sparseml
v1.8.0
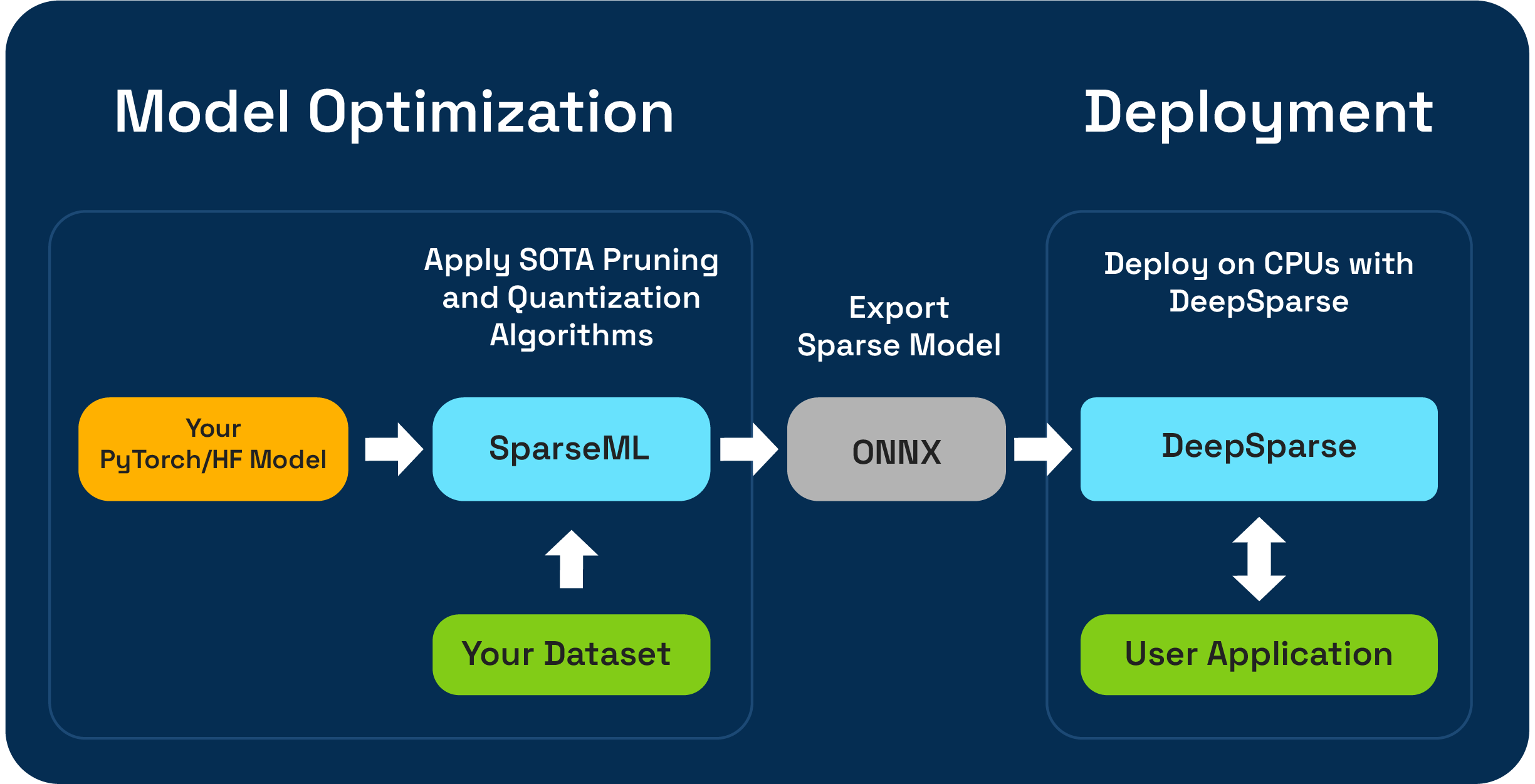
SPARSEML-это инструментарий для оптимизации модели с открытым исходным кодом, который позволяет вам создавать нептимизированные разрешенные модели с использованием обрезки, квантования и алгоритмов дистилляции. Модели, оптимизированные с помощью SparsEml, могут затем быть экспортированы в ONNX и развернуты с DeepSparse для производительности класса GPU на оборудовании процессора.
Нейронная магия взволнована для предварительного просмотра одноразовых рабочих процессов сжатия LLM, используя новый SparseGPTModfier !
Чтобы обрезать и квантовать модель чата Tinyllama. Это всего лишь несколько шагов для установки зависимостей, загрузки рецепта и применения ее к модели:
git clone https://github.com/neuralmagic/sparseml
pip install -e "sparseml[transformers]"
wget https://huggingface.co/neuralmagic/TinyLlama-1.1B-Chat-v0.4-pruned50-quant-ds/raw/main/recipe.yaml
sparseml.transformers.text_generation.oneshot --model_name TinyLlama/TinyLlama-1.1B-Chat-v1.0 --dataset_name open_platypus --recipe recipe.yaml --output_dir ./obcq_deployment --precision float16
Readme в src/sparseml/transformers/sparsification/obcq имеет подробное прохождение.
Sparseml позволяет вам создавать редкую модель, обученную наборе данных двумя способами:
Sparse Transfer Learning позволяет вам точно настроить предварительную модель от Sparsezoo (репозиторий с открытым исходным кодом редких моделей, таких как Bert, Yolov5 и Resnet-50), на ваш набор данных, сохраняя при этом разреженную. Этот путь работает так же, как типичная точная настройка, к которой вы привыкли к обучению моделей CV и NLP, и предпочтительнее, если ваша модельная архитектура доступна в Sparsezoo.
Ресторан с нуля позволяет применять современную обрезку (например, обрезку постепенной величины или обрезку OBS) и алгоритмы квантования (например, обучение квантованию) для произвольных моделей Pytorch и обнимающих лиц. Этот путь требует большего эксперимента, но позволяет вам создать редкую версию любой модели.

Этот репозиторий проверяется на Python 3.8-3.11 и Linux/Debian Systems.
Рекомендуется установить в виртуальной среде, чтобы ваша система в порядке. В настоящее время поддерживаемые ML -фреймворки являются следующими: torch>=1.1.0,<=2.0 , tensorflow>=1.8.0,<2.0.0 , tensorflow.keras >= 2.2.0 .
Установите с помощью PIP, используя:
pip install sparsemlБолее подробную информацию об установке, такой как дополнительные зависимости и требования, можно найти здесь.
Чтобы обеспечить гибкость, простоту использования и повторяемость, SparsEml использует декларативный интерфейс, называемый recipes для определения алгоритмов, связанных с редкостью, и гиперпараметров, которые должны применяться SparsEml.
Recipes -это файлы yaml, отформатированные как список modifiers , которые кодируют инструкции для Sparseml. Пример modifiers может быть чем угодно, от установки скорости обучения до кодирования гиперпараметров алгоритма обрезки постепенной величины. Sparseml System анализирует recipes в натуральный формат для каждой структуры и применяет модификации для модели и тренировочного трубопровода.
Из-за декларативного подхода, основанного на рецептах, вы можете добавить Sparseml в существующие тренировочные трубопроводы Pytorch. Класс ScheduleModifierManager отвечает за анализ recipes YAML и переоборудование стандартных объектов модели Pytorch и оптимизатора, кодируя логику алгоритмов разреженности из рецепта. После того, как вы вызовите manager.modify , вы можете использовать модель и оптимизатор, как обычно, так как Sparseml вычеркивает сложность алгоритмов спарсификации.
Рабочий процесс выглядит так:
model = Model () # model definition
optimizer = Optimizer () # optimizer definition
train_data = TrainData () # train data definition
batch_size = BATCH_SIZE # training batch size
steps_per_epoch = len ( train_data ) // batch_size
from sparseml . pytorch . optim import ScheduledModifierManager
manager = ScheduledModifierManager . from_yaml ( PATH_TO_RECIPE )
optimizer = manager . modify ( model , optimizer , steps_per_epoch )
# typical PyTorch training loop, using your model/optimizer as usual
manager . finalize ( model )Trainer об объятиях.В дополнение к API уровня кода Sparseml предлагает готовые тренировочные трубопроводы для общих задач NLP и CV через интерфейс CLI. CLI позволяет вам начать обучение с различными утилитами, такими как загрузка наборов данных и предварительная обработка, сохранение контрольной точки, отчеты о метрике и регистрация, обрабатываемые для вас. Это позволяет легко вставать и работать в общих тренировочных путях.
Например, мы можем использовать следующее для начала обучения Sparse Sparse Transfer Learning Yolov5.
sparseml.yolov5.train
--weights zoo:cv/detection/yolov5-s/pytorch/ultralytics/coco/pruned75_quant-none ? recipe_type=transfer_learn
--recipe zoo:cv/detection/yolov5-s/pytorch/ultralytics/coco/pruned75_quant-none ? recipe_type=transfer_learn
--data VOC.yaml
--hyp hyps/hyp.finetune.yaml --cfg yolov5s.yaml --patience 0Более подробную информацию о кодовой базе и содержащихся процессах можно найти в документах SparsEml:
Официальные сборки размещены на PYPI
Кроме того, дополнительную информацию можно найти с помощью выпусков GitHub.
Проект лицензирован в соответствии с версией лицензии Apache 2.0.
Мы ценим вклад в код, примеры, интеграции и документацию, а также отчеты об ошибках и запросы функций! Узнайте, как здесь.
Для помощи пользователя или вопросов о SparsEml зарегистрируйтесь или войдите в нашу нейронную магическую сообщество Slack . Мы выращиваем члена сообщества от члена и рады видеть вас там. Ошибки, запросы на функции или дополнительные вопросы также могут быть опубликованы в нашу очередь выпуска GitHub.
Вы можете получить последние новости, приглашения на вебинар и мероприятия, исследовательские работы и другие лакомые кусочки ML Performance, подписываясь на сообщество нейронной магии.
Для более общих вопросов о нейронной магии, пожалуйста, заполните эту форму.
Найти этот проект полезным в ваших исследованиях или других коммуникациях? Пожалуйста, рассмотрите возможность ссылаться на:
@InProceedings {
pmlr-v119-kurtz20a,
title = { Inducing and Exploiting Activation Sparsity for Fast Inference on Deep Neural Networks } ,
author = { Kurtz, Mark and Kopinsky, Justin and Gelashvili, Rati and Matveev, Alexander and Carr, John and Goin, Michael and Leiserson, William and Moore, Sage and Nell, Bill and Shavit, Nir and Alistarh, Dan } ,
booktitle = { Proceedings of the 37th International Conference on Machine Learning } ,
pages = { 5533--5543 } ,
year = { 2020 } ,
editor = { Hal Daumé III and Aarti Singh } ,
volume = { 119 } ,
series = { Proceedings of Machine Learning Research } ,
address = { Virtual } ,
month = { 13--18 Jul } ,
publisher = { PMLR } ,
pdf = { http://proceedings.mlr.press/v119/kurtz20a/kurtz20a.pdf } ,
url = { http://proceedings.mlr.press/v119/kurtz20a.html } ,
abstract = {Optimizing convolutional neural networks for fast inference has recently become an extremely active area of research. One of the go-to solutions in this context is weight pruning, which aims to reduce computational and memory footprint by removing large subsets of the connections in a neural network. Surprisingly, much less attention has been given to exploiting sparsity in the activation maps, which tend to be naturally sparse in many settings thanks to the structure of rectified linear (ReLU) activation functions. In this paper, we present an in-depth analysis of methods for maximizing the sparsity of the activations in a trained neural network, and show that, when coupled with an efficient sparse-input convolution algorithm, we can leverage this sparsity for significant performance gains. To induce highly sparse activation maps without accuracy loss, we introduce a new regularization technique, coupled with a new threshold-based sparsification method based on a parameterized activation function called Forced-Activation-Threshold Rectified Linear Unit (FATReLU). We examine the impact of our methods on popular image classification models, showing that most architectures can adapt to significantly sparser activation maps without any accuracy loss. Our second contribution is showing that these these compression gains can be translated into inference speedups: we provide a new algorithm to enable fast convolution operations over networks with sparse activations, and show that it can enable significant speedups for end-to-end inference on a range of popular models on the large-scale ImageNet image classification task on modern Intel CPUs, with little or no retraining cost.}
} @misc {
singh2020woodfisher,
title = { WoodFisher: Efficient Second-Order Approximation for Neural Network Compression } ,
author = { Sidak Pal Singh and Dan Alistarh } ,
year = { 2020 } ,
eprint = { 2004.14340 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.LG }
}

