gpt all local
1.0.0
Dieses Projekt ist eine Lernübung zur Verwendung von LLM -Modellen (Language Language Models), um Informationen aus privaten Daten abzurufen und alle Teile (einschließlich des Modells) lokal auszuführen. Ziel ist es, einen LLM auf Ihrem Computer auszuführen, um Fragen auf einer Reihe von Dateien auch auf Ihrem Computer zu stellen. Die Dateien können eine beliebige Art von Dokument sein, wie z. B. PDF-, Word- oder Textdateien.
Diese Methode zur Kombination von LLMs und privaten Daten wird als RAG ( ARRAVEAL-AUGmented Generationed Generation ) bezeichnet. Es wurde in diesem Artikel eingeführt.
Gutschrift, wo Kredit fällig ist: Ich habe dieses Projekt auf dem ursprünglichen privaten GPT gestützt (was sie jetzt die ursprüngliche Version nennen). Ich habe die Stücke neu implementiert, um zu verstehen, wie sie funktionieren. Weitere Informationen finden Sie im Abschnitt Quellen.
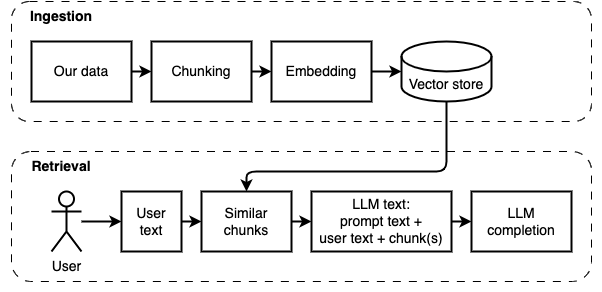
Was wir erreichen möchten: Wenn wir eine Reihe von Dateien auf einem Computer (a) angegeben haben, möchten wir, dass ein großes Sprachmodell (b) auf diesem Computer die Fragen (c) darauf beantwortet.
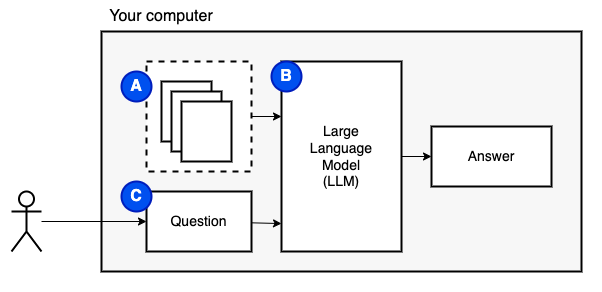
Wir können die Dateien jedoch nicht direkt an das Modell füttern. Große Sprachmodelle (LLMs) haben ein Kontextfenster, in dem die Informationen, die wir in sie einfügen können, einschränkt (ihr Arbeitsgedächtnis). Um diese Einschränkung zu überwinden, teilen wir die Dateien in kleinere Stücke auf, die als Stücke bezeichnet werden, und füttern nur die relevanten dem Modell (d).
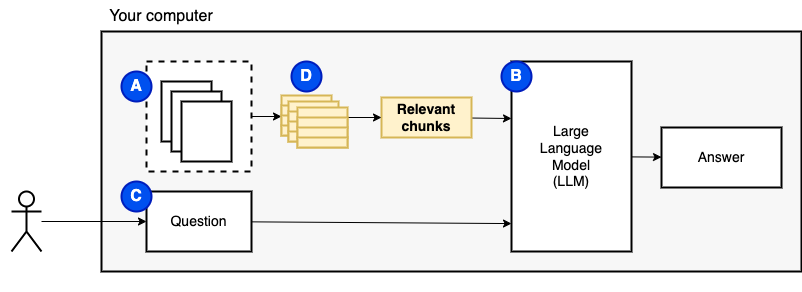
Aber dann lautet die Frage: "Wie finden wir die relevanten Brocken?" . Wir verwenden Ähnlichkeitssuche (e), um die Frage und die Stücke zu entsprechen. Die Ähnlichkeitssuche erfordert wiederum Vektoreinbettungen (f), eine Darstellung von Wörtern mit Vektoren, die semantische Beziehungen codieren (technisch gesehen ein dichtes Vektor-Einbettung, um sie nicht mit spärlichen Vektordarstellungen wie Wörtern und TF-IDF zu verwechseln). Sobald wir die relevanten Brocken haben, kombinieren wir sie mit der Frage, um eine Eingabeaufforderung (g) zu erstellen, die die LLM anweist, die Frage zu beantworten.
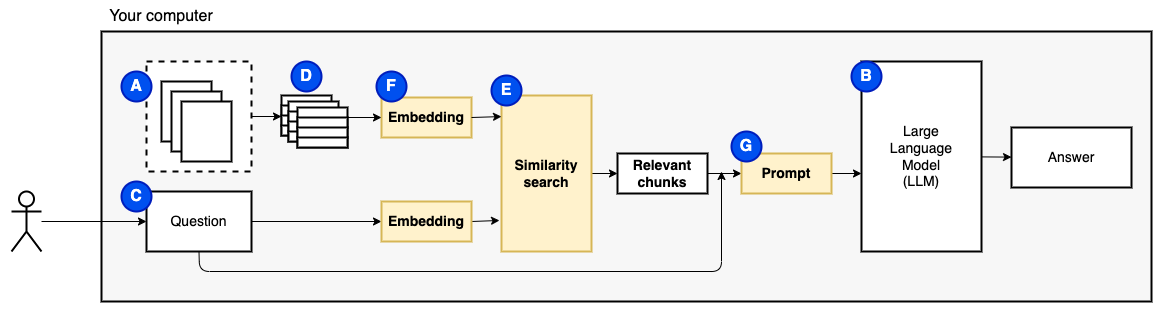
Wir brauchen ein letztes Stück: anhaltender Speicher. Das Erstellen von Einbettungen für die Stücke braucht Zeit. Wir wollen das nicht jedes Mal tun, wenn wir eine Frage stellen. Daher müssen wir die Einbettungen und den Originaltext (die Stücke) in einem Vektorspeicher (oder Datenbank) (H) speichern. Der Vektor Store kann groß werden, da er die ursprünglichen Textbrocken und ihre Vektor -Einbettungen speichert. Wir verwenden einen Vektorindex (i), um relevante Brocken effizient zu finden.
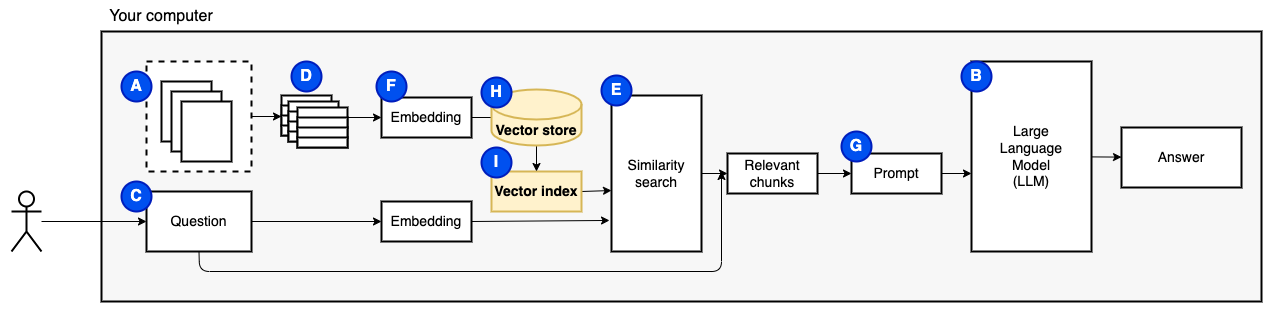
Jetzt haben wir alle Teile, die wir brauchen.
Wir können die Implementierung in zwei Teile unterteilen: Daten aufnehmen und abrufen.
Diese beiden Schritte sind im folgenden Diagramm dargestellt.
Wenn Sie dies noch nicht getan haben, bereiten Sie die Umgebung vor. Wenn Sie die Umgebung bereits vorbereitet haben, aktivieren Sie sie mit source venv/bin/activate .
Es gibt zwei Möglichkeiten, dieses Projekt zu verwenden:
--verbose unten).data .python main.py ingest um die Dateien in den Vektorspeicher aufzunehmen.python main.py retrieve , um Daten aus dem Vektorspeicher abzurufen. Es wird Sie für eine Frage auffordern. Verwenden Sie das Flag --verbose , um weitere Details darüber zu erhalten, was das Programm hinter den Kulissen tut.
Um die Daten neu zu starten, löschen Sie den Ordner vector_store und führen Sie python main.py ingest .
Führen Sie streamlit run app.py aus. Es wird die App in einem Browserfenster geöffnet.
Dieser Befehl kann möglicherweise nicht ausführen, wenn Sie ihn ausführen. Irgendwo ist irgendwo in der Python -Umgebung mit Pyenv zusammengearbeitet. Wenn Streamlit eine "Meldung von Modul nicht importieren kann", deaktivieren Sie die Python -Umgebung mit deactivate , aktivieren Sie sie erneut mit source venv/bin/activate und führen Sie streamlit run app.py aus.
Wenn Sie dies noch nicht getan haben, bereiten Sie die Umgebung vor. Wenn Sie die Umgebung bereits vorbereitet haben, aktivieren Sie sie mit source venv/bin/activate .
Befehl: python main.py ingest [--verbose]
Das Ziel dieser Phase ist es, die Daten durchsuchbar zu machen. Die Frage des Benutzers und der Dateninhalt stimmen jedoch möglicherweise nicht genau überein. Daher können wir keine einfache Suchmaschine verwenden. Wir müssen eine Ähnlichkeitssuche durchführen, die von Vektoreinbettungen unterstützt wird. Die Vektoreinbettung ist der wichtigste Teil dieser Phase.
Die Einnahme von Daten hat die folgenden Schritte:
Zukünftige Verbesserungen:
NLTKTextSplitter oder SpacyTextSplitter ) die Antworten verbessern. Wenn Sie dies noch nicht getan haben, bereiten Sie die Umgebung vor. Wenn Sie die Umgebung bereits vorbereitet haben, aktivieren Sie sie mit source venv/bin/activate .
Befehl: python main.py retrieve [--verbose]
Ziel dieser Phase ist es, Informationen aus den lokalen Daten abzurufen. Wir tun dies, indem wir die relevantesten Brocken aus dem Vektorspeicher abrufen und diese mit der Frage des Benutzers und einer Eingabeaufforderung kombinieren. Die Eingabeaufforderung weist das Sprachmodell (LLM) an, die Frage zu beantworten.
Das Abrufen von Daten hat die folgenden Schritte:
Zukünftige Verbesserungen:
Wir mussten einige Kompromisse eingehen, damit es in angemessener Zeit auf einer lokalen Maschine läuft.
Der größte Teil des Codes für Einnahme/Abruf basiert auf dem ursprünglichen privaten GPT, dem, den sie jetzt als ursprünglich bezeichnen.
Was ist anders:
pathlib anstelle von os.path und verfügt über eine ordnungsgemäße Protokollierung anstelle von Druckanweisungen.--verbose , um die Details anzuzeigen.requirements.txt .Weitere Informationen finden Sie in dieser Datei, die während der Entwicklung dieses Projekts gesammelt wurden.
Dies ist ein einmaliger Schritt. Wenn Sie dies bereits getan haben, aktivieren Sie einfach die virtuelle Umgebung mit source venv/bin/activate .
Führen Sie die folgenden Befehle aus, um eine virtuelle Umgebung zu erstellen und die erforderlichen Pakete zu installieren.
python3 -m venv venv
source venv/bin/activate
pip install --upgrade pip
pip install -r requirements.txt Der PDF -Parser in unstructured ist eine Ebene über den tatsächlichen Parserpaketen. Befolgen Sie die Anweisungen in der unstructured Readme unter den Kugeln "Die folgenden Systemabhängigkeiten installieren". Die Poppler- und Tesseract -Pakete sind erforderlich (ignorieren Sie die anderen).
Ich schlage vor, mit einem kleinen Modell zu beginnen, das auf der CPU ausgeführt wird. GPT4ALL hat hier eine Liste von Modellen. Ich habe mit Mistral-7b-Openorca Q4 getestet. Es erfordert 8 GB RAM zum Ausführen. Beachten Sie, dass einige der Modelle restriktive Lizenzen haben. Überprüfen Sie die Lizenz, bevor Sie sie in kommerziellen Projekten verwenden.
models .models .

