gpt all local
1.0.0
このプロジェクトは、大規模な言語モデル(LLM)を使用してプライベートデータから情報を取得し、すべてのピース(モデルを含む)をローカルで実行する学習演習です。目標は、コンピューターでLLMを実行して、コンピューター上のファイルのセットで質問をすることです。ファイルは、PDF、単語、テキストファイルなど、あらゆる種類のドキュメントを使用できます。
LLMSとプライベートデータを組み合わせるこの方法は、検索された生成(RAG)として知られています。この論文で紹介されました。
クレジットが期限になる場合はクレジット:私はこのプロジェクトを元のPrivategpt(現在は原始バージョンと呼んでいるもの)に基づいています。私はそれらがどのように機能するかを理解するためにピースを再装備しました。ソースセクションの詳細をご覧ください。
私たちが達成しようとしていること:コンピューター上のファイルのセット(a)を考えると、そのコンピューターで実行されている大規模な言語モデル(b)がそれらに関する質問(c)に答える必要があります。
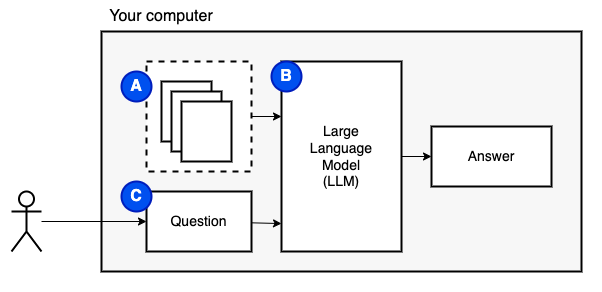
ただし、ファイルをモデルに直接送信することはできません。大規模な言語モデル(LLMS)には、それらにどの程度の情報を与えることができるか(ワーキングメモリ)を制限するコンテキストウィンドウがあります。その制限を克服するために、チャンクと呼ばれるファイルを小さな部分に分割し、関連するもののみをモデル(D)にフィードします。
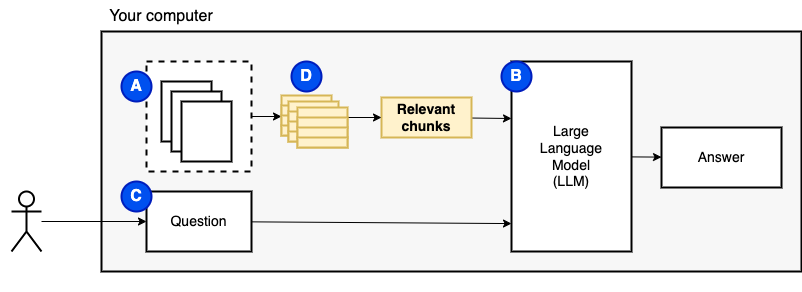
しかし、その後、質問は「関連するチャンクをどのように見つけるのですか?」になります。 。類似性検索(e)を使用して、質問とチャンクに一致します。類似性検索では、ベクトル埋め込み(f)、セマンティック関係をコードするベクトルを持つ単語の表現(技術的には、密なベクトル埋め込みで、ワード袋やTF-IDFなどのまばらなベクトル表現と混同しない)が必要です。関連するチャンクができたら、それらを質問と組み合わせて、LLMに質問に答えるように指示するプロンプト(g)を作成します。
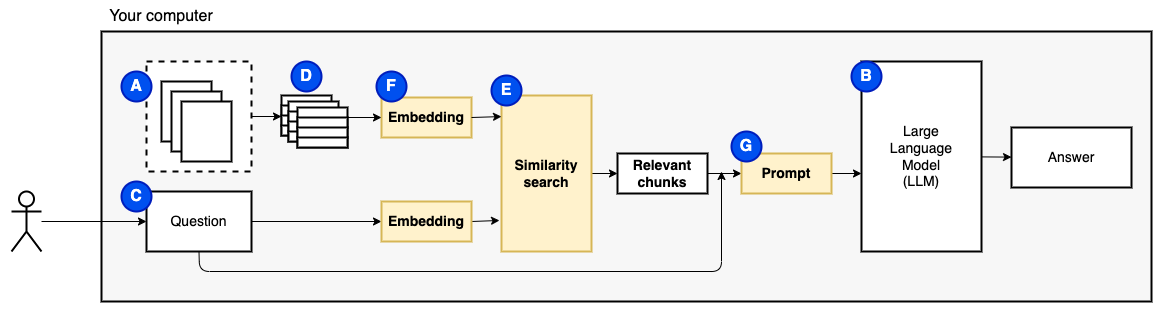
最後の作品が必要です:永続的なストレージ。チャンクの埋め込みを作成するには時間がかかります。質問するたびにそれをしたくありません。したがって、ベクトルストア(またはデータベース)(h)に埋め込みと元のテキスト(チャンク)を保存する必要があります。ベクトルストアは、元のテキストチャンクとそのベクトル埋め込みを保存するため、大きく成長する可能性があります。ベクトルインデックス(i)を使用して、関連するチャンクを効率的に見つけます。
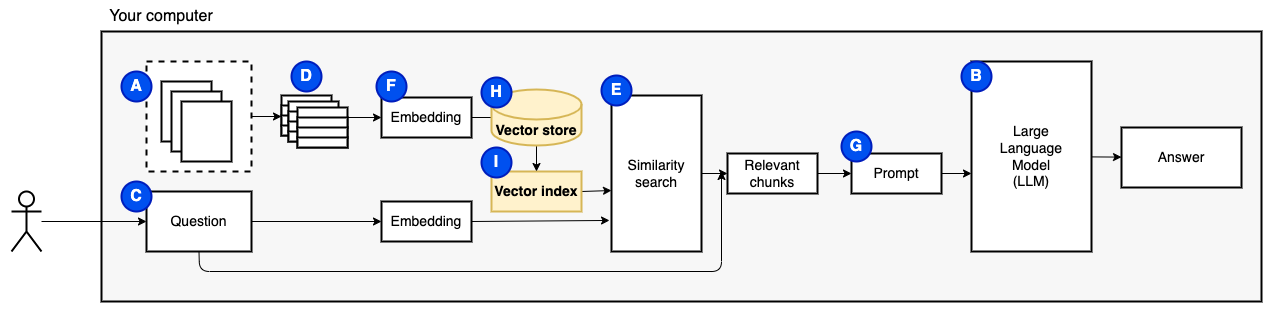
これで、必要なすべてのピースがあります。
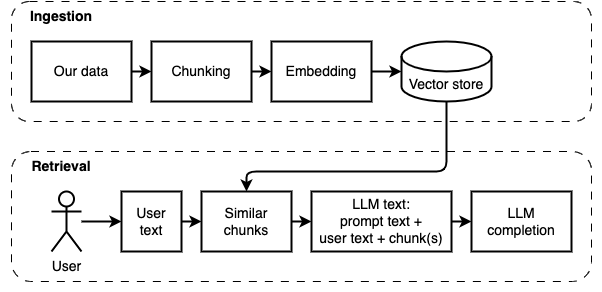
実装を2つの部分に分割できます:データの摂取と取得。
これらの2つの手順を次の図に示します。
まだ行っていない場合は、環境を準備してください。既に環境を準備している場合は、 source venv/bin/activateでアクティブにします。
このプロジェクトを使用するには2つの方法があります。
--verboseフラグを参照)。dataフォルダーにコピーします。python main.py ingestを実行して、ファイルをベクトルストアに摂取します。python main.py retrieveを実行して、Vectorストアからデータを取得します。質問を求めます。 --verboseフラグを使用して、プログラムが舞台裏で何をしているかについて詳細を確認します。
データを再検討するには、 vector_storeフォルダーを削除し、 python main.py ingestを再度実行します。
streamlit run app.pyを実行します。ブラウザウィンドウでアプリを開きます。
このコマンドは、最初に実行すると失敗する場合があります。 PynvとPyenvと一緒にどのように機能するかのどこかにグリッチがあります。 Riremlitが「モジュールメッセージをインポートできない」を表示する場合は、Python環境を無効にしてdeactivateにし、 source venv/bin/activateで再度アクティブにし、 streamlit run app.py実行します。
まだ行っていない場合は、環境を準備してください。既に環境を準備している場合は、 source venv/bin/activateでアクティブにします。
コマンド: python main.py ingest [--verbose]
この段階の目標は、データを検索可能にすることです。ただし、ユーザーの質問とデータの内容は正確に一致しない場合があります。したがって、単純な検索エンジンを使用することはできません。ベクトル埋め込みでサポートされている類似性検索を実行する必要があります。ベクトル埋め込みは、この段階の最も重要な部分です。
データの摂取には、次の手順があります。
将来の改善:
NLTKTextSplitterまたはSpacyTextSplitter )が回答を改善するかどうかを確認してください。 まだ行っていない場合は、環境を準備してください。既に環境を準備している場合は、 source venv/bin/activateでアクティブにします。
コマンド: python main.py retrieve [--verbose]
この段階の目標は、ローカルデータから情報を取得することです。ベクトルストアから最も関連性の高いチャンクを取得し、ユーザーの質問とプロンプトと組み合わせることで、それを行います。プロンプトは、言語モデル(LLM)に質問に答えるように指示します。
データを取得するには、次の手順があります。
将来の改善:
妥当な時間でローカルマシンで実行するために、いくつかの妥協をしなければなりませんでした。
INGEST/取得コードのほとんどは、元のprivategptに基づいています。
違うもの:
os.pathの代わりにpathlibを使用し、印刷ステートメントの代わりに適切なログを持っています。--verboseフラグを使用して詳細を確認します。requirements.txtを入力します。このプロジェクトの開発中に収集されたメモについては、このファイルを参照してください。
これは1回限りのステップです。すでにこれを行っている場合は、 source venv/bin/activateを使用して仮想環境を有効にしてください。
次のコマンドを実行して仮想環境を作成し、必要なパッケージをインストールします。
python3 -m venv venv
source venv/bin/activate
pip install --upgrade pip
pip install -r requirements.txtunstructuredたPDFパーサーは、実際のパーサーパッケージの上部にあるレイヤーです。 「次のシステム依存関係をインストールする」弾丸の下で、 unstructured READMEの指示に従ってください。ポップラーとテッセラクトパッケージが必要です(他のパッケージを無視します)。
CPUで実行される小さなモデルから始めることをお勧めします。 GPT4ALLには、ここにモデルのリストがあります。 Mistral-7B-Openorca Q4でテストしました。実行するには8 GBのRAMが必要です。一部のモデルには制限的なライセンスがあることに注意してください。商業プロジェクトで使用する前に、ライセンスを確認してください。
modelsという名前のフォルダーを作成します。modelsフォルダーにコピーします。

