gpt all local
1.0.0
โครงการนี้เป็นแบบฝึกหัดการเรียนรู้เกี่ยวกับการใช้แบบจำลองภาษาขนาดใหญ่ (LLMS) เพื่อดึงข้อมูลจากข้อมูลส่วนตัวเรียกใช้ทุกชิ้น (รวมถึงรุ่น) ในเครื่อง เป้าหมายคือการเรียกใช้ LLM บนคอมพิวเตอร์ของคุณเพื่อถามคำถามเกี่ยวกับชุดไฟล์ในคอมพิวเตอร์ของคุณด้วย ไฟล์สามารถเป็นเอกสารประเภทใดก็ได้เช่น PDF, Word หรือไฟล์ข้อความ
วิธีการรวม LLMs และข้อมูลส่วนตัวนี้เรียกว่า Generation Retrieval-Augmented Generation (RAG) มันถูกนำมาใช้ในบทความนี้
เครดิตที่เครดิตครบกำหนด: ฉันใช้โครงการนี้ใน Privatept ดั้งเดิม (สิ่งที่พวกเขาเรียกว่าเวอร์ชัน Primordial ) ฉันเปิดใช้งานชิ้นส่วนใหม่เพื่อทำความเข้าใจว่าพวกเขาทำงานอย่างไร ดูเพิ่มเติมในส่วนแหล่งที่มา
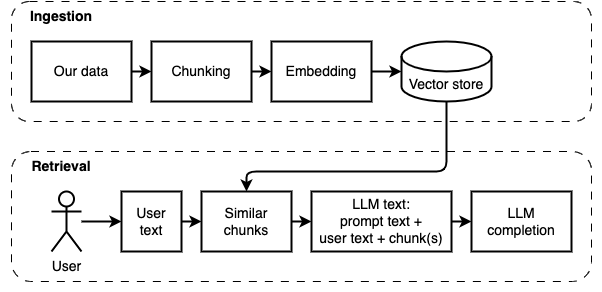
สิ่งที่เราพยายามที่จะบรรลุ: ให้ชุดไฟล์บนคอมพิวเตอร์ (a) เราต้องการรูปแบบภาษาขนาดใหญ่ (b) ที่ทำงานบนคอมพิวเตอร์เครื่องนั้นเพื่อตอบคำถาม (c)
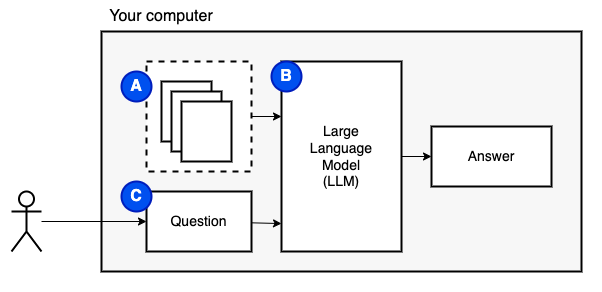
อย่างไรก็ตามเราไม่สามารถป้อนไฟล์ไปยังโมเดลได้โดยตรง โมเดลภาษาขนาดใหญ่ (LLMS) มีหน้าต่างบริบทที่ จำกัด จำนวนข้อมูลที่เราสามารถป้อนเข้ามาได้ (หน่วยความจำในการทำงาน) เพื่อเอาชนะข้อ จำกัด นั้นเราแบ่งไฟล์ออกเป็นชิ้นเล็ก ๆ เรียกว่า ชิ้น และป้อนเฉพาะไฟล์ที่เกี่ยวข้องกับโมเดล (D)
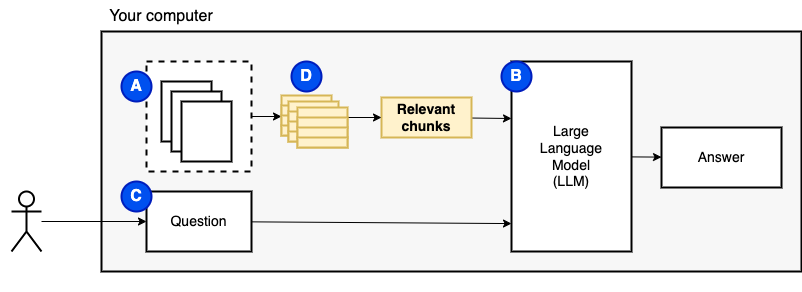
แต่แล้วคำถามก็กลายเป็น "เราจะหาชิ้นส่วนที่เกี่ยวข้องได้อย่างไร" - เราใช้การค้นหาความคล้ายคลึงกัน (E) เพื่อให้ตรงกับคำถามและชิ้นส่วน ในทางกลับกันการค้นหาความคล้ายคลึงกันนั้นต้องการการฝังเวกเตอร์ (F) ซึ่งเป็นตัวแทนของคำที่มีเวกเตอร์ที่เข้ารหัสความสัมพันธ์เชิงความหมาย (ในทางเทคนิคการฝังเวกเตอร์ หนาแน่น ไม่ทำให้สับสน เมื่อเรามีชิ้นที่เกี่ยวข้องเราจะรวมพวกเขาเข้ากับคำถามเพื่อสร้างพรอมต์ (g) ที่สั่งให้ LLM ตอบคำถาม
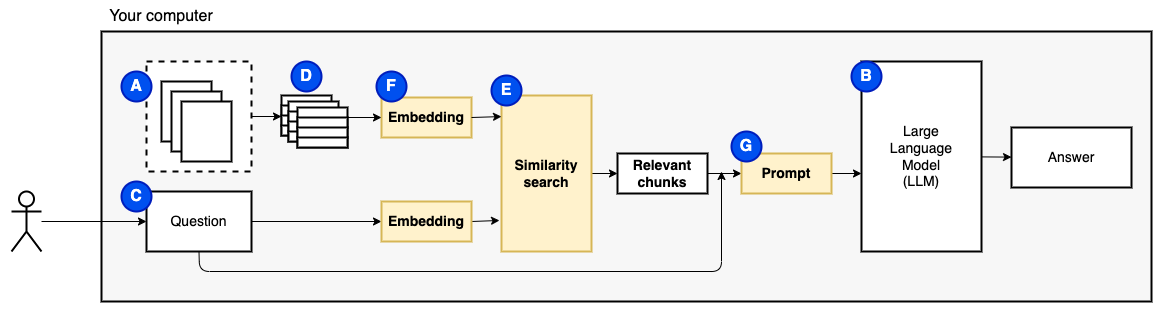
เราต้องการหนึ่งชิ้นสุดท้าย: ที่เก็บถาวร การสร้าง embeddings สำหรับชิ้นนั้นต้องใช้เวลา เราไม่อยากทำทุกครั้งที่ถามคำถาม ดังนั้นเราจำเป็นต้องบันทึก embeddings และข้อความต้นฉบับ (ชิ้น) ในร้านค้าเวกเตอร์ (หรือฐานข้อมูล) (h) ร้านค้าเวกเตอร์สามารถเติบโตได้มากเพราะเก็บชิ้นข้อความต้นฉบับและการฝังเวกเตอร์ของพวกเขา เราใช้ดัชนีเวกเตอร์ (i) เพื่อค้นหาชิ้นที่เกี่ยวข้องอย่างมีประสิทธิภาพ
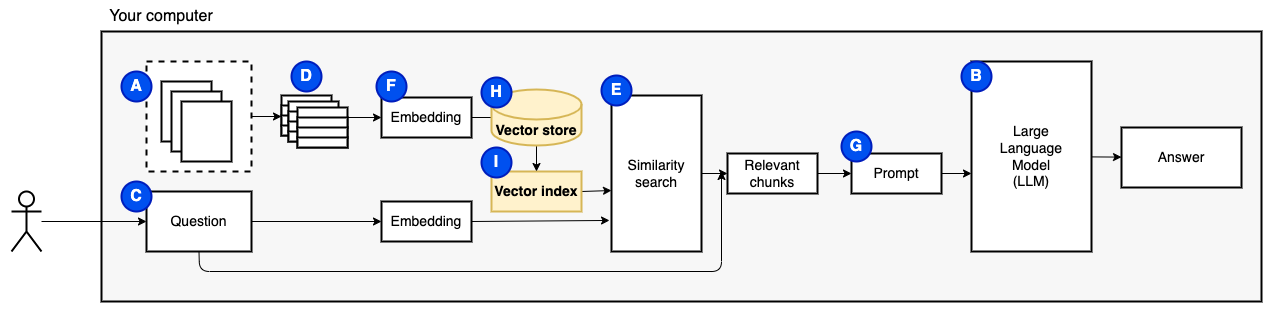
ตอนนี้เรามีทุกชิ้นที่เราต้องการ
เราสามารถแบ่งการใช้งานออกเป็นสองส่วน: การบริโภคและดึงข้อมูล
สองขั้นตอนนี้แสดงในแผนภาพต่อไปนี้
หากคุณยังไม่ได้ทำให้เตรียมสภาพแวดล้อม หากคุณได้เตรียมสภาพแวดล้อมแล้วให้เปิดใช้งานด้วย source venv/bin/activate
มีสองวิธีในการใช้โครงการนี้:
--verbose ด้านล่าง)datapython main.py ingest เพื่อเข้าไปในไฟล์เข้าไปในร้านค้าเวกเตอร์python main.py retrieve เพื่อดึงข้อมูลจากร้านค้าเวกเตอร์ มันจะแจ้งให้คุณทราบ ใช้ธง --verbose เพื่อรับรายละเอียดเพิ่มเติมเกี่ยวกับสิ่งที่โปรแกรมกำลังทำอยู่เบื้องหลัง
ในการรับข้อมูลอีกครั้งให้ลบโฟลเดอร์ vector_store และเรียกใช้ python main.py ingest อีกครั้ง
เรียกใช้ streamlit run app.py มันจะเปิดแอพในหน้าต่างเบราว์เซอร์
คำสั่งนี้อาจล้มเหลวครั้งแรกที่คุณเรียกใช้ มีความผิดพลาดอยู่ที่ไหนสักแห่งในการทำงานของ Python Environment กับ Pyenv หาก Streamlit แสดง "ไม่สามารถนำเข้าข้อความโมดูล" ให้ปิดการใช้งานสภาพแวดล้อม Python ด้วย deactivate ให้เปิดใช้งานอีกครั้งด้วย source venv/bin/activate และเรียกใช้ streamlit run app.py
หากคุณยังไม่ได้ทำให้เตรียมสภาพแวดล้อม หากคุณได้เตรียมสภาพแวดล้อมแล้วให้เปิดใช้งานด้วย source venv/bin/activate
คำสั่ง: python main.py ingest [--verbose]
เป้าหมายของขั้นตอนนี้คือการทำให้ข้อมูลค้นหาได้ อย่างไรก็ตามคำถามของผู้ใช้และเนื้อหาข้อมูลอาจไม่ตรงกัน ดังนั้นเราไม่สามารถใช้เครื่องมือค้นหาง่ายๆ เราจำเป็นต้องทำการค้นหาความคล้ายคลึงกันที่สนับสนุนโดย Vector Embeddings การฝังเวกเตอร์เป็นส่วนที่สำคัญที่สุดของขั้นตอนนี้
การกลืนข้อมูลมีขั้นตอนต่อไปนี้:
การปรับปรุงในอนาคต:
NLTKTextSplitter หรือ SpacyTextSplitter ) ปรับปรุงคำตอบ หากคุณยังไม่ได้ทำให้เตรียมสภาพแวดล้อม หากคุณได้เตรียมสภาพแวดล้อมแล้วให้เปิดใช้งานด้วย source venv/bin/activate
คำสั่ง: python main.py retrieve [--verbose]
เป้าหมายของขั้นตอนนี้คือการดึงข้อมูลจากข้อมูลท้องถิ่น เราทำเช่นนั้นโดยดึงชิ้นส่วนที่เกี่ยวข้องมากที่สุดจากร้านค้าเวกเตอร์และรวมเข้ากับคำถามของผู้ใช้และพรอมต์ พรอมต์สั่งรูปแบบภาษา (LLM) เพื่อตอบคำถาม
การดึงข้อมูลมีขั้นตอนต่อไปนี้:
การปรับปรุงในอนาคต:
เราต้องทำการประนีประนอมเพื่อให้มันทำงานบนเครื่องท้องถิ่นในระยะเวลาที่เหมาะสม
รหัส Ingest/Retrieve ส่วนใหญ่ขึ้นอยู่กับ Privatept ดั้งเดิมซึ่งเป็นรหัสที่พวกเขาเรียกว่าตอนนี้ Primordial
แตกต่างอะไร:
pathlib แทน os.path และมีการบันทึกที่เหมาะสมแทนคำสั่งพิมพ์--verbose เพื่อดูรายละเอียดrequirements.txt ด้วยการพึ่งพาทางอ้อมตัวอย่างเช่นสำหรับหม้อแปลง Huggingface และ langchain document loadersดูไฟล์นี้สำหรับบันทึกเพิ่มเติมที่รวบรวมระหว่างการพัฒนาโครงการนี้
นี่เป็นขั้นตอนเดียว หากคุณได้ทำสิ่งนี้ไปแล้วเพียงแค่เปิดใช้งานสภาพแวดล้อมเสมือนจริงด้วย source venv/bin/activate
เรียกใช้คำสั่งต่อไปนี้เพื่อสร้างสภาพแวดล้อมเสมือนจริงและติดตั้งแพ็คเกจที่ต้องการ
python3 -m venv venv
source venv/bin/activate
pip install --upgrade pip
pip install -r requirements.txt ตัวแยกวิเคราะห์ PDF ที่ unstructured เป็นเลเยอร์ที่ด้านบนของแพ็คเกจตัวแยกวิเคราะห์จริง ทำตามคำแนะนำใน readme unstructured ใต้กระสุน "ติดตั้งระบบต่อไปนี้" จำเป็นต้องใช้แพ็คเกจ Poppler และ Tesseract (ไม่สนใจอื่น ๆ )
ฉันขอแนะนำให้เริ่มต้นด้วยรุ่นเล็ก ๆ ที่ทำงานบน CPU GPT4ALL มีรายการรุ่นที่นี่ ฉันทดสอบกับ Mistral-7b-Openorca Q4 ต้องใช้ RAM 8 GB โปรดทราบว่าบางรุ่นมีใบอนุญาตที่เข้มงวด ตรวจสอบใบอนุญาตก่อนใช้งานในโครงการเชิงพาณิชย์
modelsmodels

