gpt all local
1.0.0
Proyek ini adalah latihan pembelajaran tentang penggunaan model bahasa besar (LLM) untuk mengambil informasi dari data pribadi, menjalankan semua bagian (termasuk model) secara lokal. Tujuannya adalah untuk menjalankan LLM di komputer Anda untuk mengajukan pertanyaan pada satu set file juga di komputer Anda. File dapat berupa semua jenis dokumen, seperti PDF, Word, atau file teks.
Metode menggabungkan LLM dan data pribadi ini dikenal sebagai Retrieval-Augmented Generation (RAG). Itu diperkenalkan dalam makalah ini.
Kredit di mana kredit jatuh tempo: Saya mendasarkan proyek ini pada privategpt asli (apa yang sekarang mereka sebut versi primordial ). Saya mengimplementasikan kembali potongan -potongan untuk memahami cara kerjanya. Lihat lebih banyak di bagian Sumber.
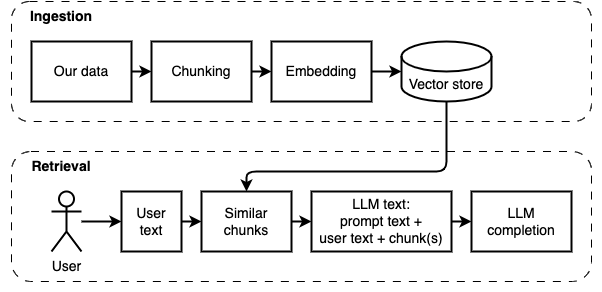
Apa yang kami coba capai: Diberikan satu set file di komputer (a), kami menginginkan model bahasa besar (b) berjalan di komputer itu untuk menjawab pertanyaan (c) pada mereka.
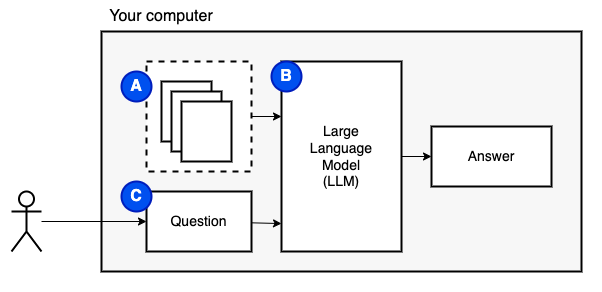
Namun, kami tidak dapat memberi makan file secara langsung ke model. Model Bahasa Besar (LLM) memiliki jendela konteks yang membatasi seberapa banyak informasi yang dapat kita masukkan ke dalamnya (memori kerja mereka). Untuk mengatasi batasan itu, kami membagi file menjadi potongan -potongan kecil, disebut potongan , dan hanya memberi makan yang relevan dengan model (D).
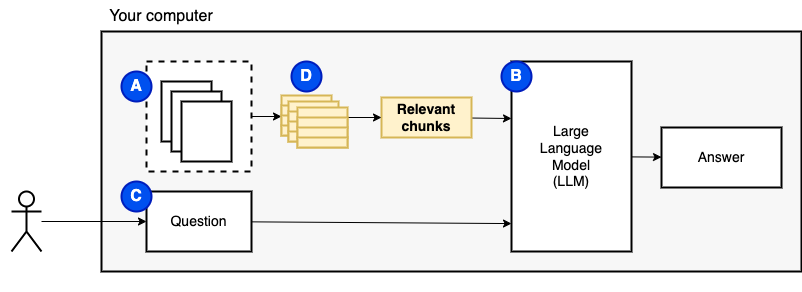
Tapi kemudian, pertanyaannya menjadi "bagaimana kita menemukan potongan yang relevan?" . Kami menggunakan Pencarian Kesamaan (E) untuk mencocokkan pertanyaan dan potongan. Pencarian kesamaan, pada gilirannya, membutuhkan embeddings vektor (F), representasi kata-kata dengan vektor yang mengkode hubungan semantik (secara teknis, vektor yang padat , tidak mengacaukannya dengan representasi vektor yang jarang seperti tas-word dan TF-IDF). Setelah kami memiliki potongan yang relevan, kami menggabungkannya dengan pertanyaan untuk membuat prompt (g) yang menginstruksikan LLM untuk menjawab pertanyaan.
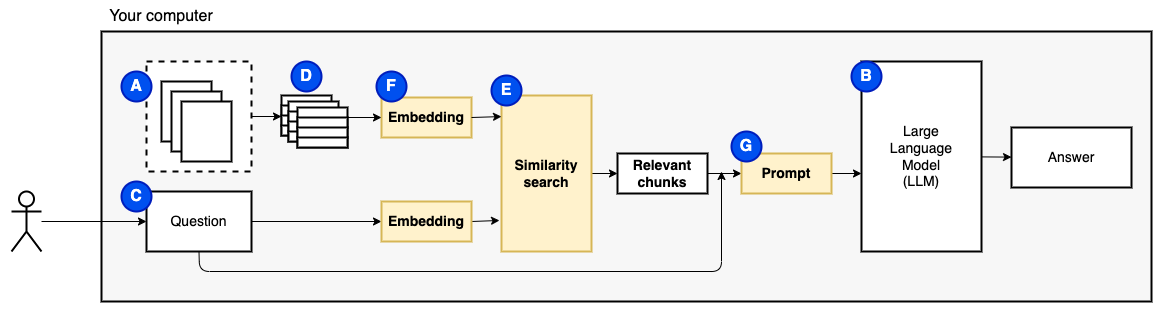
Kami membutuhkan satu bagian terakhir: penyimpanan persisten. Membuat embeddings untuk potongan membutuhkan waktu. Kami tidak ingin melakukan itu setiap kali kami mengajukan pertanyaan. Oleh karena itu, kita perlu menyimpan embeddings dan teks asli (potongan) di toko vektor (atau database) (h). Toko vektor dapat tumbuh besar karena menyimpan potongan teks asli dan embeddings vektornya. Kami menggunakan indeks vektor (i) untuk menemukan potongan yang relevan secara efisien.
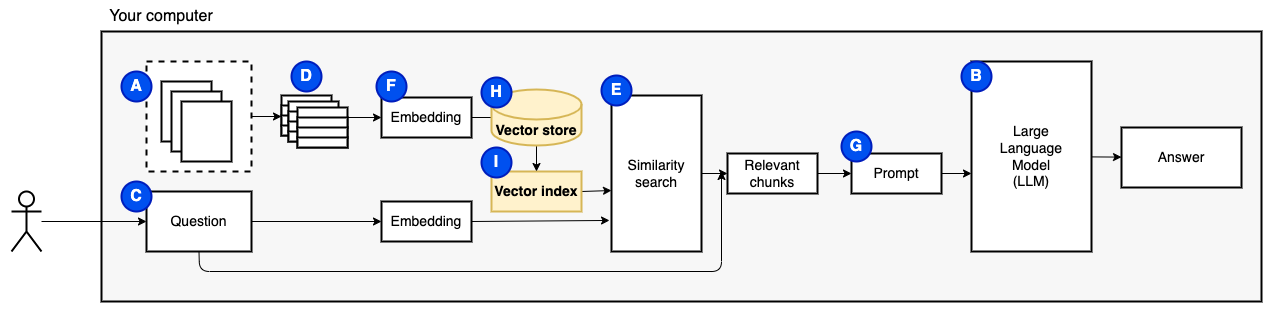
Sekarang kita memiliki semua bagian yang kita butuhkan.
Kami dapat membagi implementasi menjadi dua bagian: menelan dan mengambil data.
Kedua langkah ini diilustrasikan dalam diagram berikut.
Jika Anda belum melakukannya, persiapkan lingkungan. Jika Anda telah menyiapkan lingkungan, aktifkan dengan source venv/bin/activate .
Ada dua cara untuk menggunakan proyek ini:
--verbose di bawah).data .python main.py ingest untuk menelan file ke toko vektor.python main.py retrieve untuk mengambil data dari toko vektor. Ini akan meminta Anda untuk mendapatkan pertanyaan. Gunakan bendera --verbose untuk mendapatkan lebih banyak detail tentang apa yang dilakukan program di belakang layar.
Untuk memesan kembali data, hapus folder vector_store dan jalankan python main.py ingest lagi.
Jalankan streamlit run app.py Ini akan membuka aplikasi di jendela browser.
Perintah ini mungkin gagal yang pertama Anda jalankan. Ada kesalahan di suatu tempat dalam bagaimana lingkungan Python bekerja bersama dengan pyenv. Jika StreamLit menunjukkan "tidak dapat mengimpor pesan modul", nonaktifkan lingkungan Python dengan deactivate , aktifkan lagi dengan source venv/bin/activate , dan jalankan streamlit run app.py
Jika Anda belum melakukannya, persiapkan lingkungan. Jika Anda telah menyiapkan lingkungan, aktifkan dengan source venv/bin/activate .
Perintah: python main.py ingest [--verbose]
Tujuan dari tahap ini adalah untuk membuat data dapat dicari. Namun, pertanyaan pengguna dan konten data mungkin tidak cocok. Karena itu, kami tidak dapat menggunakan mesin pencari sederhana. Kita perlu melakukan pencarian kesamaan yang didukung oleh embeddings vektor. Penataran vektor adalah bagian terpenting dari tahap ini.
Mengonsumsi data memiliki langkah -langkah berikut:
Perbaikan di masa depan:
NLTKTextSplitter atau SpacyTextSplitter ) tingkatkan jawabannya. Jika Anda belum melakukannya, persiapkan lingkungan. Jika Anda telah menyiapkan lingkungan, aktifkan dengan source venv/bin/activate .
Perintah: python main.py retrieve [--verbose]
Tujuan dari tahap ini adalah untuk mengambil informasi dari data lokal. Kami melakukannya dengan mengambil potongan yang paling relevan dari toko vektor dan menggabungkannya dengan pertanyaan pengguna dan prompt. Prompt menginstruksikan model bahasa (LLM) untuk menjawab pertanyaan.
Pengambilan data memiliki langkah -langkah berikut:
Perbaikan di masa depan:
Kami harus membuat beberapa kompromi untuk membuatnya berjalan pada mesin lokal dalam waktu yang wajar.
Sebagian besar kode konsumsi/retrieve didasarkan pada privategrt asli, yang mereka sebut sekarang primordial .
Apa yang berbeda:
pathlib alih -alih os.path dan memiliki logging yang tepat alih -alih pernyataan cetak.--verbose untuk melihat detailnya.requirements.txt dengan dependensi tidak langsung, misalnya, untuk transformator huggingface dan loader dokumen Langchain.Lihat file ini untuk lebih banyak catatan yang dikumpulkan selama pengembangan proyek ini.
Ini adalah langkah satu kali. Jika Anda telah melakukan ini, cukup aktifkan lingkungan virtual dengan source venv/bin/activate .
Jalankan perintah berikut untuk membuat lingkungan virtual dan menginstal paket yang diperlukan.
python3 -m venv venv
source venv/bin/activate
pip install --upgrade pip
pip install -r requirements.txt PDF parser di unstructured adalah lapisan di atas paket parser yang sebenarnya. Ikuti instruksi dalam peluru readme unstructured , di bawah peluru "instal sistem dependensi berikut". Paket poppler dan tesseract diperlukan (abaikan yang lain).
Saya sarankan mulai dengan model kecil yang berjalan di CPU. GPT4ALL memiliki daftar model di sini. Saya diuji dengan Mistral-7b-Openorca Q4. Ini membutuhkan 8 GB RAM untuk dijalankan. Perhatikan bahwa beberapa model memiliki lisensi yang membatasi. Periksa lisensi sebelum menggunakannya dalam proyek komersial.
models bernama folder.models .

