gpt all local
1.0.0
Ce projet est un exercice d'apprentissage sur l'utilisation de modèles de grande langue (LLMS) pour récupérer des informations à partir de données privées, exécutant tous les éléments (y compris le modèle) localement. L'objectif est d'exécuter un LLM sur votre ordinateur pour poser des questions sur un ensemble de fichiers également sur votre ordinateur. Les fichiers peuvent être n'importe quel type de document, tels que PDF, Word ou Fichiers texte.
Cette méthode de combinaison de LLM et de données privées est connue sous le nom de génération (RAG) de la récupération (RAG). Il a été introduit dans cet article.
Crédit où le crédit est dû: J'ai basé ce projet sur le privateGPT original (ce qu'ils appellent maintenant la version primordiale ). J'ai réimplémenté les pièces pour comprendre comment elles fonctionnent. Voir plus dans la section Sources.
Ce que nous essayons de réaliser: Compte tenu d'un ensemble de fichiers sur un ordinateur (a), nous voulons un modèle de langue large (b) en cours d'exécution sur cet ordinateur pour répondre aux questions (c) sur eux.
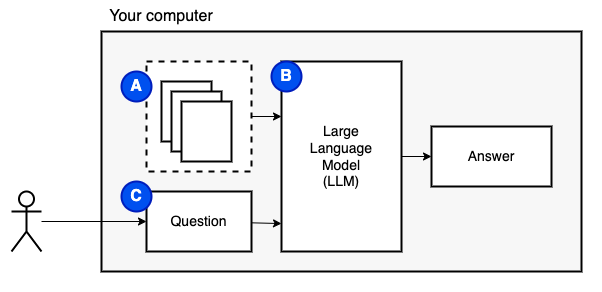
Cependant, nous ne pouvons pas alimenter les fichiers directement au modèle. Les grands modèles de langue (LLMS) ont une fenêtre de contexte qui limite la quantité d'informations que nous pouvons les alimenter (leur mémoire de travail). Pour surmonter cette limitation, nous avons divisé les fichiers en pièces plus petites, appelées morceaux , et ne nourrissons que les pertinents au modèle (D).
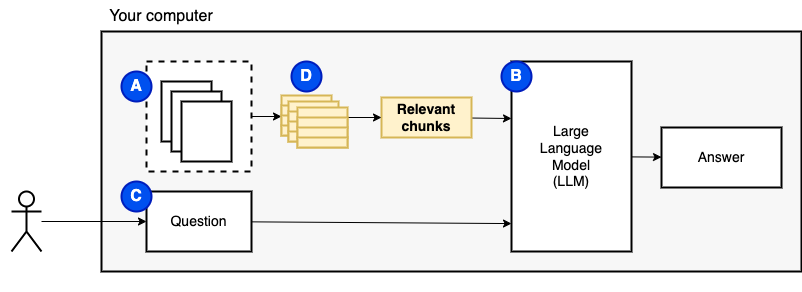
Mais alors, la question devient "Comment trouvons-nous les morceaux pertinents?" . Nous utilisons la recherche de similitude (e) pour correspondre à la question et aux morceaux. La recherche de similitude, à son tour, nécessite des incorporations de vecteurs (F), une représentation de mots avec des vecteurs qui codent les relations sémantiques (techniquement, une incorporation de vecteurs dense , et non pour le confondre avec des représentations vectorielles clairsemées telles que le sac de mots et TF-IDF). Une fois que nous avons les morceaux pertinents, nous les combinons avec la question pour créer une invite (g) qui demande au LLM de répondre à la question.
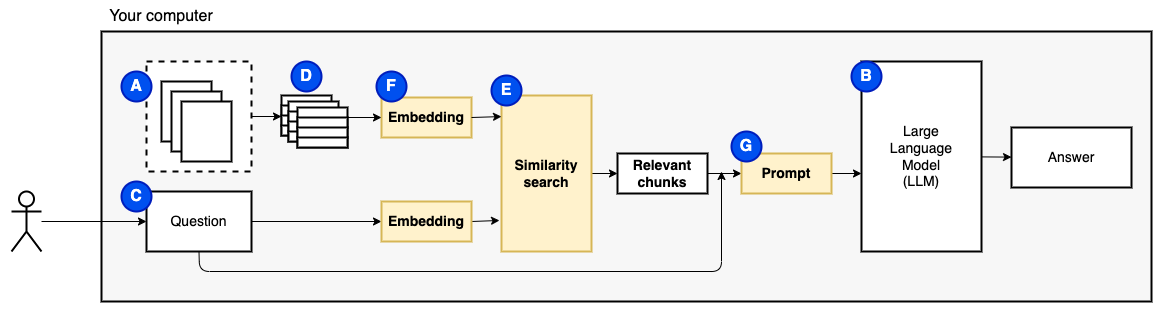
Nous avons besoin d'une dernière pièce: stockage persistant. Créer des intégres pour les morceaux prend du temps. Nous ne voulons pas le faire chaque fois que nous posons une question. Par conséquent, nous devons enregistrer les intérêts et le texte d'origine (les morceaux) dans un magasin de vecteur (ou une base de données) (H). Le magasin vectoriel peut devenir grand car il stocke les morceaux de texte d'origine et leurs intérêts vectoriels. Nous utilisons un indice vectoriel (i) pour trouver efficacement des morceaux pertinents.
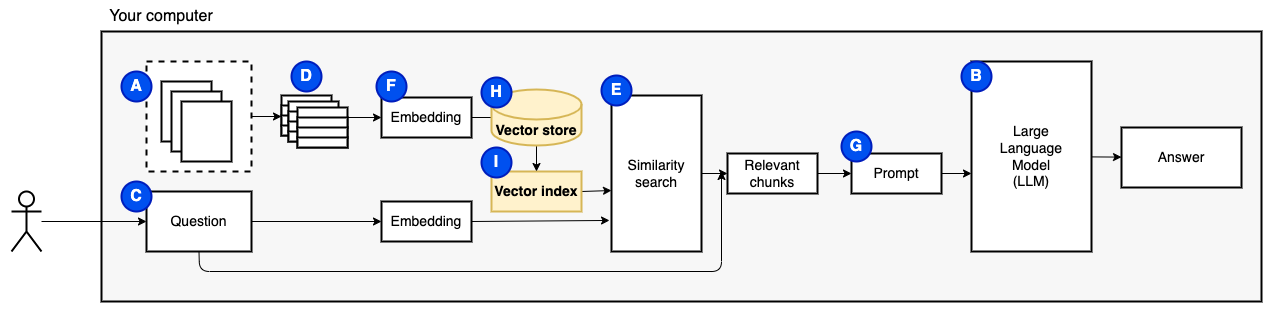
Maintenant, nous avons toutes les pièces dont nous avons besoin.
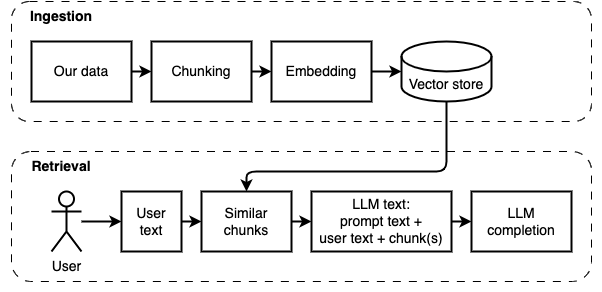
Nous pouvons diviser la mise en œuvre en deux parties: ingérer et récupérer des données.
Ces deux étapes sont illustrées dans le diagramme suivant.
Si vous ne l'avez pas encore fait, préparez l'environnement. Si vous avez déjà préparé l'environnement, activez-le avec source venv/bin/activate .
Il existe deux façons d'utiliser ce projet:
--verbose ci-dessous).data .python main.py ingest pour ingérer les fichiers dans le magasin vectoriel.python main.py retrieve pour récupérer les données du magasin vectoriel. Cela vous invitera à une question. Utilisez l'indicateur --verbose pour obtenir plus de détails sur ce que le programme fait dans les coulisses.
Pour réintégrer les données, supprimez le dossier vector_store et exécutez à nouveau python main.py ingest
Exécutez streamlit run app.py Il ouvrira l'application dans une fenêtre de navigateur.
Cette commande peut échouer le premier à l'exécuter. Il y a un problème quelque part dans la façon dont l'environnement Python fonctionne avec Pyenv. Si Streamlit montre un "Message du module Importer Import", désactivez l'environnement Python avec deactivate , activez-le à nouveau avec source venv/bin/activate et exécutez streamlit run app.py
Si vous ne l'avez pas encore fait, préparez l'environnement. Si vous avez déjà préparé l'environnement, activez-le avec source venv/bin/activate .
Commande: python main.py ingest [--verbose]
Le but de cette étape est de rendre les données consultables. Cependant, la question de l'utilisateur et le contenu des données peuvent ne pas correspondre exactement. Par conséquent, nous ne pouvons pas utiliser un moteur de recherche simple. Nous devons effectuer une recherche de similitude prise en charge par des intégres vectoriels. L'intégration du vecteur est la partie la plus importante de cette étape.
L'ingestion de données a les étapes suivantes:
Améliorations futures:
NLTKTextSplitter ou SpacyTextSplitter ) améliorent les réponses. Si vous ne l'avez pas encore fait, préparez l'environnement. Si vous avez déjà préparé l'environnement, activez-le avec source venv/bin/activate .
Commande: python main.py retrieve [--verbose]
Le but de cette étape est de récupérer des informations des données locales. Nous le faisons en récupérant les morceaux les plus pertinents du magasin Vector et en les combinant avec la question de l'utilisateur et une invite. L'invite demande au modèle de langue (LLM) de répondre à la question.
La récupération des données a les étapes suivantes:
Améliorations futures:
Nous avons dû faire des compromis pour le faire fonctionner sur une machine locale dans un délai raisonnable.
La plupart du code d'ingestion / récupération est basé sur le privategpt d'origine, celui qu'ils appellent maintenant primordial .
Ce qui est différent:
pathlib au lieu d' os.path et a une journalisation appropriée au lieu des instructions d'impression.--verbose pour voir les détails.requirements.txt avec les dépendances indirectes, par exemple, pour les transformateurs en étreinte et les chargeurs de documents Langchain.Voir ce fichier pour plus de notes collectées lors du développement de ce projet.
Ceci est une étape ponctuelle. Si vous l'avez déjà fait, activez simplement l'environnement virtuel avec source venv/bin/activate .
Exécutez les commandes suivantes pour créer un environnement virtuel et installer les packages requis.
python3 -m venv venv
source venv/bin/activate
pip install --upgrade pip
pip install -r requirements.txt L'analyseur PDF en unstructured est une couche au-dessus des packages d'analyser réels. Suivez les instructions dans la lecture unstructured , sous les balles "Installer les dépendances du système suivantes". Les packages Poppler et Tesseract sont nécessaires (ignorez les autres).
Je suggère de commencer par un petit modèle qui fonctionne sur CPU. GPT4ALL a une liste de modèles ici. J'ai testé avec Mistral-7B-Openorca Q4. Il faut 8 Go de RAM pour fonctionner. Notez que certains modèles ont des licences restrictives. Vérifiez la licence avant de les utiliser dans des projets commerciaux.
models .models .

