinamos -os com a pergunta para criar um prompt (g) que instrua o LLM a responder à pergunta.
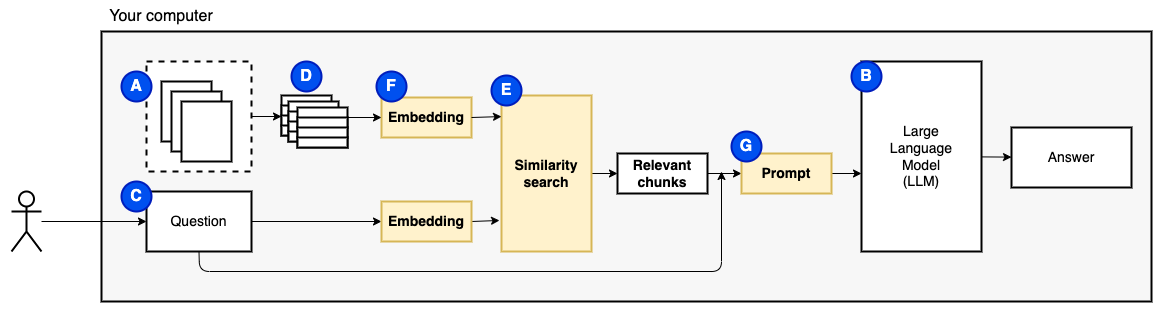
Precisamos de uma última peça: armazenamento persistente. Criar incorporações para os pedaços leva tempo. Não queremos fazer isso toda vez que fazemos uma pergunta. Portanto, precisamos salvar as incorporações e o texto original (os pedaços) em um loja de vetores (ou banco de dados) (h). O Vector Store pode crescer grande porque armazena os pedaços de texto originais e suas incorporações de vetor. Usamos um índice vetorial (i) para encontrar pedaços relevantes com eficiência.
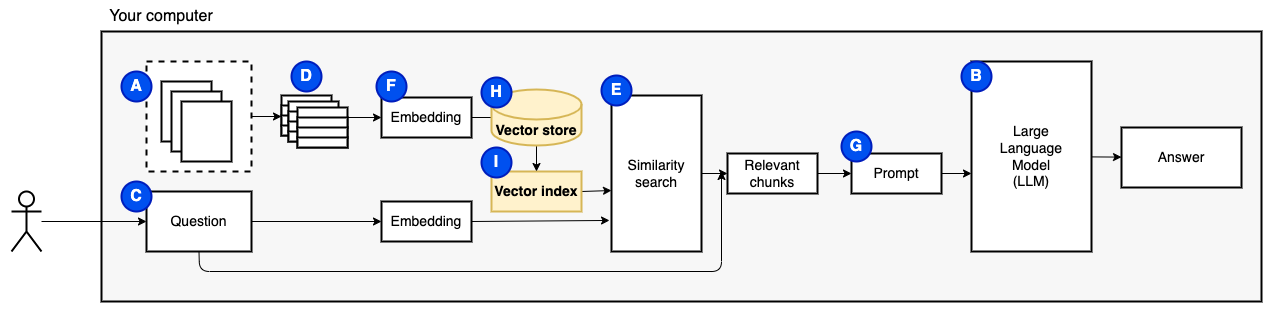
Agora temos todas as peças que precisamos.
Podemos dividir a implementação em duas partes: ingerir e recuperar dados.
Essas duas etapas são ilustradas no diagrama a seguir.
Se você ainda não fez isso, prepare o meio ambiente. Se você já preparou o ambiente, ative -o com source venv/bin/activate .
Existem duas maneiras de usar este projeto:
--verbose abaixo).data .python main.py ingest para ingerir os arquivos no Vector Store.python main.py retrieve para recuperar dados do Vector Store. Isso o levará a uma pergunta. Use o sinalizador --verbose para obter mais detalhes sobre o que o programa está fazendo nos bastidores.
Para reinomizar os dados, exclua a pasta vector_store e execute python main.py ingest novamente.
Execute streamlit run app.py Ele abrirá o aplicativo em uma janela do navegador.
Este comando pode falhar no primeiro que você o executa. Há uma falha em algum lugar de como o ambiente Python funciona em conjunto com o Pyenv. Se o streamlit mostrar uma mensagem "Não é possível importar o módulo", desative o ambiente Python com deactivate , ative -o novamente com source venv/bin/activate e executar streamlit run app.py
Se você ainda não fez isso, prepare o meio ambiente. Se você já preparou o ambiente, ative -o com source venv/bin/activate .
Comando: python main.py ingest [--verbose]
O objetivo deste estágio é tornar os dados pesquisáveis. No entanto, a pergunta do usuário e o conteúdo dos dados podem não corresponder exatamente. Portanto, não podemos usar um mecanismo de pesquisa simples. Precisamos realizar uma pesquisa de similaridade suportada por incorporações de vetor. A incorporação do vetor é a parte mais importante deste estágio.
A ingestão de dados tem as seguintes etapas:
Melhorias futuras:
NLTKTextSplitter ou SpacyTextSplitter ) melhoram as respostas. Se você ainda não fez isso, prepare o meio ambiente. Se você já preparou o ambiente, ative -o com source venv/bin/activate .
Comando: python main.py retrieve [--verbose]
O objetivo deste estágio é recuperar informações dos dados locais. Fazemos isso buscando os pedaços mais relevantes da loja de vetores e combinando -os com a pergunta do usuário e um prompt. O prompt instrui o Modelo de Idioma (LLM) a responder à pergunta.
A recuperação de dados tem as seguintes etapas:
Melhorias futuras:
Tivemos que fazer alguns compromissos para fazê -lo em uma máquina local em um período de tempo razoável.
A maior parte do código de ingestão/recuperação é baseada no PrivateGPT original, o que eles chamam de agora primordial .
O que é diferente:
pathlib em vez de os.path e possui log adequado em vez de instruções impressas.--verbose para ver os detalhes.requirements.txt com as dependências indiretas, por exemplo, para Huggingface Transformers e Langchain Document Loaders.Consulte este arquivo para obter mais notas coletadas durante o desenvolvimento deste projeto.
Este é um passo único. Se você já fez isso, basta ativar o ambiente virtual com source venv/bin/activate .
Execute os seguintes comandos para criar um ambiente virtual e instalar os pacotes necessários.
python3 -m venv venv
source venv/bin/activate
pip install --upgrade pip
pip install -r requirements.txt O analisador PDF em unstructured é uma camada na parte superior dos pacotes reais do analisador. Siga as instruções no ReadMe unstructured , sob as balas "Instale as seguintes dependências do sistema". Os pacotes Poppler e Tesseract são necessários (ignore os outros).
Sugiro começar com um modelo pequeno que seja executado na CPU. O GPT4all tem uma lista de modelos aqui. Testei com Mistral-7b-Openorca Q4. Requer 8 GB de RAM para executar. Observe que alguns dos modelos têm licenças restritivas. Verifique a licença antes de usá -los em projetos comerciais.
models .models .

