gpt all local
1.0.0
该项目是使用大型语言模型(LLM)从私人数据中检索信息,在本地运行所有部分(包括模型)的学习练习。目的是在计算机上运行LLM,以在计算机上的一组文件上提出问题。这些文件可以是任何类型的文档,例如PDF,Word或文本文件。
这种结合LLM和私人数据的方法称为检索增强的生成(RAG)。它是在本文中引入的。
信用额度应得的信用:我基于原始Privategpt(他们称之为原始版本)。我重新完成了这些作品以了解它们的工作方式。在“来源”部分中查看更多内容。
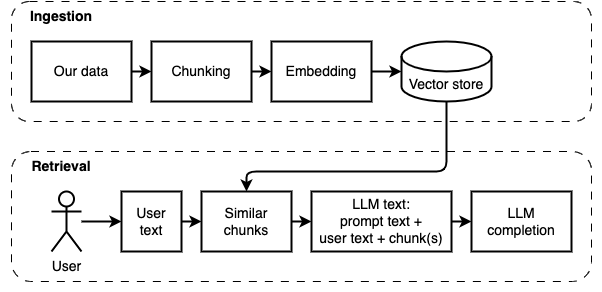
我们要实现的目标:给定计算机上的一组文件(a),我们希望在该计算机上运行的大型语言模型(b)在它们上回答问题(c)。
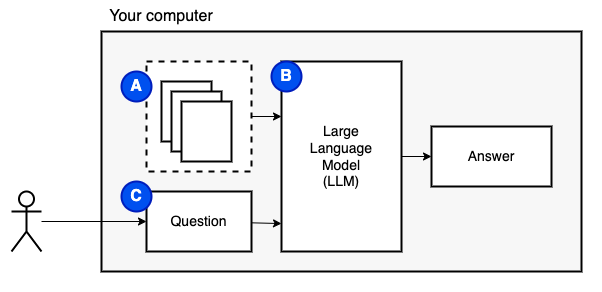
但是,我们无法将文件直接馈送到模型。大型语言模型(LLMS)具有上下文窗口,该窗口限制了我们可以输入的信息(它们的工作记忆)。为了克服该限制,我们将文件分为较小的零件,称为块,仅将相关的文件馈送到模型(D)中。
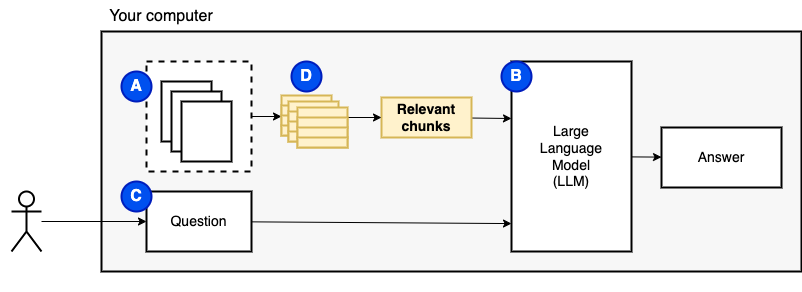
但是,问题变成了“我们如何找到相关的块?” 。我们使用相似性搜索(e)来匹配问题和块。相似性搜索反过来需要向量嵌入(F),这是用编码语义关系的向量的单词表示(从技术上讲,密集的向量嵌入,而不是将其与稀疏的向量表示(例如词袋和tf-idf)混淆)。一旦有了相关的块,我们就将它们与问题结合在一起,以创建一个提示(g),该提示(g)指示LLM回答问题。
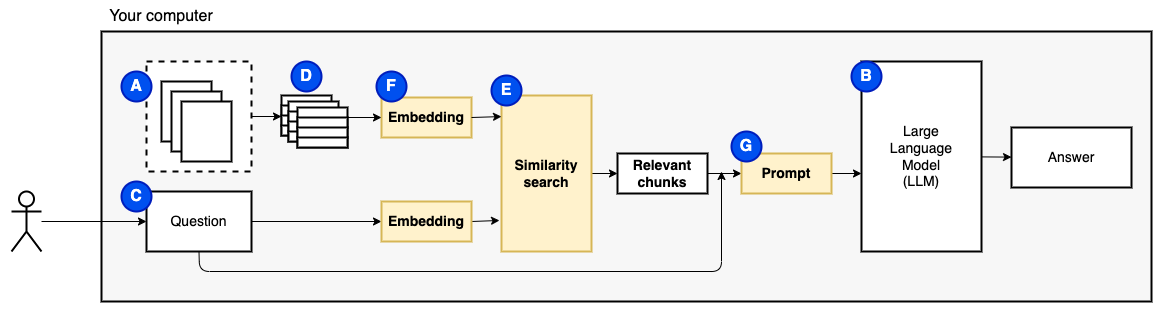
我们需要最后一块:持续存储。为块创建嵌入需要时间。我们不想每次问一个问题。因此,我们需要将嵌入和原始文本(块)保存在矢量存储(或数据库)(h)中。矢量商店可以大大生长,因为它存储了原始文本块及其矢量嵌入。我们使用矢量索引(i)有效地找到相关的块。
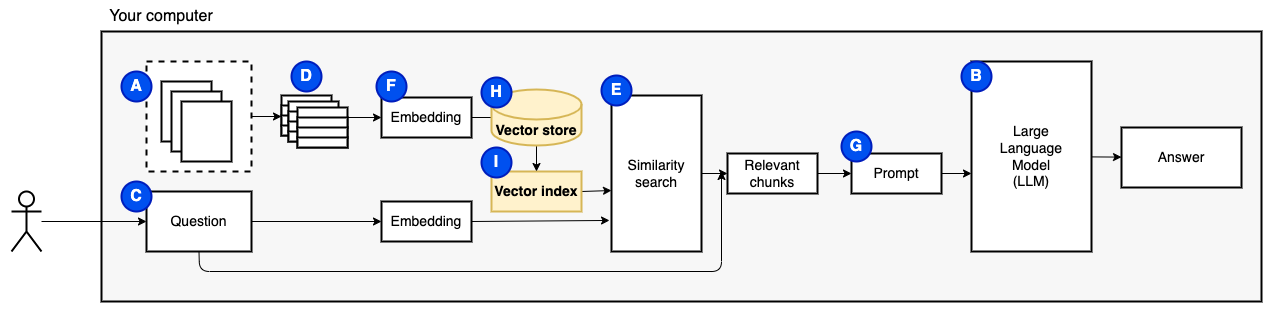
现在我们有了我们需要的所有作品。
我们可以将实现分为两个部分:摄入和检索数据。
以下图中说明了这两个步骤。
如果您还没有这样做,请准备环境。如果您已经准备好环境,请用source venv/bin/activate激活它。
有两种使用此项目的方法:
--verbose标志)。data文件夹中。python main.py ingest以将文件摄入矢量存储。python main.py retrieve以从矢量存储中检索数据。这将提示您提出问题。使用--verbose标志获取有关该程序在幕后所做的事情的更多详细信息。
要重新启动数据,请删除vector_store文件夹并再次运行python main.py ingest 。
运行streamlit run app.py它将在浏览器窗口中打开应用程序。
该命令可能会失败,第一次运行它。 Python环境与Pyenv一起工作的地方有一个小故障。如果简化显示“无法导入模块消息”,请停用Python环境,然后deactivate其再次激活,并使用source venv/bin/activate激活,然后运行streamlit run app.py
如果您还没有这样做,请准备环境。如果您已经准备好环境,请用source venv/bin/activate激活它。
命令: python main.py ingest [--verbose]
此阶段的目的是使数据可搜索。但是,用户的问题和数据内容可能不完全匹配。因此,我们不能使用简单的搜索引擎。我们需要执行矢量嵌入支持的相似性搜索。向量嵌入是此阶段最重要的部分。
摄入数据具有以下步骤:
未来的改进:
NLTKTextSplitter或SpacyTextSplitter )是否会改善答案。 如果您还没有这样做,请准备环境。如果您已经准备好环境,请用source venv/bin/activate激活它。
命令: python main.py retrieve [--verbose]
此阶段的目的是从本地数据中检索信息。我们通过获取矢量商店中最相关的块并将其与用户的问题和提示相结合来做到这一点。该提示指示语言模型(LLM)回答问题。
检索数据具有以下步骤:
未来的改进:
我们必须做出一些妥协才能使其在合理的时间内在本地机器上运行。
大多数摄入/检索代码基于原始私人法,他们现在称为原始代码。
有什么不同:
pathlib而不是os.path ,并且具有正确的日志记录代替打印语句。--verbose标志查看详细信息。requirements.txt 。有关在此项目开发期间收集的更多注释,请参见此文件。
这是一个一次性步骤。如果您已经这样做了,只需使用source venv/bin/activate激活虚拟环境。
运行以下命令以创建虚拟环境并安装所需的软件包。
python3 -m venv venv
source venv/bin/activate
pip install --upgrade pip
pip install -r requirements.txtunstructured中的PDF解析器是实际解析器软件包顶部的一层。在“安装以下系统依赖项”子弹下,按照unstructured读数中的说明进行操作。需要流行式包装和Tesseract软件包(忽略其他软件包)。
我建议从在CPU上运行的小型型号开始。 GPT4All在这里有模型列表。我用Mistral-7b-Openorca Q4进行了测试。它需要8 GB的RAM运行。请注意,某些模型具有限制性许可。在商业项目中使用许可之前,请先检查许可证。
models的文件夹。models文件夹。

