sparseml
v1.8.0
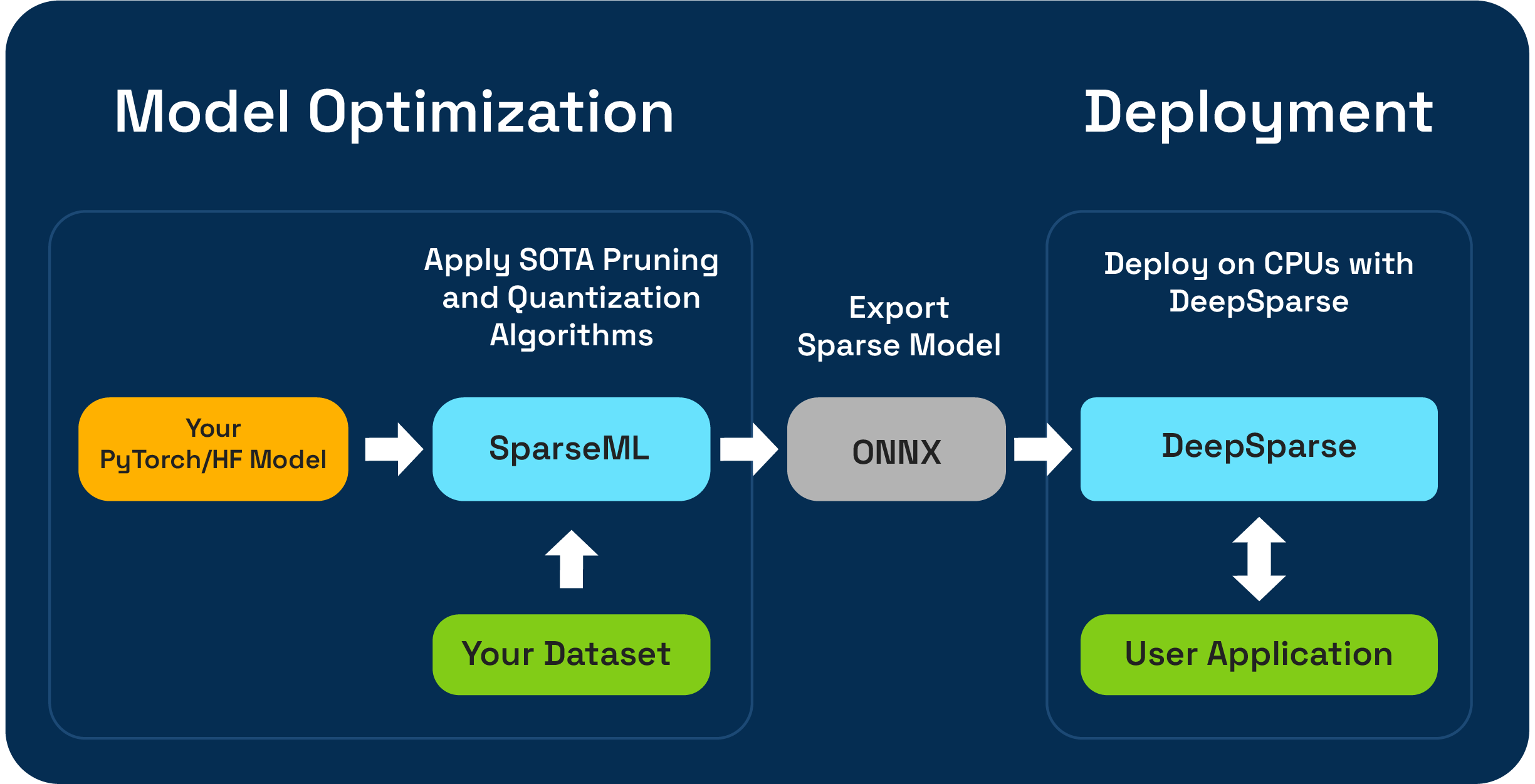
SPARSEML是一種開源模型優化工具包,使您可以使用修剪,量化和蒸餾算法創建推理優化的稀疏模型。然後可以將Sparseml優化的模型導出到ONNX,並使用DeepSparse部署,以在CPU硬件上進行GPU級性能。
神經魔術很高興能使用新的SparseGPTModfier預覽單發LLM壓縮工作流程!
要修剪和量化Tinyllama聊天模型,這只是安裝依賴項,下載食譜並將其應用於模型的幾個步驟:
git clone https://github.com/neuralmagic/sparseml
pip install -e "sparseml[transformers]"
wget https://huggingface.co/neuralmagic/TinyLlama-1.1B-Chat-v0.4-pruned50-quant-ds/raw/main/recipe.yaml
sparseml.transformers.text_generation.oneshot --model_name TinyLlama/TinyLlama-1.1B-Chat-v1.0 --dataset_name open_platypus --recipe recipe.yaml --output_dir ./obcq_deployment --precision float16
src/sparseml/transformers/sparsification/obcq的README具有詳細的演練。
Sparseml使您能夠以兩種方式在數據集上訓練的稀疏模型:
稀疏的傳輸學習使您可以從Sparsezoo(稀疏模型的開源存儲庫(例如Bert,Yolov5和Resnet-50)中的開源存儲庫微調預先放置的模型,同時保持稀疏性。這種途徑就像您在訓練簡歷和NLP型號中習慣的典型微調一樣工作,並且如果您的模型體系結構在Sparsezoo中可用,則非常喜歡。
從頭開始稀疏,您可以將最先進的修剪(例如逐步修剪或修剪)和量化(例如量化意識培訓)算法應用於任意的pytorch和擁抱的面部模型。該途徑需要更多的實驗,但允許您創建任何模型的稀疏版本。

該存儲庫在Python 3.8-3.11和Linux/Debian系統上進行了測試。
建議在虛擬環境中安裝以保持系統的順序。當前支持的ML框架如下: torch>=1.1.0,<=2.0 , tensorflow>=1.8.0,<2.0.0 , tensorflow.keras >= 2.2.0 。
使用PIP安裝:
pip install sparseml有關安裝的更多信息,例如可選依賴項和要求,請參見此處。
為了啟用靈活性,易用性和可重複性,Sparseml使用稱為recipes聲明界面來指定應由Sparseml應用的與稀疏性相關算法和超參數。
Recipes是YAML文件格式為modifiers列表,該列表編碼Sparseml的指令。示例modifiers可以是從設置學習率到編碼逐漸修剪算法的超參數的任何東西。 Sparseml系統將recipes解析為每個框架的天然格式,並將修改應用於模型和訓練管道。
由於採用了陳述性,基於配方的方法,您可以在現有的Pytorch培訓管道中添加Sparseml。 ScheduleModifierManager類負責解析YAML recipes和覆蓋標準Pytorch模型和優化對象,並從配方中編碼稀疏算法的邏輯。調用manager.modify後,您可以像往常一樣使用模型和優化器,因為Sparseml抽象了稀疏算法的複雜性。
工作流如下所示:
model = Model () # model definition
optimizer = Optimizer () # optimizer definition
train_data = TrainData () # train data definition
batch_size = BATCH_SIZE # training batch size
steps_per_epoch = len ( train_data ) // batch_size
from sparseml . pytorch . optim import ScheduledModifierManager
manager = ScheduledModifierManager . from_yaml ( PATH_TO_RECIPE )
optimizer = manager . modify ( model , optimizer , steps_per_epoch )
# typical PyTorch training loop, using your model/optimizer as usual
manager . finalize ( model )Trainer一起使用Sparseml的詳細信息。除了代碼級API外,Sparseml還通過CLI接口為常見的NLP和CV任務提供了預製的培訓管道。 CLI使您可以通過各種公用事業(例如數據集加載和預處理,保存檢查點保存,度量報告以及為您處理的日誌記錄)進行啟動培訓。這使得在通用訓練途徑中啟動和運行變得容易。
例如,我們可以使用以下啟動Yolov5稀疏傳輸學習運行到VOC數據集(使用Sparsezoo Stubs拉下稀疏模型檢查點並轉移學習食譜):
sparseml.yolov5.train
--weights zoo:cv/detection/yolov5-s/pytorch/ultralytics/coco/pruned75_quant-none ? recipe_type=transfer_learn
--recipe zoo:cv/detection/yolov5-s/pytorch/ultralytics/coco/pruned75_quant-none ? recipe_type=transfer_learn
--data VOC.yaml
--hyp hyps/hyp.finetune.yaml --cfg yolov5s.yaml --patience 0有關代碼庫和包含過程的更多信息,請參見Sparseml文檔:
官方版本在PYPI上託管
此外,可以通過GitHub釋放找到更多信息。
該項目是根據Apache許可證2.0版獲得許可的。
我們感謝對代碼,示例,集成和文檔以及錯誤報告和功能請求的貢獻!了解這裡的方式。
對於用戶幫助或有關Sparseml的問題,請註冊或登錄我們的神經魔術社區。我們正在成員成長,很高興見到您。錯誤,功能請求或其他問題也可以發佈到我們的GitHub問題隊列中。
您可以通過訂閱神經魔術社區來獲得最新的新聞,網絡研討會和活動邀請,研究論文以及其他ML性能。
有關神經魔術的更多一般性問題,請填寫此表格。
發現此項目在您的研究或其他溝通中有用嗎?請考慮引用:
@InProceedings {
pmlr-v119-kurtz20a,
title = { Inducing and Exploiting Activation Sparsity for Fast Inference on Deep Neural Networks } ,
author = { Kurtz, Mark and Kopinsky, Justin and Gelashvili, Rati and Matveev, Alexander and Carr, John and Goin, Michael and Leiserson, William and Moore, Sage and Nell, Bill and Shavit, Nir and Alistarh, Dan } ,
booktitle = { Proceedings of the 37th International Conference on Machine Learning } ,
pages = { 5533--5543 } ,
year = { 2020 } ,
editor = { Hal Daumé III and Aarti Singh } ,
volume = { 119 } ,
series = { Proceedings of Machine Learning Research } ,
address = { Virtual } ,
month = { 13--18 Jul } ,
publisher = { PMLR } ,
pdf = { http://proceedings.mlr.press/v119/kurtz20a/kurtz20a.pdf } ,
url = { http://proceedings.mlr.press/v119/kurtz20a.html } ,
abstract = {Optimizing convolutional neural networks for fast inference has recently become an extremely active area of research. One of the go-to solutions in this context is weight pruning, which aims to reduce computational and memory footprint by removing large subsets of the connections in a neural network. Surprisingly, much less attention has been given to exploiting sparsity in the activation maps, which tend to be naturally sparse in many settings thanks to the structure of rectified linear (ReLU) activation functions. In this paper, we present an in-depth analysis of methods for maximizing the sparsity of the activations in a trained neural network, and show that, when coupled with an efficient sparse-input convolution algorithm, we can leverage this sparsity for significant performance gains. To induce highly sparse activation maps without accuracy loss, we introduce a new regularization technique, coupled with a new threshold-based sparsification method based on a parameterized activation function called Forced-Activation-Threshold Rectified Linear Unit (FATReLU). We examine the impact of our methods on popular image classification models, showing that most architectures can adapt to significantly sparser activation maps without any accuracy loss. Our second contribution is showing that these these compression gains can be translated into inference speedups: we provide a new algorithm to enable fast convolution operations over networks with sparse activations, and show that it can enable significant speedups for end-to-end inference on a range of popular models on the large-scale ImageNet image classification task on modern Intel CPUs, with little or no retraining cost.}
} @misc {
singh2020woodfisher,
title = { WoodFisher: Efficient Second-Order Approximation for Neural Network Compression } ,
author = { Sidak Pal Singh and Dan Alistarh } ,
year = { 2020 } ,
eprint = { 2004.14340 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.LG }
}

