gpt all local
1.0.0
Этот проект представляет собой учебное упражнение по использованию моделей крупных языков (LLMS) для извлечения информации из частных данных, запуска всех произведений (включая модель) локально. Цель состоит в том, чтобы запустить LLM на вашем компьютере, чтобы задать вопросы на наборе файлов также на вашем компьютере. Файлы могут быть любым типом документа, такого как PDF, Word или текстовые файлы.
Этот метод комбинирования LLM и частных данных известен как поколение поиска-августа (RAG). Это было введено в этой статье.
Кредит, где должен быть кредит: я основал этот проект на оригинальном приватике (то, что они теперь называют изначальной версией). Я переосмыслил части, чтобы понять, как они работают. Смотрите больше в разделе источников.
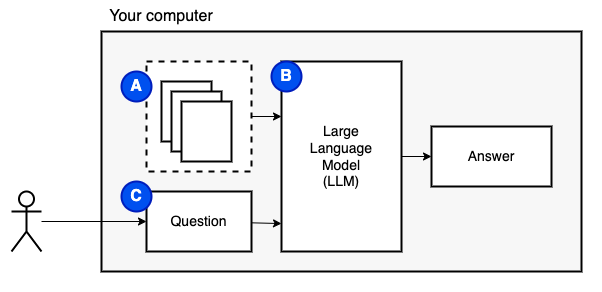
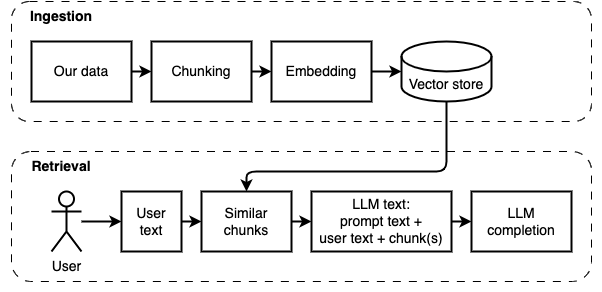
То, чего мы пытаемся достичь: Учитывая набор файлов на компьютере (а), мы хотим, чтобы на этом компьютере работала большая языковая модель (б), чтобы ответить на вопросы (c) на них.
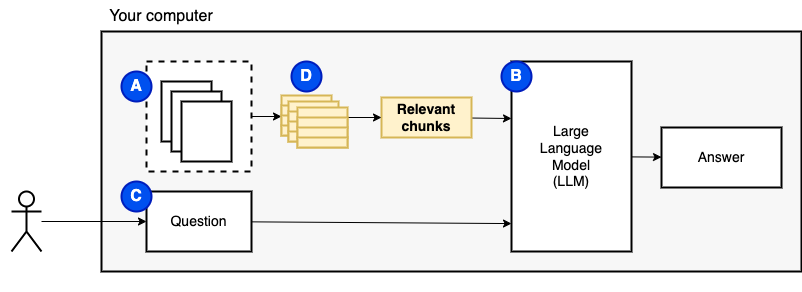
Тем не менее, мы не можем подавать файлы непосредственно в модель. Большие языковые модели (LLM) имеют окно контекста, которое ограничивает, сколько информации мы можем вписать в них (их рабочая память). Чтобы преодолеть это ограничение, мы разделили файлы на более мелкие части, называемые кусочками и передаем только соответствующие из них в модель (D).
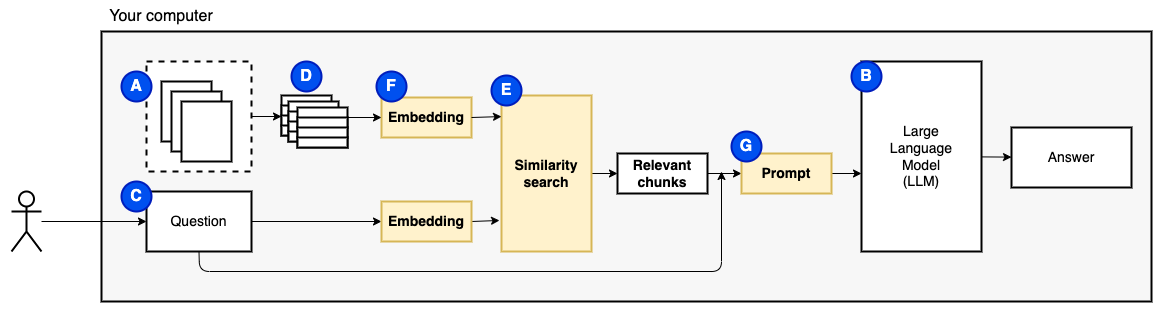
Но тогда возникает вопрос "как мы находим соответствующие куски?" Полем Мы используем поиск сходства (e), чтобы соответствовать вопросу и кусочкам. Поиск сходства, в свою очередь, требует векторных встраиваний (F), представления слов с векторами, которые кодируют семантические отношения (технически, плотное векторное встраивание, а не путать его с редкими векторными представлениями, такими как мешок слов и TF-IDF). Как только у нас есть соответствующие куски, мы объединяем их с вопросом, чтобы создать подсказку (g), которая дает инструкции LLM ответить на вопрос.
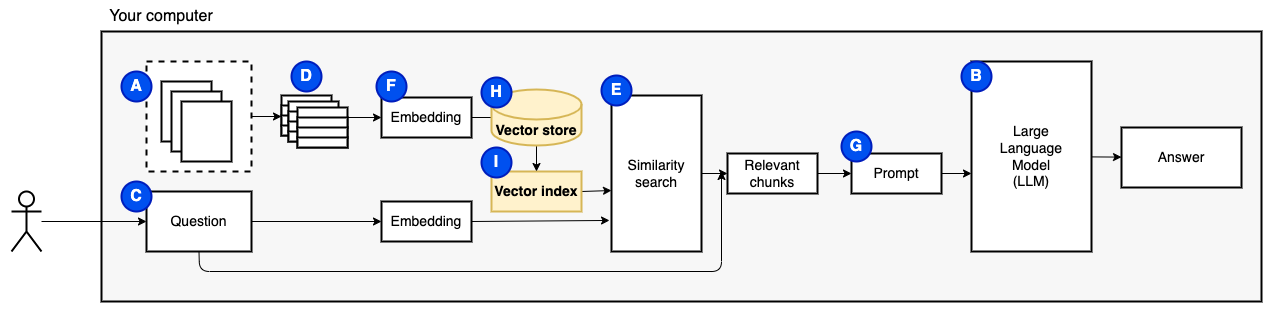
Нам нужна последняя часть: постоянное хранение. Создание встраиваний для кусков требует времени. Мы не хотим делать это каждый раз, когда задаем вопрос. Поэтому нам нужно сохранить вставки и исходный текст (кусочки) в векторном хранилище (или базе данных) (h). Векторный магазин может расти большим, потому что он хранит оригинальные текстовые куски и их векторные встроения. Мы используем векторный индекс (i), чтобы эффективно найти соответствующие куски.
Теперь у нас есть все необходимые вещи.
Мы можем разделить реализацию на две части: проглатывание и получение данных.
Эти два шага показаны на следующей диаграмме.
Если вы еще этого не сделали, подготовьте окружающую среду. Если вы уже подготовили окружающую среду, активируйте ее source venv/bin/activate .
Есть два способа использовать этот проект:
--verbose ниже).data .python main.py ingest , чтобы проглатывать файлы в векторный хранилище.python main.py retrieve для извлечения данных из векторного хранилища. Это побудит вас за вопрос. Используйте флаг --verbose , чтобы получить более подробную информацию о том, что программа делает за кулисами.
Чтобы переехать данные, удалите папку vector_store и запустите python main.py ingest снова.
Запустите streamlit run app.py Он откроет приложение в окне браузера.
Эта команда может потерпеть неудачу первым, когда вы запустили ее. Где -то есть глюк в том, как среда Python работает вместе с Pyenv. Если Streamlit показывает «невозможно импортировать сообщение модуля», деактивируйте среду Python с deactivate , активируйте его снова с помощью source venv/bin/activate , и запустите streamlit run app.py
Если вы еще этого не сделали, подготовьте окружающую среду. Если вы уже подготовили окружающую среду, активируйте ее source venv/bin/activate .
Команда: python main.py ingest [--verbose]
Цель этого этапа - сделать поиск данных. Тем не менее, вопрос пользователя и содержание данных могут не совпадать точно. Поэтому мы не можем использовать простую поисковую систему. Нам нужно выполнить поиск сходства, поддерживаемый векторными вставками. Векторное встраивание является наиболее важной частью этой стадии.
В приглашении данных имеет следующие шаги:
Будущие улучшения:
NLTKTextSplitter или SpacyTextSplitter ). Если вы еще этого не сделали, подготовьте окружающую среду. Если вы уже подготовили окружающую среду, активируйте ее source venv/bin/activate .
Команда: python main.py retrieve [--verbose]
Цель этого этапа - получить информацию из локальных данных. Мы делаем это, получая наиболее релевантные куски из векторного магазина и объединив их с вопросом пользователя и подсказкой. Приглашение инструктирует языковую модель (LLM) ответить на вопрос.
Получение данных имеет следующие шаги:
Будущие улучшения:
Мы должны были поставить некоторые компромиссы, чтобы он запустил на местной машине за разумное время.
Большая часть кода Ingest/Retive основана на исходной Privategpt, которую они называют, теперь изначальным .
Что отличается:
pathlib вместо os.path и имеет правильную регистрацию вместо печатных операторов.--verbose , чтобы увидеть детали.requirements.txt Текст косвенными зависимостями, например, для трансформаторов HuggingFace и загрузчиков документов Langchain.Смотрите этот файл для получения дополнительных заметок, собранных во время разработки этого проекта.
Это единовременный шаг. Если вы уже сделали это, просто активируйте виртуальную среду с source venv/bin/activate .
Запустите следующие команды, чтобы создать виртуальную среду и установить необходимые пакеты.
python3 -m venv venv
source venv/bin/activate
pip install --upgrade pip
pip install -r requirements.txt Парсер в PDF в unstructured - это слой поверх фактических пакетов анализатора. Следуйте инструкциям в unstructured README в пулях «Установить следующие системы зависимости». Требуются пакеты Poppler и Tesseract (игнорируйте другие).
Я предлагаю начать с небольшой модели, которая работает на процессоре. GPT4ALL имеет список моделей здесь. Я проверил с Mistral-7B-Openorca Q4. Для запуска требуется 8 ГБ оперативной памяти. Обратите внимание, что некоторые модели имеют ограничительные лицензии. Проверьте лицензию перед использованием их в коммерческих проектах.
models .models .

